

In the hyper-competitive landscape of global commerce, information is no longer just an asset; it is the primary engine of scalability. However, a critical distinction must be made between casual browsing and a professional internet research service. While the former relies on surface-level search engine results, the latter functions as a sophisticated data extraction operation. It involves the systematic identification, collection, and refinement of fragmented digital signals into structured, actionable intelligence.
For executives and Catalog Leads, the real challenge is the overwhelming abundance of unverified, noisy data that clogs decision-making. Professional research providers solve this by using advanced frameworks to align every data point with business objectives. In modern enterprises, structured data acts as the nervous system. It feeds ERP systems, powers recommendation engines, and ensures that product discovery and research workflows remain fluid and error-free.
The Full Spectrum of an Internet Research Service
A comprehensive internet research service extends far beyond simple text retrieval. It encompasses a multi-layered approach to digital asset acquisition, ranging from competitive intelligence to the technical foundations of machine learning.
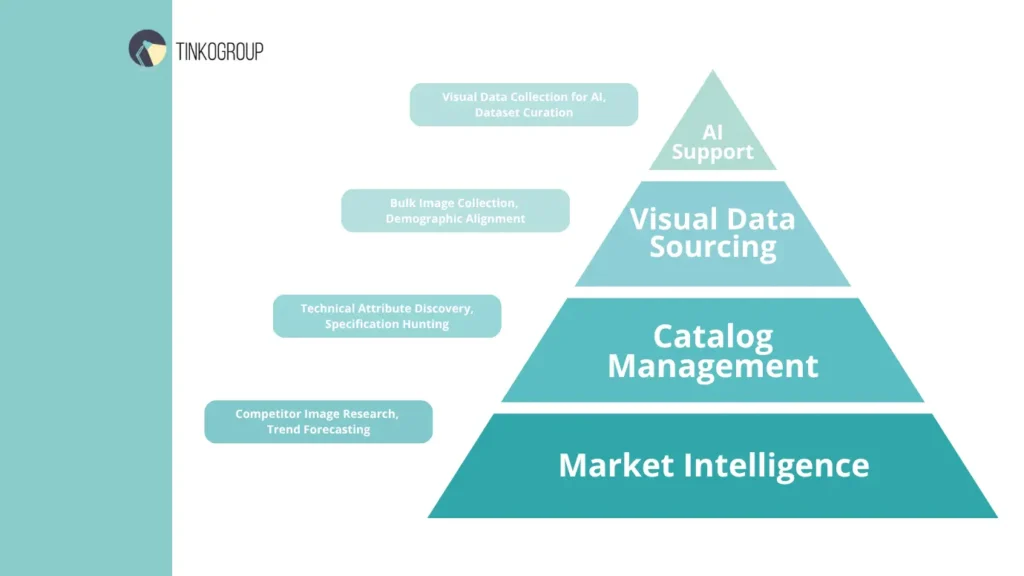
Market Intelligence and Strategic Analysis
To maintain a dominant market position, a brand must possess a 360-degree view of its ecosystem. This starts with competitor image research. By analyzing how rivals visually position their products — including lighting, angles, and lifestyle contexts — businesses can identify gaps in their own presentation. This analysis is paired with trend forecasting, where researchers track shifts in consumer sentiment across non-traditional platforms, ensuring that inventory alignment precedes market demand rather than trailing it.
Catalog Management and Technical Attribute Discovery
The core of any e-commerce operation is its catalog. Yet, many enterprises struggle with “hollow” listings — products that exist on a site but lack the technical depth to convert a skeptical buyer. Professional internet research for product data solves this by hunting for missing specifications. This involves scouring manufacturer whitepapers, digital archives, and certification databases to find exact technical attributes. When thousands of SKUs require this level of detail, manual internal efforts typically collapse under the weight of the task, leading to lost revenue and high bounce rates.
