

By early 2026, the global data extraction industry reached what many futurists called the “Era of Total Autonomy.” The rise of agentic AI and self-learning autonomous scrapers created a widespread corporate illusion: that human involvement in data gathering had become a relic of the past. Large-scale enterprises rushed to implement “zero-touch” solutions, promising instantaneous extraction of any data point from the global web without a single human click. However, beneath this veneer of technological triumph lies a critical structural flaw known as the “Human Accuracy Gap.”
In 2026, speed is no longer a competitive advantage; it is a commodity. In a world saturated with synthetic content, the real value lies in ontological truth. For data architects and e-commerce directors, it is becoming painfully clear that automation without human oversight is merely a high-speed generator of digital noise. This is where manual internet research has reclaimed its status as a premium quality standard. It is not merely “manual labor” in the traditional sense, but a form of cognitive verification that serves as the final line of defense against corrupted data pipelines.
The core of the problem is that AI models, regardless of their complexity, operate within probabilistic frameworks. They “predict” the correct answer based on statistical patterns found in training sets. Business decisions, however, require certainty, not probability. When multi-million dollar procurement contracts or global brand reputations are at stake, relying on the “best guess” of a neural network is a fiduciary risk. Consequently, a new market has emerged for expert-led services where human intelligence acts as the ultimate arbiter of fact.
The technological landscape of 2026 is dominated by “Agentic Workflows.” Unlike the rigid scrapers of the 2010s, modern AI agents can mimic human browsing behavior, solve basic navigational puzzles, and even interact with site elements to uncover hidden pricing. According to recent industry analysis from Gartner, over 70% of e-commerce data tasks are now initiated by some form of autonomous agent. These tools are undeniably powerful for broad-stroke data collection.
However, the proliferation of these agents has led to a “Tragedy of the Commons” in the data world. As bots crawl bots, the internet is becoming increasingly cluttered with “AI Slop” — low-quality, derivative content that feeds back into the scrapers’ learning loops. An autonomous scraper might successfully extract a product description, but it cannot verify if that description was hallucinated by another AI three months prior. This creates a recursive loop of inaccuracy that only manual internet research can break by grounding the data in physical or primary-source reality.
The “Human Accuracy Gap” is the measurable difference between the data an AI thinks is correct and the data that is actually true in a commercial context. For a director of product data management, this gap represents the margin of error that leads to customer churn, logistical failures, and lost revenue.
There are three primary reasons why speed fails to equate to reliability in 2026:
- Semantic fragility. AI agents often lack the “common sense” to realize when a data point is logically impossible. A bot might record a price of $0.01 for a luxury watch because of a site glitch, whereas a human researcher immediately recognizes a technical error.
- Temporal decay. Automated systems often pull from cached versions of sites or CDN edges to save on compute costs. In a volatile market, data that is even ten minutes old can be obsolete.
- Source fragmentation. As the web becomes more decentralized, finding the “Golden Record” for a product requires navigating unlinked silos. While automated data extraction follows links, humans follow intuition and experience.
In an economy of scale, quality becomes the ultimate differentiator. Forward-thinking companies are now pivoting toward a “Human-First, Machine-Assisted” architecture. This approach treats manual internet research not as a fallback for when technology fails, but as an elite verification layer.
This premium standard is defined by:
- Multi-vector verification. Checking a single SKU across official brand portals, authorized dealer networks, and secondary marketplaces to ensure consistency;
- Visual integrity. Using human eyes to perform SKU image matching to ensure that the physical product matches the technical specifications — a task where computer vision still frequently stumbles on minute reflections or packaging variations;
- Legal/ethical filtering. Ensuring that the e-commerce data research being conducted respects the evolving landscape of “Right to Repair” laws and specific regional digital privacy mandates.
For the modern e-commerce director, the goal is no longer just to “have data,” but to have “vetted intelligence.” The following chapters will explore why the most advanced algorithms still hit a “glass ceiling” when faced with the complexities of human-designed commerce.
The Limits of Automated Scrapers and AI Agents
While the marketing brochures of Silicon Valley startups in 2026 promise “seamless data harvesting,” the reality on the ground for a Data Architect is far more chaotic. The fundamental weakness of automated data extraction lies in its lack of sentience. An algorithm can follow a path, but it cannot understand the “why” behind the data it encounters. This lack of situational awareness creates a “brittleness” in automated systems that leads to catastrophic failures in large-scale product data management.
