
As the amount of information grows, it becomes increasingly difficult for businesses to manage document flows effectively. Paper documentation standards are gradually becoming a thing of the past, giving way to digital formats. However, most of the critical data is still stored on paper or in images, which creates obstacles to their quick and accurate processing. Therefore, the optical character recognition (OCR) technology allows you to automatically read text from documents and transform it into a digital format.
With OCR data extraction technology, document processing becomes faster and more accurate, which discovers new opportunities for automating business processes. How exactly does OCR change the approach to operating with documents – let’s explore in this article.
What is OCR and how does it work?
OCR for data entry is an advanced technology that allows computers to read text from images, scanned documents, or photos and reverse it into an editable digital format. With this technology, vast amounts of paper data can be automatically converted into electronic files that can be easily stored, edited, analyzed, and shared.
In fact, data entry OCR technology has become a revolution in document processing because it allows you to free yourself from entering text manually. Its operation consists of reading and analyzing an image containing text, then recognizing individual symbols and converting them into digital data. For this, special algorithms are used to realize fonts, letter shapes, and differences between text and background images or graphics.
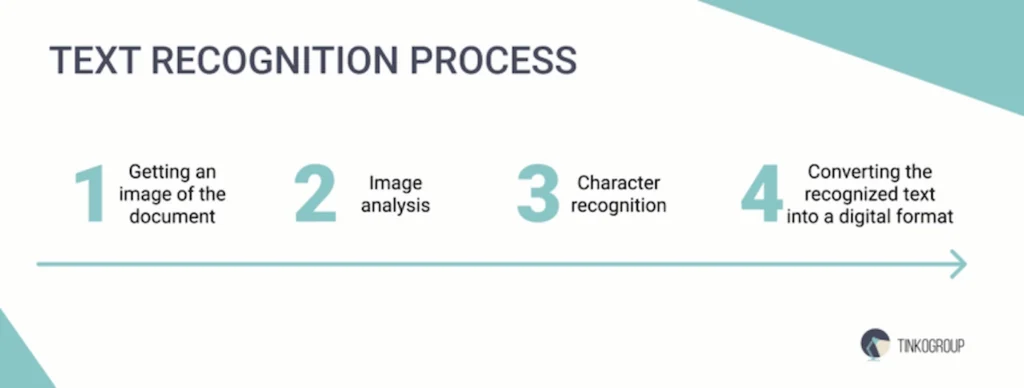
The process of text recognition using OCR usually consists of several stages. The first step is to get an image of the document, which can be taken with a scanner, camera, or smartphone. Next, the software performs image analysis, identifying areas that contain text. An important point is the ability of OCR technology to distinguish text from other elements in the image, such as graphics or drawings.
Following this, the character recognition process takes place. The OCR extraction algorithm scans each character, comparing it to an extensive database of different fonts and symbols. Modern OCR systems also employ machine learning techniques, enhancing their accuracy over time. This is particularly crucial when recognizing text from various languages or from texts containing complex elements, such as handwritten letters, instilling confidence in the system’s capabilities.
The final step is to convert the recognized text into a digital format that can be saved in a Word document, PDF, or other editable file. This text can then be used for further editing, searching, or analysis.
Introduction to computer vision
In a nutshell, computer vision is a field of artificial intelligence (AI) that allows computers to “see” and interpret visual information as a person does. The ground of this technology is the ability to analyze images or videos, recognize objects, patterns, and structures, and draw conclusions based on the received data.
The role of computer vision in analyzing visual information is to enable machines to understand images and process large amounts of information quickly and accurately. For instance, when we look at an image, our brain automatically recognizes objects, colors, textures, and distances.
Object recognition is one of the critical tasks of computer vision. Modern algorithms can highlight various image elements: people’s faces, cars, signs, text, and complex patterns. For example, in the OCR data extraction process, computer vision helps systems recognize text in photos or scanned documents by analyzing each letter and symbol and determining their structure and shape.
Computer vision is also effective at recognizing patterns and structures. For example, in the medical field, this technology helps analyze medical images such as X-rays or magnetic resonance imaging (MRIs), allowing doctors to detect diseases early.

Examples of the use of computer vision can be found in many industries. For example, in self-driving cars, this technology helps the car “see” the road and recognize obstacles, signs, and other vehicles. In security, computer vision cameras are used for facial recognition, crime prevention, and tracking suspicious activity. Even in everyday life, we encounter this technology in smartphones, which helps recognize faces to unlock the device or organize photos by category.