Visual Data Sourcing: The Aesthetic Edge
Visuals are the currency of the digital shelf. A professional service manages bulk product image collection by identifying high-resolution, rights-cleared imagery that matches specific SKU requirements. This is not merely about finding “a picture”; it is about market research for e-commerce visuals to ensure that the aesthetic matches the target demographic’s expectations. Whether it is removing backgrounds, normalizing color profiles, or ensuring consistent aspect ratios, the visual component of research is a massive operational undertaking.
AI Support: Fueling the Algorithms
In the age of automation, visual data collection for AI has become a standalone pillar of research services. Machine learning models are only as effective as the datasets used to train them. Professional researchers curate these datasets, ensuring that images are correctly tagged, categorized, and bias-checked. This precision is vital for developing visual search tools or automated tagging systems that define the future of the user experience.
Why In-House Research Teams Often Fail to Scale
While the initial instinct of many Operations Managers is to build an internal data task force, the long-term reality is often a cycle of high costs and diminishing returns. The primary reason is that e-commerce data research is not a static task; it is a high-velocity operation that requires specialized management.
The High Costs of Recruitment and Turnover
Data-focused roles — specifically those centered on product discovery and research — are notoriously difficult to retain. In a typical corporate environment, entry-level researchers often view these roles as stepping stones. This results in an industry-average turnover rate that can exceed 30% annually for manual data entry positions.
When a team member leaves, the business loses more than just a salary. It loses the “tribal knowledge” of the specific catalog nuances. Recruiting a replacement involves advertising, interviewing, and a 4-to-6 week training period before the new hire reaches peak efficiency. During this gap, product launches are delayed, and the product data management system begins to accumulate errors.
The Infrastructure Gap: Beyond the Browser
A professional internet research service operates on a tech stack that most internal IT departments cannot justify. Scaling to 50,000+ SKUs requires more than a fast internet connection.
- Proxy management. To perform automated data extraction across thousands of global manufacturer sites, researchers must use rotating residential proxies. This prevents IP blocking and “shadow-banning,” where a site shows fake data to suspected bots.
- Extraction tools. Custom-built scrapers and specialized software like Import.io or Octoparse require dedicated engineers to maintain. If a manufacturer changes their website layout by even one pixel, an automated script might break, leading to corrupted data.
- Hardware and bandwidth. Handling high-volume image processing requires significant server-side processing power. An in-house team trying to resize and metadata-tag 100,000 images on standard office laptops will inevitably face system bottlenecks.
Advanced Research Methodologies
To provide true value, a research service must look where others do not. This is where the methodology shifts from “searching” to “mining.”
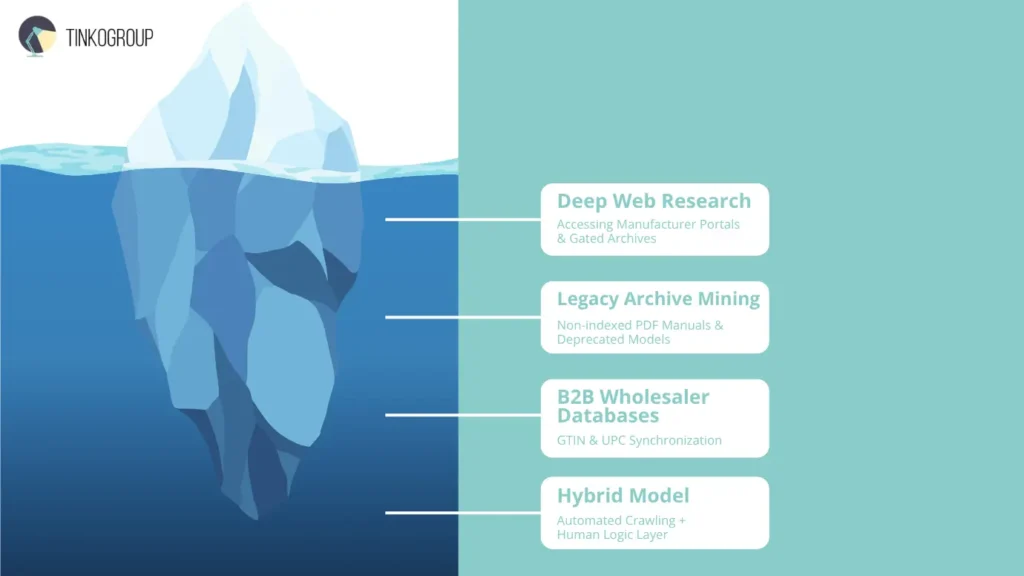
Deep Web Research for SKU Discovery
Mastering SKU acquisition means looking past the 10% of the internet indexed by standard search engines. The real value lies in the “invisible” deep web, hidden behind forms and gated authentication. Engaging in deep web research for SKU information transforms basic listings into comprehensive technical resources. Accessing restricted manufacturer portals requires a specialized internet research service that understands complex site architectures. Without this expert access, catalogs rely on recycled, low-quality competitor data.
