

In the high-stakes ecosystem of global digital retail, the primary bottleneck to exponential growth is no longer just logistics or customer acquisition cost. It is a phenomenon known as “Content Debt.” This debt accumulates when a brand’s SKU expansion outpaces its technical capacity to visually represent those products with high-fidelity, machine-ready assets. For the modern E-commerce Operations Manager, this crisis often manifests as the “manual trap.”
The “manual trap” is a deceptive operational pitfall where leadership attempts to solve a big data problem with linear human labor. Hiring a revolving door of 20 or 30 junior contractors to manually “save images from Google” is a recipe for systemic disaster. This approach lacks version control, legal provenance, and technical consistency. Manual collection is plagued by a 12% average error rate in SKU image matching, leading to mismatched product pages that erode consumer trust instantly.
The impact of poor visual data is quantifiable. Industry benchmarks indicate that 67% of high-intent consumers prioritize image quality over text descriptions. Furthermore, visual data collection for AI requires absolute data integrity. If an organization feeds “garbage” into its recommendation engines, the resulting algorithmic hallucinations lead to a direct collapse in conversion rates. Therefore, sophisticated enterprises must treat product image research and collection as a strategic business process — a form of “Visual Industrialization” that bridges the gap between a raw manufacturer manifest and a live, AI-optimized product page.
Phase 1: Deep Internet Research & Source Mapping
Scaling a catalog to 500,000 or 1,000,000 SKUs requires a methodology that moves beyond surface-level web searches. It begins with the construction of a “Source Hierarchy,” which serves as the foundational map for all e-commerce data research.
The Source Hierarchy: Mapping the Data Landscape
Professional researchers categorize data environments into three distinct tiers to ensure the “Golden Record” is always retrieved:
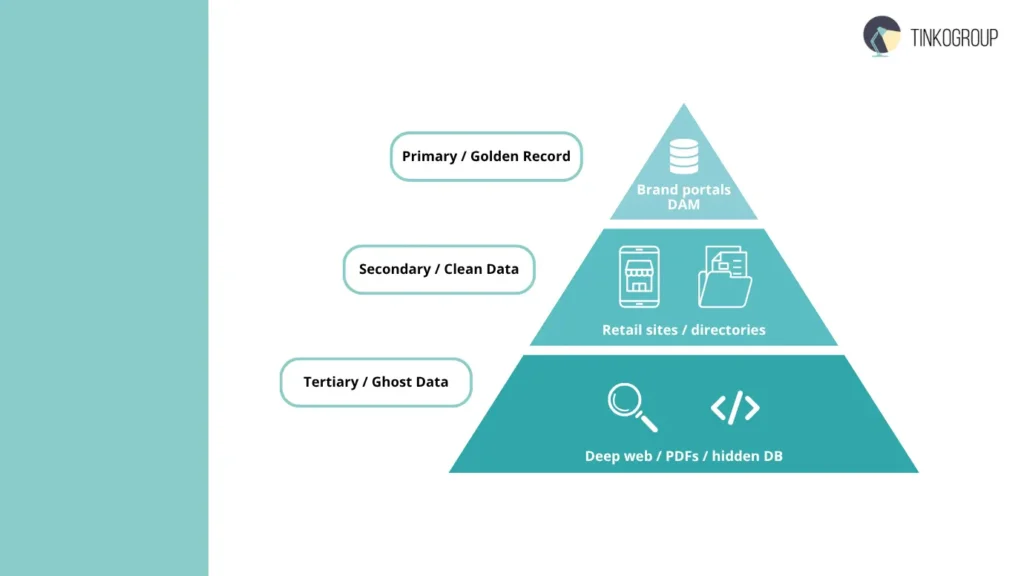
- Primary Sources (The Source of Truth): These include Brand Portals and internal Digital Asset Management (DAM) systems. Navigating these requires high-level internet research for product data to secure original high-resolution assets and embedded EXIF metadata that basic scrapers often miss.
- Secondary Sources (The Aggregator Tier): When primary access is restricted, the focus shifts to “clean” retail aggregators and manufacturer directories. This involves a rigorous filtering process to ensure the assets are not “legacy” versions of the product.
- Tertiary Sources (The Competitive Tier): This involves competitor image research on major marketplaces to identify the “Hero Shot” standards that are currently driving market trends.
Expert Tip: The “Ghost SKU” Problem
A recurring challenge in aggressive catalog scaling is the “Ghost SKU” — a product that exists in the physical supply chain but remains invisible to standard search engine indexes. Solving this requires deep web research for SKU assets. Specialists must query unindexed SQL databases, extract data from legacy PDF catalogs, and reverse-engineer GraphQL endpoints that serve internal distributor back-ends. This proactive product discovery and research ensures that a retailer can go live with a new product line before the competition has even identified the source files.