Key benefits of using computer vision for OCR data extraction
Using computer vision for intelligent data extraction is becoming one of the most effective tools in modern document processing. The combination of computer vision and OCR data extraction software allows you to achieve incredible accuracy and efficiency when automating routine information processing.
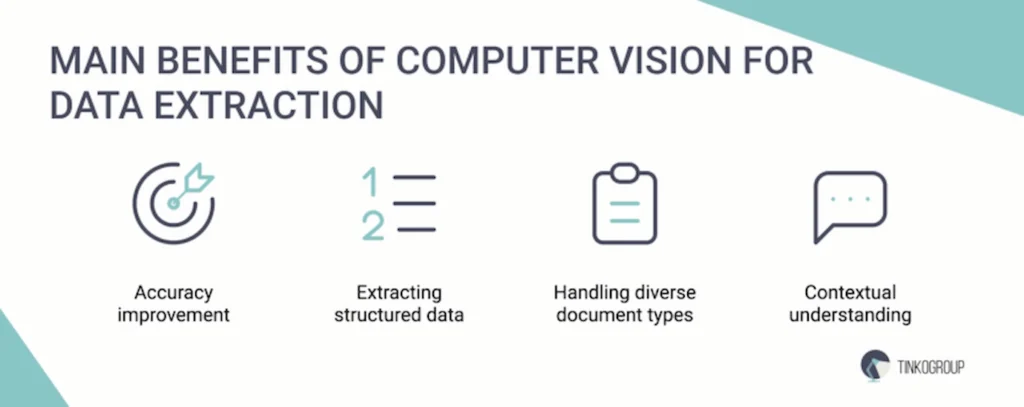
Accuracy improvement
One of the fundamental benefits of using computer vision in document processing is that it increases OCR data extraction accuracy. Traditional methods often make errors in text recognition, especially in complex documents with handwritten elements or low image quality.
However, modern computer vision algorithms use machine learning (ML) to recognize even minor details. This means that the accuracy when extracting information becomes much higher, which is especially important for businesses with large volumes of data, such as financial institutions or government organizations.
Extracting structured data
Another important advantage is the ability to extract structured data from a variety of documents. Computer vision allows you to transform chaotic and complex documents into ordered and comprehensible arrays of data. This opens wide opportunities for analysis and further use of the received information in various business processes.
For example, invoices, contracts, or medical documents can be automatically processed and structured, which allows to significantly simplify their further use and storage.
Handling diverse document types
Equally important is the adaptability of computer vision, which enables it to operate with various document types, regardless of their format, quality, or source. Be it scanned pages, images, spreadsheets, or even photos of documents, the system can seamlessly adapt to each. This gives companies the flexibility to handle documents of diverse origins without needing pre-formatting or manual preparation, enhancing operational convenience.
Contextual understanding
Moreover, computer vision provides a contextual understanding of the data, allowing the system to extract text and interpret its meaning. This means that documents can be analyzed deeper, considering the context in which specific data is used.
For example, financial documents can automatically identify categories of expenses or income, and legal texts can highlight important clauses in contracts.
Steps to implement computer vision for OCR data extraction
Below, we will analyze the main stages of implementing computer vision for OCR data extraction, which helps to significantly simplify document processing and increase the productivity of business processes.