Beyond active portals, research must pivot to legacy archives. As products evolve, manufacturers often remove older models’ technical attributes from live sites. However, these original specifications are vital for secondary markets and long-term support. Professional researchers dig through digital archives and non-indexed PDFs to find exact specs—like power consumption or compatibility—erased from the modern web. This historical depth ensures product data management systems remain accurate throughout a product’s entire lifecycle.
In complex sectors like electronics, the surface web is secondary to B2B wholesaler databases. These closed ecosystems hold the most accurate, real-time data, including essential identifiers like GTINs and UPCs for inventory synchronization. Unlike consumer sites with creative marketing, B2B databases provide the raw, unvarnished technical truths required for professional e-commerce data research. Integrating data from these non-public sources achieves a catalog density that automated scrapers simply cannot reach alone.
The Synergy of Human Expertise and Automation
The true power of a modern internet research service blends machine learning speed with human judgment. While many view high-volume data acquisition as a “set it and forget it” process, relying solely on scrapers causes catastrophic data decay. The most reliable results come from a hybrid model: automation as the engine and human expertise as the navigator. This synergy transforms raw e-commerce data research into a high-value business asset.
To achieve 99.9% accuracy at scale, a professional service follows a rigorous, multi-stage workflow:
- Phase 1. High-Velocity Automated Crawling. In this initial stage, machines handle the exhaustive heavy lifting. Using custom-built scripts and automated data extraction tools, the system can parse thousands of URLs in minutes. This phase is designed to gather 90% of the raw, unstructured data — identifying price points, technical specs, and image URLs across a vast digital landscape. However, even the most advanced bot lacks “context.” It can find the data, but it cannot always understand its relevance.
- Phase 2. The Human “Logic Layer” and Validation. Here, the service moves beyond simple scraping. Human researchers verify the output, especially during bulk product image collection. They catch automated “hallucinations”—like an AI pairing a “wireless mouse” description with a “mouse pad” image due to shared keywords. This vital oversight keeps product discovery and research accurate and prevents embarrassing catalog errors from reaching consumers.
- Phase 3. Comprehensive data normalization services. The final stage is the “polish” that makes data usable for a PDM or PIM system. It involves a massive effort to standardize fragmented inputs. For example, researchers convert all measurements to a single global standard — transforming inches to centimeters or pounds to kilograms — and ensure that brand names and attributes are spelled identically across the entire database. This level of internet research for product data is what creates a seamless, searchable user experience.
High-Volume Image Processing and Production Readiness
Gathering a visual asset is only the first step; making that asset “production-ready” is where the real complexity begins. In an internet research service workflow, visual data must undergo a transformation to meet the strict requirements of modern e-commerce platforms.
- Strategic metadata injection. Beyond the visible image, there is a hidden layer of data. Professionals embed SEO-optimized keywords, alt-text, and unique SKU numbers directly into the image file’s metadata. This ensures that the images are not only beautiful but also “searchable” by both internal systems and external search engines like Google Images.
- Visual consistency and quality checks. Customer returns are often triggered by a mismatch between the screen and reality. If a catalog displays five different shirts, the “navy blue” must look consistent across all photos. Human editors perform color-matching and consistency checks to ensure that market research for e-commerce visuals results in a cohesive brand aesthetic that reduces “buyer’s remorse.”