Context-Blindness: Why AI Struggles with Sarcasm, Cultural Nuances, and Regional Slang
The internet is a human creation, written by people for people. It is filled with linguistic traps that trip up even the most advanced Large Language Models (LLMs). When performing e-commerce data research, an automated agent might scan thousands of product reviews to determine sentiment or feature sets. However, it often fails to detect:
- Sarcasm and irony. A reviewer stated, “Oh sure, the battery lasts a whole ten minutes!” might be categorized as “Positive” by a bot that identifies “battery” and “ten minutes” as a feature match, whereas a human instantly recognizes a scathing complaint.
- Regional slang and idioms. In the UK, “quite good” often means “disappointing,” while in the US, it means “very good.” An AI agent lacks the localized cultural database to adjust its data weights accordingly.
- Visual metaphors. In competitor image research, a human can distinguish between a lifestyle image meant to convey an “aesthetic” and a technical photo meant to show “scale.” AI often conflates the two, leading to incorrect metadata tags in the product catalog.
This “Context-Blindness” results in “Dirty Data.” If a business leader bases a pricing strategy on sentiment analysis that missed the sarcasm in 20% of the reviews, the resulting strategy is built on a foundation of sand. Manual internet research acts as the linguistic filter, ensuring that the nuances of human communication are correctly translated into business intelligence.
Dynamic Barriers: How CAPTCHAs, IP-Blocking, and “Ghost” UIs Defeat Automation
The war between data harvesters and web administrators has escalated into a digital arms race. In 2026, many high-value e-commerce sites have implemented “Ghost UIs.” These are sophisticated front-end architectures that detect bot-like behavior and serve “decoy” data.
- Honey-pot pricing. A scraper might see a price of $49.99, while a human user on the same page sees $89.99. The site has identified the scraper and is feeding it false information to ruin the competitor’s analytics.
- Behavioral CAPTCHAs. Modern CAPTCHAs no longer just ask you to “click the fire hydrants.” They monitor mouse micro-movements and dwell times. AI agents, which move with mathematical precision, are easily flagged.
- Shadow-banning. An automated tool might think it is successfully performing internet research for product data, unaware that it has been redirected to a “sandbox” version of the site with outdated inventory.
Only a human researcher, behaving with the natural “randomness” of a biological user, can bypass these defenses reliably. The “Human Touch” is the only way to verify that the data being seen is the same data the customer sees.
The Risk of “AI Slop” and Synthetic Data Loops
Perhaps the greatest threat to data integrity in the late 2020s is the rise of “AI Slop.” As more companies use AI to generate product descriptions, blog posts, and technical specs, the internet is becoming a hall of mirrors.
When automated data extraction tools pull info from the web, they are increasingly likely to scrape content that was itself generated by an AI. This creates a “Synthetic Data Loop,” where errors are amplified in every generation. According to a study by Oxford University researchers, model collapse occurs when AI begins to learn from its own output rather than clean, human-generated data.
For a Director of E-commerce, this is a nightmare. If your product data management system is populated by AI-generated specs that were scraped from another AI-generated site, the “Ground Truth” is lost. Manual internet research is the only “Circuit Breaker” for this loop. A human expert can trace a fact back to its origin — a physical manual, a verified manufacturer’s press release, or a live product test — to ensure the data is “Organic,” not “Synthetic.”
Domains Where Human Accuracy is Non-Negotiable
While automation is excellent for “Broad and Shallow” tasks, “Deep and Specific” tasks still require a human brain. There are three specific domains where the failure of automation is not just an inconvenience, but a business liability.
Complex Source Verification: The Fight Against Counterfeits
In the world of high-end retail and industrial parts, distinguishing between a “Master Distributor” and a “High-Quality Counterfeit Site” is a task of extreme complexity. Automated scrapers look for keywords and SSL certificates. However, modern counterfeiters are experts at SEO and “Trust Signaling.”
A human performing manual internet research looks for the “Uncanny Valley” of e-commerce:
- Checking the registration history of the domain via WHOIS records.
- Analyzing the “Tone of Voice” in the legal disclaimers.
- Cross-referencing the “About Us” photos to see if they are stock images used on 500 other scam sites.
This level of scrutiny is vital for competitor image research. If a company accidentally benchmarks its prices against a counterfeit site, it devalues its own brand.
