

The development of large language models (LLMs) has impacted how machines comprehend and generate human language. From conversational AI (artificial intelligence) like ChatGPT to progressive translation tools, LLMs cover various language applications. But how do these models become proficient in understanding context, grammar, and meaning? The key lies in the complicated LLM training process.
By analyzing how these models are built, trained, and fine-tuned, we gain insight into the exceptional technology that enables machines to process natural language with increasing sophistication. This guide will demonstrate the main components, challenges, and innovations behind LLM training data. Let’s start our research!
The fundamentals of LLM training
Training an LLM is a sophisticated, multi-phase process created to enable AI systems to understand and generate human language. It’s crucial to grasp the fundamentals of their training process to appreciate how LLMs function fully.
LLM training feeds vast amounts of text data into a machine-learning (ML) model, enabling it to learn language patterns, structures, and context. The model uses advanced algorithms to predict text, answer questions, and perform various language-related tasks.
The video below provides an overview of the crucial LLM development stages. Its focus is on explaining how LLMs work by describing each step.
Main phases of LLM training
To train LLM with your own data, you need to move through the standard stages. Each phase is essential in developing a robust, flexible model capable of handling various language-based tasks.

1. Pretraining
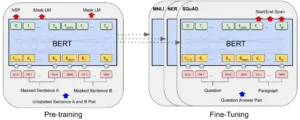
This is where the model learns the foundational aspects of language. The model learns to identify patterns, relationships between words, and sentence structures by analyzing massive text datasets. The goal during pretraining is to develop a general understanding of language that can later be fine-tuned for specific tasks. Pretraining is often unsupervised, meaning the model isn’t given specific instructions on what to learn but is exposed to vast amounts of data to internalize patterns.
A popular approach in this phase is the masked language model method, where parts of sentences are hidden, and the model is asked to predict the missing words. Through repeated exposure to varied text, the model starts to generate coherent and contextually appropriate predictions, which are the building blocks for its future capabilities.
2. Fine-tuning
After pretraining, the model moves into the fine-tuning phase, refined for more specific tasks. While pretraining provides a general understanding of language, fine-tuning ensures the model performs well in targeted applications like customer support, content generation, or machine translation. Fine-tuning uses supervised learning, providing the model with labeled datasets that guide it toward specific outcomes.
For example, if the goal is to create a chatbot, the model will be fine-tuned on datasets that mimic conversational exchanges. This stage tailors the model to perform well in a specific context, making it more accurate and reliable for particular use cases. During fine-tuning, the model also adjusts to handle edge cases or unique language patterns that weren’t fully covered during pretraining.
3. Evaluation and iteration
Once fine-tuning is complete, the model undergoes an evaluation process. The LLM’s performance is tested on various tasks to measure its effectiveness, accuracy, and ability to generalize across different contexts. This evaluation stage often involves benchmarking the model against established standards or tasks, ensuring it meets the necessary criteria for deployment.
Depending on the results, the model may experience iterative improvements, where feedback is incorporated to refine performance further. This cycle of evaluation and iteration ensures that the model is reliable, efficient, and free of significant errors or biases before being deployed in real-world applications.
Importance of diverse, high-quality training data
While phases of training LLM on custom data are critical, the quality and diversity of the data used during these phases are equally necessary. The performance of an LLM is directly influenced by the data on which it is trained.
A model’s ability to generalize well across different tasks hinges on the diversity of the data it’s exposed to. Diverse training data ensures the model can manage various linguistic patterns, dialects, and contexts. For instance, a chatbot trained exclusively on formal text from books may struggle with informal language or slang used in real-world conversations.
To address this, it’s important to incorporate various text sources (such as social media, formal writing, dialogues, and technical documents). This diversity improves the model’s ability to understand and generate text in various contexts and styles.
In addition to diversity, the quality of the LLM training data is critical. Poorly curated or low-quality data can introduce errors or biases into the model, reducing its reliability. For example, if a model is trained on misinformation or biased content, it may generate similarly flawed outputs. High-quality, carefully vetted data helps to minimize these risks, ensuring the model learns accurate and valuable language patterns.