- Format optimization for speed and AI. Large, uncompressed files like RAW or TIFF kill page load speeds. Specialists perform high-volume image processing to convert these into web-optimized formats like WebP or JPEG. Crucially, they do this without losing the fine detail required for visual data collection for AI training. This balance ensures the site is fast for humans but detailed enough for machine learning algorithms.
When to Outsource: A Strategic Guide for Business Leaders
The decision to transition from internal data management to a professional internet research service is a significant milestone in a company’s operational lifecycle. It signals that a business has moved past the experimental phase and is now focused on enterprise-level scalability. This “data ceiling” is often hit when the sheer volume of SKUs, technical attributes, and visual assets becomes too heavy for a non-specialized team to handle without degrading quality. Below is an in-depth strategic breakdown of the three primary scenarios where outsourcing becomes a mandatory lever for survival and growth.
Scenario 1: Managing Seasonal Spikes and Massive Catalog Migrations
The e-commerce sector is defined by its extreme volatility. Whether it is preparing for the Q4 holiday surge or undergoing a complete platform overhaul, the demand for high-speed data processing can fluctuate by 500% in a single month.
- Migrating from a legacy PIM (Product Information Management) system to modern headless commerce is a high-risk operation, not a simple “lift and shift.” It demands a comprehensive audit to re-verify every technical attribute. Professional internet research services perform deep product discovery and research to fix broken links, outdated specs, and poor images that hurt user experience. Following a structured 10-step outsourcing plan ensures your project scope and resources are perfectly managed during this critical transition.
- The elasticity factor. Hiring a permanent internal team to handle a one-time migration of 100,000 SKUs is a financial trap. Once the migration is complete, the company is left with high payroll overhead for a team with no remaining “high-volume” tasks. Outsourcing provides “operational elasticity” — the ability to “rent” a massive, expert workforce for e-commerce data research during peak times without the long-term burden of benefits or recruitment costs. This allows businesses to strategically manage staffing to align with these predictable patterns.
Scenario 2: High-Accuracy Requirements for Machine Learning and AI
As businesses race to implement AI-driven personalization and visual search, the quality of the underlying data has become the ultimate bottleneck. If your training data is flawed, your AI will be biased, inaccurate, and ultimately useless to the customer.
- Precision labeling and “Ground Truth”. For AI to recommend products correctly, it needs “ground truth” data. Standard visual data collection for AI involves more than just scraping images; it requires human-verified labeling. A researcher must distinguish between a “midnight blue velvet blazer” and a “navy wool jacket.” Automated bots often fail at these nuances, leading to errors in the machine learning model. Professional research services provide the manual verification layer needed to ensure 99.9% accuracy in training datasets.
- Dataset curation and bias mitigation. Professional internet research for product data ensures that your AI models are trained on diverse, clean, and representative datasets. By outsourcing this curation, companies avoid the common pitfalls of “lazy” data collection that often plague in-house teams under pressure to meet impossible deadlines. This level of detail is what makes personalization more precise and scalable.
Scenario 3: Eliminating Operational “Fluff” to Protect Core Competencies
One of the most expensive “hidden” costs in a modern business is the high-value employee performing low-value tasks. This “operational fluff” is a silent killer of innovation and strategic growth.
- The opportunity cost of “Clean-up”: When a Senior Marketing Manager or a Catalog Lead spends twenty hours a week hunting for missing manufacturer photos or fixing spreadsheet formatting errors, the company is losing money. That time should be spent on product development, innovation, or strategic planning. Outsourcing non-core functions like bulk product image collection frees up these critical resources to focus on high-impact work that actually drives EBITDA.
- Streamlining the pipeline: By delegating the “heavy lifting” of e-commerce data research to a specialized partner, leadership can focus on the foundation for outsourcing other areas and improving the customer journey. A professional internet research service acts as a silent back-office engine, delivering clean, production-ready data directly into your PDM or PIM system, allowing your core team to remain agile and focused on brand storytelling.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

The ROI of Outsourcing to Specialists: A Financial and Operational Breakdown
For a CFO, Chief Operating Officer, or Catalog Lead, the decision to outsource an internet research service is rarely about “saving money” in a vacuum. It is about capital allocation and risk mitigation. When a business attempts to manage e-commerce data research internally, they often ignore the “shadow costs” that erode margins. Outsourcing transforms these hidden drains into a predictable, high-yield investment.