Ethical & Legal Judgment: Navigating GDPR and “Terms of Service” Gray Areas
In 2026, the legal landscape for e-commerce data research has become a minefield. It is no longer enough to simply “get the data”; one must get it legally and ethically. Automated scrapers are fundamentally “law-blind.” A bot does not understand the nuance of a website’s robots.txt file if that file is written in a non-standard format, nor does it understand the legal implications of scraping personal data protected by the updated EU GDPR (General Data Protection Regulation).
For a Data Architect, the risk of “Unlawful Data Acquisition” is a multi-million dollar liability.
- The “Intent” factor. Many modern Terms of Service (ToS) allow for “personal use” but forbid “commercial crawling.” An automated tool cannot distinguish between these two intents. A human performing manual internet research, however, can make a reasoned judgment call. They can identify when a data source requires a specific license or when a “fair use” doctrine applies.
- Privacy by design. When conducting internet research for product data, humans can instantly recognize and redact Personally Identifiable Information (PII) that an automated scraper might accidentally ingest. If a scraper pulls a customer review that contains a phone number or a home address, that data becomes a “toxic asset” in your product data management system.
- Contractual sensitivity. Often, pricing data is hidden behind “Click-Wrap” agreements. A bot clicking “I Agree” to a contract it cannot read creates a legal nightmare for the corporation. A human researcher understands that they cannot bypass certain digital gates without explicit authorization.
By employing manual internet research, companies build an “Ethical Firewall.” They ensure that their competitive intelligence is “clean,” defensible in court, and compliant with the increasingly strict global standards of data sovereignty.
Creative SKU Discovery: Finding “Hidden” Products via Deep Web Research for SKU
One of the greatest misconceptions in modern business is that “Google knows everything.” In reality, a vast portion of the commercial web — the “Deep Web” — is invisible to standard search engine crawlers and automated scrapers. This is the domain of Deep Web Research for SKU.
Automation fails in the Deep Web for several technical reasons:
- Non-indexed databases. Many manufacturers store their legacy parts, OEM specs, and wholesale price lists in databases that require specific query parameters. A bot cannot “guess” these parameters. A human, using deductive reasoning and industry knowledge, can find the “backdoor” to these catalogs.
- PDF and image-only catalogs. While OCR (Optical Character Recognition) has improved, many industrial SKUs are buried in 500-page scanned PDF catalogs or technical drawings. An AI might miss a part number because it’s rotated 45 degrees or partially obscured by a watermark. A human eye, performing visual data collection for AI, can identify these patterns with 100% accuracy.
- The “Hidden” SKU phenomenon. In luxury goods and specialized medical devices, SKUs are often not listed on public-facing pages. They are found in “hidden” directories or require navigating complex “Configurators” (e.g., choosing a color, then a size, then a material before the SKU appears). This multi-step logical progression is a “Bot-Killer.”
For a company trying to achieve total market visibility, manual internet research is the only way to map these “dark” SKUs. This allows for a level of product data management that competitors relying solely on automation simply cannot match. You aren’t just seeing the surface; you are seeing the entire iceberg.
The Synergy: Hybrid Research Models
We must dispel the notion that humans and machines are in a “zero-sum” competition. The most successful e-commerce operations in 2026 utilize a Hybrid Research Model. This model recognizes that while machines provide the “Muscle,” humans must provide the “Brain.”
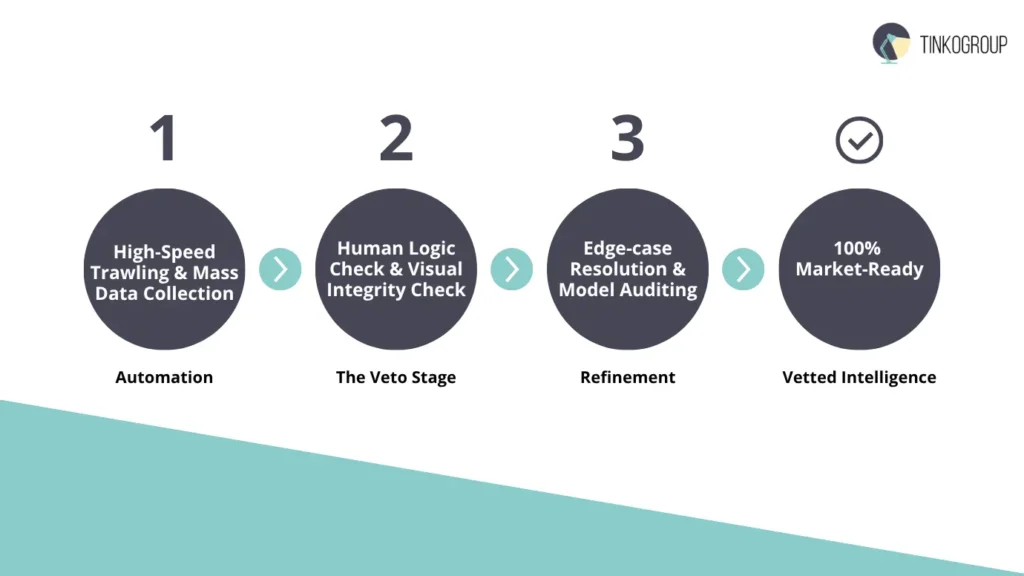
Automation for Speed, Human Veto for Accuracy
In a hybrid workflow, automated data extraction is used as a “trawler.” It brings in massive amounts of raw data. This is where the machine shines — processing millions of rows of potential leads or price points.