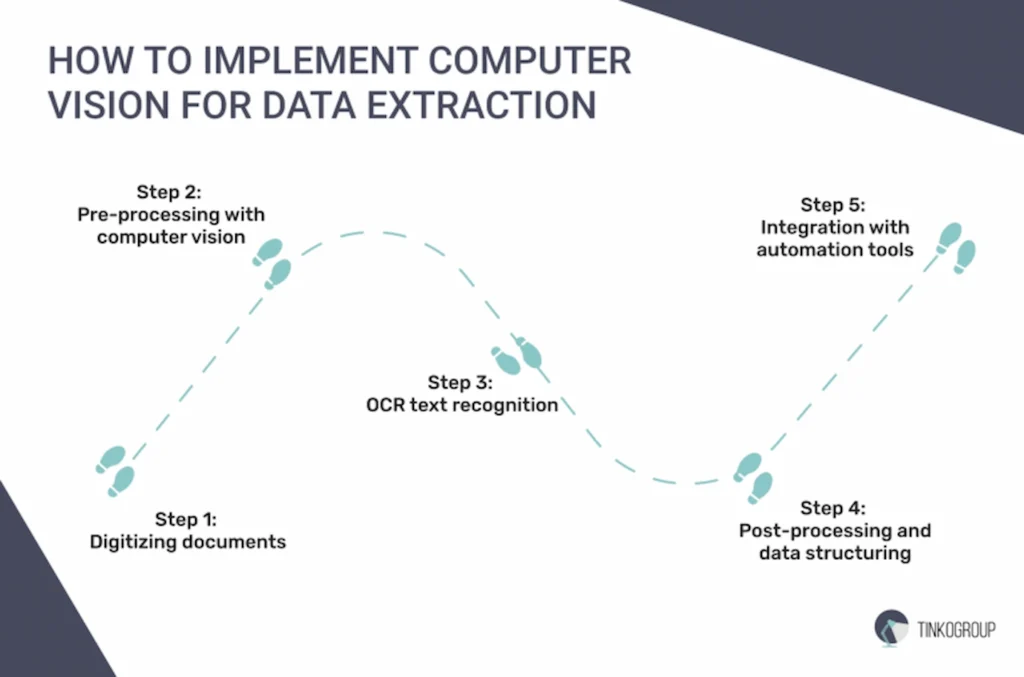
Step 1: Digitizing documents
The first and most crucial stage is document digitization. In most cases, documents are stored in paper form, complicating their processing and accessibility. To use computer vision and OCR, these documents must be converted into electronic format. Digitization can be done using scanners or specialized mobile applications that capture high-resolution images.
At this stage, it is important that the obtained images are of good quality and clear, as this will affect the subsequent stages of processing. Blurry or low-quality images can make it difficult to recognize text, leading to errors in the OCR data extraction process. That is why choosing quality digitization tools is essential to successfully implementing computer vision.
Step 2: Pre-processing with computer vision
After the documents are digitized, the next step is to pre-process the images using computer vision technologies. This stage consists in preparing the image for further analysis and text recognition. Pre-processing can include contrast correction, noise removal, image smoothing, and text area enhancement.
The purpose of pre-processing is to make the image as “understandable” as possible for the text recognition system. With the help of special computer vision algorithms, it is possible to automatically correct the shortcomings of digitized documents, reducing the number of errors at the next stages and increasing the final result’s accuracy. This process is beneficial for OCR document management that contains low-quality images or different fonts.
Step 3: OCR text recognition
A key step in the process is using OCR for data entry to extract text directly from digitized images. In this step, the system recognizes each character or letter in the image and converts it into digital text that can be edited and processed.
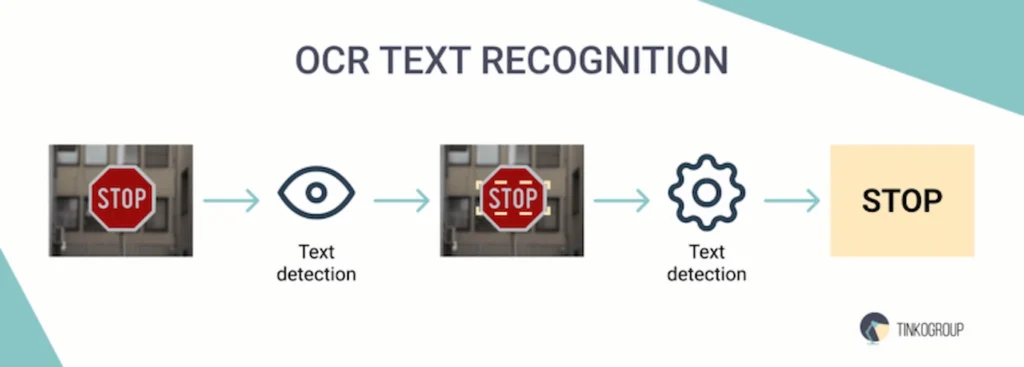
OCR text extraction technology uses specialized algorithms to analyze the shape of each letter and character, comparing them to built-in patterns. Depending on the type of document (printed or handwritten), OCR can use different recognition methods. OCR is often mixed with other computer vision techniques to improve accuracy for complex documents, such as handwritten records or old paper archives.
Step 4: Post-processing and data structuring
After the text has been recognized by OCR, post-processing is necessary to ensure that the data is properly structured. At this stage, automated systems check the correctness of the recognized text, correct possible errors, and organize the data into convenient formats for further work.