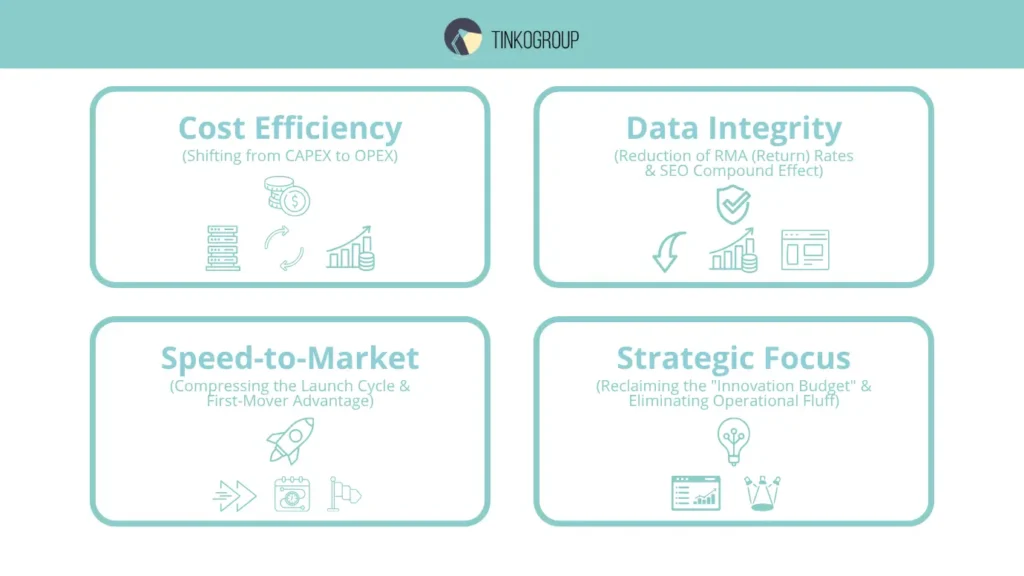
Cost Efficiency: Shifting from CAPEX to OPEX
Internal data teams are often viewed as a “sunk cost,” but in reality, they represent a “leaky bucket” of capital.
- The elimination of infrastructure overhead. To perform professional-grade automated data extraction, a firm must invest in high-end scraping licenses (often costing $5,000–$15,000 annually per seat), residential proxy networks ($2.00–$15.00 per GB), and cloud computing environments. By outsourcing, these costs — traditionally Capital Expenditures (CAPEX) — are absorbed by the service provider. The business pays only for the output, moving the expense to Operating Expenditure (OPEX), which is often more tax-efficient and easier to track against specific product launches.
- The management “Tax”. For every five junior data researchers hired, a company usually needs one mid-level manager. This manager’s time is expensive. When you outsource, the “Management Tax” vanishes. The internet research service provider handles the training, quality control, and daily task management.
- Fixed project costs vs. variable labor risks. Recruitment is a gamble. According to data from the Society for Human Resource Management (SHRM), the average cost-per-hire is over $4,700. If a researcher leaves after three months — a common occurrence in high-volume product discovery and research — that investment is lost. Specialists offer a fixed fee, insulating the business from the volatility of the labor market.
Data Integrity and the “Cost of Error”
Raw data is a liability; only normalized data is an asset. The financial impact of data normalization services is most visible in the reduction of “Return Merchandise Authorization” (RMA) rates.
- The mathematical reality of returns. In e-commerce, the average return costs the retailer roughly $15 to $25, excluding the loss of the original sale. A significant percentage of returns in electronics and fashion are caused by “Incorrect Product Information.” If an internal team misses a technical attribute — such as the exact thread count of a sheet or the millivolt output of a sensor — the resulting surge in returns can wipe out the entire profit margin of that SKU.