However, before this data is allowed to touch the “Master Catalog,” it must pass through a “Human Veto” stage. This is the essence of manual internet research as a quality gate.
- The “Logic Check”. If a bot reports that a competitor’s price dropped by 90% in one hour, the human researcher investigates. Is it a flash sale? A technical glitch? Or did the bot scrape a “Used” price instead of a “New” one?
- The “Visual Check”. In tasks involving high-volume image processing, the machine may flag two images as “similar.” The human researcher then performs the final SKU image matching to confirm if they are truly the same product or just similar-looking models from different years.
The Role of Human-in-the-Loop AI Service Providers
This hybrid model has given rise to a new class of enterprise partner: the human-in-the-loop AI service providers. These organizations do not just sell software; they sell “Managed Accuracy.”
These providers use human experts to:
- Label training data. For visual data collection for AI, humans provide the “ground truth” labels that tell the AI what it is looking at.
- Edge-case resolution. When an AI agent encounters a “new” type of website layout or a novel CAPTCHA, it hands the task off to a human. The human completes the task, and the AI watches and learns.
- Audit and refinement. They perform continuous audits of the product data management system, identifying “drift” where the AI has slowly started to make incorrect assumptions.
Without this human “Loop,” AI systems eventually become detached from reality. The hybrid model ensures that your data infrastructure is not just fast, but “self-correcting.”
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Case Study: High-Stakes Data Projects and the Precision Mandate
In the upper echelons of global commerce, the margin for error is effectively zero. For a Director of E-commerce at a Fortune 500 company, a “95% accuracy rate” in product data management is not a success; it is a systemic failure that represents thousands of incorrect shipments, customer service nightmares, and potential legal action. This is where manual internet research transitions from a “luxury” to a “necessity.”
The Luxury Goods Sector: SKU Image Matching and the “Aesthetic Audit”
Consider the global market for luxury horology or high-end fashion. In these industries, the difference between a $10,000 watch and a $12,000 watch may be as subtle as the font used on the date wheel or the type of “sunburst” finish on the dial.
Current computer vision models, while impressive, often fail at this level of granularity. They might identify a “Stainless Steel Chronograph” correctly, but they struggle with:
- Refractive variations. AI often misinterprets the “AR Coating” on a sapphire crystal as a color change in the dial itself.
- Serial continuity. Distinguishing between a “Mark I” and a “Mark II” dial requires historical context that an autonomous scraper cannot access.
- Packaging discrepancies. Often, a product is authentic, but the box is from a different year.
A human expert performing SKU image matching brings a “connoisseur’s eye” to the data. This human-led visual data collection for AI ensures that the training sets used by the company’s internal search engines are not poisoned by “near-matches.” If a luxury brand’s internal database confuses two similar SKUs, the resulting competitor image research will yield false pricing trends, leading to a loss of brand equity.
The Medical Device Industry: The High Cost of Automated Errors
In the medical device and pharmaceutical sectors, product data management is a matter of safety. If an automated scraper misreads a “milligram” (mg) as a “microgram” (mcg) due to a character encoding error on a distributor’s site, the consequences are literal life-and-death scenarios.
Automation fails in medical data for several reasons:
- Regulatory volatility. FDA or EMA warnings are often issued via PDF updates or “Dear Doctor” letters that are not instantly indexed. A bot might continue to scrape the “standard” spec sheet while a human performing manual internet research finds the urgent safety revision.