Phase 2: Technical Execution of Image Sourcing
The transition from research to execution is where most internal operations fail. A basic bulk product image downloader is a tool for hobbyists, not for industrial-scale commerce. To achieve true scale, an organization must deploy an infrastructure capable of automated web scraping for images without triggering the sophisticated anti-bot defenses of manufacturer portals.
Moving Beyond Simple Extractions
Professional e-commerce image sourcing utilizes headless browser clusters (such as Playwright or Puppeteer) that can render JavaScript-heavy sites exactly as a human user would. This prevents the “blank page” problem common with basic Python scripts. Furthermore, the system must utilize residential proxy rotation and browser fingerprint randomization to maintain a low-profile footprint.
Maintaining the “Golden Thread”
The single most important technical requirement is the preservation of the “Golden Thread” — the immutable, cryptographic link between the image file and its specific SKU ID. Throughout the e-commerce image sourcing journey, the asset must never lose its identity. If the link is broken, the cost of re-matching 100,000 images manually is often higher than the original cost of collection.
Expert Tip: Bypassing Anti-Scraping Barriers
Tinkogroup’s approach to high-volume harvesting is built on “Ethical Persistence.” By architecting systems that respect the host server’s “robots.txt” while utilizing API-based extraction, specialists can bypass Cloudflare and Akamai barriers that stop 99% of standard scrapers. This ensures that the product discovery and research phase results in a 100% fill rate for the client’s catalog, regardless of the target site’s complexity.
Phase 3: Visual Data Enrichment & Standardization
Retrieving raw “found” images is merely the raw material phase of the supply chain. To create a cohesive, trustworthy brand identity, these heterogeneous assets must pass through what we term the “Digital Refinery.” This is the specialized domain of high-volume image processing, where raw data is converted into a standardized, merchant-ready format. Without this phase, a catalog remains a disorganized collection of files rather than a structured business asset that supports product data management excellence.

The Standardization Pipeline
Transforming raw assets into a unified, high-performance catalog involves several critical automated neural network stages:
- AI background removal. Every product is mathematically stripped of its original environment. By utilizing deep learning saliency models, the object is placed on a consistent, brand-mandated white or transparent canvas. This ensures that the market research for e-commerce visuals results in a clean, professional aesthetic that minimizes visual noise.
- Automated padding and alignment. Consistency is the hallmark of a premium marketplace. The software calculates the exact geometric center of the object and applies uniform margins. This eliminates the “jitter” effect when a user scrolls through a category, ensuring the “grid view” on the mobile app is flawless and visually balanced.
- Next-gen compression. Assets are converted into WebP or AVIF formats. This is not just a technical preference but a strategic requirement for SEO meta tags and overall page speed. By reducing the weight of the visual payload, we directly improve the site’s Core Web Vitals, which is a primary ranking factor in modern search algorithms.
The Final Bridge: SKU Image Matching
The enrichment process concludes with a rigorous, multi-layered SKU image matching audit. This is the critical moment where research meets reality. By deploying a combination of perceptual hashing (pHash) — which compares the visual “DNA” of the file — and Optical Character Recognition (OCR) to read internal labels, the system confirms that the “found” visual is a 100% match for the target SKU.
This final validation step is the ultimate safeguard against “Catalog Drift.” It prevents the catastrophic operational error of a customer receiving a physical product that looks significantly different from the website photo. In a high-scale environment, this automated e-commerce data research check is the only way to ensure that 500,000 images stay perfectly aligned with 500,000 unique inventory IDs, maintaining the integrity of the entire internet research for product data ecosystem.
The Downstream Value: From Sourcing to Machine Learning
Successful market research for e-commerce visuals provides the fundamental “fuel” for modern AI initiatives. In the current technological climate, the retail industry is governed by the “Garbage In, Garbage Out” (GIGO) axiom. If the initial visual data collection for AI is compromised by low-resolution files, incorrect metadata, or inconsistent lighting, the resulting model will inevitably suffer from high error rates in production. Sophisticated retailers recognize that the quality of their sourcing directly dictates the accuracy of their visual search and recommendation engines.
Visual Data Collection for AI
Training a neural network for visual search, “shop the look” features, or automated category tagging requires a dataset that is significantly cleaner and more structured than what is required for a standard web page. Professional visual data collection for AI ensures that the training sets are free from digital artifacts, such as compression noise or watermarks, which can confuse an algorithm during the feature extraction phase.