- The SEO compound effect. High-quality internet research for product data ensures that every field in a product data management (PDM) system is populated. Search engines like Google reward “completeness.” A product with 15 unique, verified attributes will outrank a competitor with only 3. This leads to lower Customer Acquisition Costs (CAC) because organic search traffic replaces expensive Pay-Per-Click (PPC) ads.
- Data liquidity. Professional normalization ensures that data is “liquid” — meaning it can be moved from a website to an Amazon storefront to a print catalog without manual re-formatting. This saves hundreds of man-hours during multi-channel expansions.
Speed-to-Market: The Time-Value of Data
In the digital shelf economy, “Velocity is Revenue.” Every day a product sits in a “Draft” state because of missing images or specs is a day of zero ROI.
- Compressing the launch cycle. An internal team might take three months to enrich a 10,000-SKU catalog. A professional internet research service, using a mix of human experts and automated data extraction, can often complete this in 10 to 14 business days.
- The “First-Mover” advantage. Being the first to list a new product line allows a brand to capture the initial “search intent” for that item. This builds early domain authority. By the time competitors finish their manual bulk product image collection, your brand has already secured the top organic spot and accumulated customer reviews.
- Agility in seasonal spikes. During Black Friday or Prime Day preparations, the ability to scale up high-volume image processing instantly is the difference between a record-breaking quarter and a logistical nightmare. Outsourcing provides the “elasticity” to handle 10x the normal volume without hiring a single new permanent employee.
Strategic Focus: Reclaiming the “Innovation Budget”
Perhaps the greatest ROI of an internet research service is the “Found Time” it gives to leadership.
- Opportunity cost reallocation. When Catalog Leads stop acting as “data cleaners” and start acting as “growth strategists,” the business evolves. Instead of spending 40 hours a week on market research for e-commerce visuals, they can focus on conversion rate optimization (CRO) or negotiating better terms with suppliers.
- Eliminating operational “Fluff”. Outsourcing removes the noise of micro-tasking. It allows the core team to focus on the “Value-Add” activities that actually move the needle on the stock price or company valuation.
Conclusion: Building a Scalable Future
In global retail, turning raw digital data into a structured catalog is a major competitive advantage. A dedicated internet research service acts as a powerful growth engine, helping e-commerce brands scale smoothly without burdening internal teams. These specialists bridge the gap between fragmented web data and a polished storefront. Whether you need visual data collection for AI or deep web research for SKU discovery, their speed and precision provide unmatched strategic value.
As the digital shelf becomes more crowded, the winners will be those who prioritize data integrity and speed-to-market. Entrusting your e-commerce data research to experts ensures that your internal leadership remains focused on core strategy, marketing, and customer acquisition, rather than being bogged down by the complexities of automated data extraction or manual attribute hunting. The synergy of human intelligence and advanced technology creates a scalable future where your catalog is always accurate, your visuals are always production-ready, and your brand is always first to the market.
Now is the time to eliminate operational “fluff” and build a data pipeline that supports your long-term vision. Connect with Tinkogroup to streamline your data collection and research workflows, ensuring your business stays ahead of the curve with a professional internet research service tailored to your unique requirements.
What is an Internet Research Service, and how is it different from a basic online search?
An Internet Research Service is a methodical way to gather, check, and sort data from various online sources. This turns information into useful business insights. Unlike a basic online search, this method goes deeper. It uses deep web research, normalizes data, and requires human validation. This ensures accuracy, completeness, and usability for business systems.
When should businesses outsource an Internet Research Service?
Businesses should outsource Internet Research Services when they have large data volumes. This helps with catalog scaling issues. It’s also useful for getting accurate datasets for AI and machine learning. It’s crucial during catalog migrations, busy times, or when teams struggle with data quality. This ensures speed without increasing costs or complexity.
What are the main benefits of outsourcing an Internet Research Service?
Outsourcing saves money by moving from CAPEX to OPEX. It also boosts data integrity with professional validation and normalization. This approach speeds up time to market and lets teams focus on strategic tasks rather than manual data work. It also provides scalability and access to advanced tools that are hard to keep in-house.