- Semantic similarity. Many medical components have SKUs that differ by only one digit, representing vastly different compatibility standards (e.g., a 12mm vs. a 12.5mm valve).
- The “Ghost” inventory problem. Bots often scrape “In Stock” indicators that are actually placeholder text. A human researcher will call the distributor or check the “Last Updated” metadata to verify the truth.
In these “High-Stakes” environments, human-in-the-loop AI service providers provide a critical layer of Liability Insurance. By having a human “veto” every data point before it enters the production environment, these companies protect themselves from the catastrophic cost of automated errors.
The Catastrophic Cost of Automated Errors in Product Data Management
What happens when a company relies 100% on automated data extraction? The “hidden costs” often exceed the savings of the software subscription.
- Logistical “Deadweight”. If your deep web research for SKU is automated and fails to detect a change in product dimensions, your automated warehouse will misallocate shelf space. This leads to thousands of items that cannot be “binned” correctly, halting the entire supply chain.
- Pricing “Flash Crashes”. We have seen instances where a competitor’s bot reacts to your bot’s error. If your scraper incorrectly records a competitor’s price as $1.00 (due to a site glitch), your “Auto-Pricing” algorithm might drop your price to $0.99. This triggers the competitor’s bot to drop further, creating a “race to the bottom” that can wipe out millions in margin in minutes.
- SEO “Cannibalization”. When internet research for product data is poor, you end up with duplicate or conflicting product descriptions. Google’s algorithms penalize “Thin Content” and “Duplicate Content.” If your automated system pulls “AI Slop” from other sites, your organic rankings will plummet, handing the market to competitors who invested in high-quality, human-verified descriptions.
The ROI of Human Verification
To a Business Leader, manual internet research should be viewed as an Investment in Data Integrity. While the “cost per SKU” for manual research is higher than for a bot, the “cost per accurate SKU” is often lower.
When you account for the cost of:
- Processing returns;
- Correcting inventory errors;
- Recovering from SEO penalties;
- Legal compliance audits.
The “Human-Led” model proves to be the most cost-effective strategy for long-term growth.
Conclusion: Designing for Human-Machine Synergy
By 2026, the industrial consensus has shifted: the most successful organizations no longer chase “total automation” as a goal. Instead, they invest in expert-led research ecosystems where manual internet research acts as the steering mechanism for high-speed automated tools. While software provides the “muscle” to scan millions of pages, only human researchers provide the “vision” to interpret context, verify high-stakes SKU image matching, and navigate the ethical complexities of e-commerce data research.
Forward-thinking Business Leaders have realized that “AI Slop” and synthetic data loops are the greatest threats to their product data management. To combat this, they employ human-in-the-loop AI service providers to ensure that every data point — from deep web research for SKU to competitor image research — is grounded in reality, not just probability. In the high-stakes economy of the late 2020s, the ultimate competitive advantage isn’t just having the most data; it’s having the most accurate data.
Is your data pipeline truly reliable, or is it just fast? At Tinkogroup, we bridge the “Human Accuracy Gap” by combining cutting-edge automated data extraction with elite manual verification. We specialize in transforming raw internet research for product data into high-fidelity business intelligence that drives real growth.
Explore our Research Data Services and let us help you build a data foundation that is 100% human-verified and market-ready. Contact Tinkogroup today to secure your competitive edge in 2026.
Why can’t I just use AI agents for all my data collection?
While automation is excellent for high-scale data harvesting, the 2026 digital landscape is plagued by “AI Slop” (low-quality synthetic content) and model hallucinations. AI operates on probabilistic frameworks—essentially “guessing” based on patterns. Business decisions require certainty. Manual research provides the cognitive verification that algorithms currently cannot replicate.
Can manual research bypass modern anti-bot defenses like “Ghost UIs”?
Yes. Many high-value e-commerce platforms now deploy Ghost UIs to feed scrapers decoy data. A manual researcher operates as a genuine biological user with natural behavioral patterns. This remains the only foolproof method to ensure you are seeing the same data as a real customer, rather than a “honey-pot” version intended for competitors.
How does human oversight help in identifying counterfeit products?
Automated scripts often struggle to distinguish between an authorized distributor and a sophisticated counterfeit site. Our experts perform multi-vector verification: analyzing WHOIS records, evaluating the “Tone of Voice” in legal disclaimers, and cross-referencing metadata to ensure your benchmarks are based on authentic market data.