Furthermore, expert sourcing ensures the dataset is diverse enough to prevent “model bias.” This means collecting images of a single SKU under various lighting conditions, angles, and backgrounds during the product discovery and research phase. A diverse dataset prevents the model from “overfitting” — a common failure where an AI can only recognize a product if it appears exactly as it does in a manufacturer’s studio shot. By providing a rich variety of high-fidelity assets, product image research specialists allow AI researchers to build models that are resilient to real-world user photography and suboptimal lighting.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Connecting Sourcing to Annotation
When the sourcing phase is handled by experts, it streamlines the entire machine learning lifecycle, transforming a fragmented workflow into a unified pipeline. Clean, pre-validated collection saves up to 40% of the labor time in the “Bounding Box” and segmentation stages — the most expensive and time-consuming part of AI development. In a typical in-house project, annotators often spend more than half their time simply verifying if an image actually matches the intended SKU.
Because the SKU image matching was performed with 99.9% accuracy during the initial internet research for product data phase, annotation teams are liberated from the burden of data verification. They do not have to cross-reference multiple databases or guess the identity of a product; they can move immediately to drawing precise masks and tagging specific attributes like material, pattern, or collar type. This structural alignment between e-commerce image sourcing and data labeling not only reduces costs but also significantly decreases the “time-to-deployment” for new AI features.
Ultimately, the synergy between high-volume image processing and machine learning readiness creates a “Data Moat.” Companies that invest in professional e-commerce data research today are building a foundation of structured visual intelligence that will power their automated merchandising and personal shopping assistants for years to come. By treating the image as a data-rich asset rather than a static file, brands can finally close the gap between their physical inventory and their digital intelligence.
Conclusion: Scaling with a Research Partner
Scaling a visual catalog of 100,000+ items is not a project; it is a continuous operational challenge. When calculating the ROI of product image research, organizations must look beyond the per-image cost. They must consider “Speed-to-Market” versus the massive internal overhead of managing a 20-person manual team. In the hyper-competitive landscape of digital retail, being first to index a new collection can result in a 25% higher capture rate of organic search traffic. Internal teams, bogged down by the “manual trap,” often miss these windows, accruing “Content Debt” that can take quarters to resolve.
The internal cost of hiring, training, and managing human contractors — combined with the 12% error rate and the technical debt of building custom scrapers — often exceeds the cost of a professional partner by a factor of 3x. Furthermore, internal e-commerce data research units rarely have the bandwidth to maintain the rotating proxy networks and headless browser configurations necessary for automated web scraping for images. When a major manufacturer changes its site architecture or implements a new bot-defense layer, an internal team can be paralyzed for weeks. A specialized partner, however, treats these technical hurdles as routine maintenance, ensuring a constant, uninterrupted flow of assets into the product data management (PDM) system.
Beyond mere execution, Tinkogroup’s internet research for product data specialists act as a high-precision extension of the client’s internal operations. They provide the “Elastic Catalog” capability that modern enterprises need to pivot into new markets or seasonal trends instantly. By delivering ready-to-use, enriched visual assets — complete with verified SKU image matching and optimized SEO meta tags — Tinkogroup allows retailers to focus on their core competency: selling products and refining the customer journey.
In an era where the algorithm is the new storefront, owning a clean, high-velocity visual pipeline is the only sustainable competitive advantage. Organizations that treat visual data collection for AI as a utility rather than a burden can scale their machine learning initiatives and visual search tools with a fraction of the traditional R&D spend. Ultimately, the partnership is about shifting from a reactive state of “fixing broken data” to a proactive strategy of “dominating the visual search landscape.”
What is “Content Debt” in e-commerce, and how does it affect growth?
Content Debt occurs when a retailer’s product expansion moves faster than their ability to source high-quality images. In high-scale operations, this leads to lower conversion rates and broken customer trust. Our product image research process is designed to eliminate this debt by providing automated, high-fidelity visual assets at scale.
How do you solve the “Ghost SKU” problem during data collection?
A “Ghost SKU” is a product that exists in inventory but is invisible to standard search engines. We use deep web research techniques, such as querying unindexed SQL databases and extracting data from legacy PDF catalogs, to ensure every item in your catalog has a corresponding high-quality image.
Why is SKU image matching critical for AI training?
For AI-driven features like visual search or recommendation engines, data integrity is everything. If the image doesn’t perfectly match the SKU ID, the AI “hallucinates,” leading to incorrect product suggestions. Our product image research includes a multi-layered audit using perceptual hashing (pHash) to ensure a 99.9% match accuracy.