This process is significant for documents that contain tables, charts, or specialized formats. For instance, invoices or reports may require additional processing to highlight the required fields or categories. Post-processing allows you to systematize the received data, facilitating their integration into business processes and ensuring the high quality of the final result.
Step 5: Integration with automation tools
The last step in the process is integrating the received data with automation systems. This allows you to automate further stages of working with documents—from data storage to their use in accounting, management, or other business processes.
Automation tools, such as customer relationship management (CRM) systems, enterprise resource planning (ERP) platforms, or other specialized applications, can easily interact with recognized data, significantly increasing the company’s efficiency. As a result, instead of manual document processing, the company can rely on automated solutions, which reduces the risk of errors and the time spent on routine tasks.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Technologies for OCR and computer vision integration
Integrating computer vision and OCR software for data entry delivers new possibilities for document processing automation, reducing time and human resources for routine tasks. These technologies work together to enable deeper image analysis and detection of visual information that is difficult to process with traditional methods.
Artificial intelligence and machine learning
AI and ML are fundamental technologies that enable computer vision and OCR to improve their results through experience. Machine learning algorithms analyze vast amounts of data, identifying patterns and structures that help systems improve text and object recognition accuracy over time. This is especially important for documents containing handwritten or non-standard fonts, where traditional OCR methods can produce errors.
For example, our company actively uses the Computer Vision Annotation Tool (CVAT) as a critical tool for data processing in computer vision projects. CVAT is a powerful image and video annotation tool that allows you to precisely and quickly adjust parameters for OCR extraction and recognition. Using CVAT, our team can work efficiently with large data sets and ensure the accuracy critical to the success of OCR and other computer vision solutions.
Cloud platforms
These solutions have become essential for integrating OCR and computer vision, as they allow the processing of large volumes of documents without the need for local infrastructure. Thanks to cloud platforms, companies can store and process documents securely, automatically gaining access to the latest software versions and technology updates.
API for OCR and computer vision
Application programming interfaces (APIs) enable businesses to integrate OCR data extraction and computer vision functions easily into their applications and software solutions. They provide access to text and image recognition functionality through simple calls, greatly simplifying the integration process.
Computer vision algorithms
Computer vision uses specialized algorithms that allow a machine to “see” and understand visual data. These algorithms allow OCR systems to recognize text in context while also analyzing the surrounding elements of the image, such as pictures, charts, or graphs.
Challenges of implementing OCR
Using OCR technology for document processing can significantly increase the efficiency and productivity of business processes. However, as with any other technology, applying OCR also has its challenges that are important to consider in order to achieve optimal results.

- Quality of incoming documents: One of the biggest challenges for OCR document management is the quality of the documents being processed. Text recognition may be difficult if documents are of low resolution, dirty, or contain damage. The lower the image quality, the greater the chance of recognition errors. This can lead to significant time-consuming post-processing and error correction.
- Font and format complexity: OCR works best with standard fonts and formats. If the documents contain non-standard fonts, handwritten text, or different formats, this can negatively affect the recognition accuracy. For example, documents with graphs, tables, or figures may need additional context for correct analysis.
- Contextual understanding: Although modern OCR data entry systems use machine learning algorithms that improve recognition accuracy, they can still face difficulties in understanding the context of documents. For example, terms with multiple meanings can be misinterpreted.
Bottom line
OCR data extraction technology has become a real revolution in document processing. This simplifies converting textual information from paper and visual media into a user-friendly digital format. It helps companies automate routine processes, reduce time and resource costs, and minimize errors that often occur during manual OCR data entry.
For companies aiming to improve data workflows through robust OCR and data entry services, our team is ready to help. We specialize in data processing and implementing practical solutions to speed up your business processes and reduce costs. Contact us to transform the way you manage information effectively!
What is OCR data extraction?
OCR data extraction is a technology that converts documents, such as scanned paper documents, PDFs, or images, into searchable data. It works by analyzing the patterns and shapes of text in an image and translating them into machine-readable characters.
What is data OCR?
By recognizing characters, words, and sentences, OCR turns non-editable formats into structured data that can be easily edited, searched, or processed for further use. It is commonly used for digitizing printed documents and automating data entry tasks.
What is OCR data capture?
OCR data capture automatically extracts information from printed or written text using OCR. In fact, OCR data capture is widely used in the finance, healthcare, and logistics industries to handle data efficiently and manage documents.
How to extract text using OCR?
To extract text using OCR, you can choose an OCR tool, upload the image or document, run the OCR process, and edit and export the extracted text.