For teams building large-scale training pipelines, it’s also worth considering the trade-offs between onshore vs offshore data annotation when sourcing labeled data at scale.
High-quality data also reduces the possibility of delusions—when the model generates incorrect or irrelevant information—by grounding the model’s training in reliable sources.
Best practices for effective LLM training process
Creating a powerful LLM requires careful planning and execution, especially during training LLM on custom data. Certain top practices must be followed to optimize the model’s ability to understand and generate text.
1. Curate high-quality and diverse data
The model’s performance is directly related to the quality and diversity of the data it processes. Therefore, curating high-quality and diverse data ensures the model’s effectiveness across various language tasks.
Quality matters
Ensure that the data used is accurate, up-to-date, and reliable. Avoiding noisy, incomplete, or biased data sources will reduce errors and the risk of model hallucinations—when the model generates incorrect or irrelevant information. High-quality data helps create a model that is consistent and reliable.
Diverse data sources
Incorporating a wide range of text sources allows the model to perform well in different contexts. For instance, using formal texts, informal conversations, social media content, technical documents, and user reviews provides the model with a comprehensive understanding of language use across domains. This diversity enables the model to adapt to different tasks, accents, or regional dialects, expanding its usability.
Balance and representation
While diversity is crucial, balance is equally important. Over-representing certain data types or under-representing others can introduce bias into the model. For example, if the LLM training data skews heavily toward formal English, the model might struggle with informal or conversational speech. Maintaining a balanced dataset is essential to creating a more inclusive and effective model.
2. Optimize model architecture and parameters
Choosing the right model architecture and tuning its parameters significantly affect the LLM training process. With advancements in deep learning frameworks, several models are available, including Transformer architectures like GPT, BERT, and others.
Right model architecture
Depending on the LLM’s end goal, choose the appropriate architecture. For instance, ChatGPT-3 is designed for generating coherent, human-like text in various applications, while BERT excels at understanding and completing sentence-based tasks. Selecting the right architecture at the outset aligns the model’s capabilities with the desired outcome.
Hyperparameter tuning
Fine-tuning hyperparameters such as learning rate, batch size, and optimizer is essential for improving model efficiency and accuracy. Small adjustments in these parameters during training can lead to substantial improvements in performance. Best practices involve monitoring these parameters through training experiments to determine the optimal setup.
Scaling up
Larger models typically perform better but require more resources. If possible, scaling the model architecture (i.e., adding more layers or parameters) often leads to better performance in understanding complex patterns. However, this must be balanced with the available computational power and training time.
3. Pretrain on a large scale
Pretraining on a large-scale, diverse corpus allows the model to build a solid foundation upon which more specific capabilities can be added during fine-tuning.
Unsupervised pretraining
In pretraining, models are often trained using unsupervised methods where the model learns language without labeled datasets. This allows it to internalize a broad understanding of word associations and sentence structure.
For example, masked language models like BERT train LLM to predict missing words in sentences, leading to a stronger grasp of context.
Training duration
Given the size of modern LLMs, pretraining may take weeks or even months, depending on the data volume and model size. It’s crucial to allocate enough time and computational resources to ensure the model fully absorbs the training data during this phase.
4. Employ transfer learning and fine-tuning
While pretraining offers a general language understanding, fine-tuning is essential to adapt the model to specific tasks. Transfer learning—a process where the pretrained model is reused and refined for a new task—allows the LLM to be efficient and task-specific.
Task-specific fine-tuning
Fine-tune the model on smaller, labeled datasets specific to the task. For example, if the model will be used as a customer support chatbot, fine-tuning it on real customer interactions and conversation logs improves its task performance. This practice narrows the model’s focus, making it more effective in solving domain-specific problems.
Tactics to minimize overfitting
While fine-tuning is beneficial, there’s a risk of overfitting, where the model performs exceptionally well on LLM training data but struggles with new inputs. Techniques like cross-validation and dropout regularization help avoid overfitting, ensuring that the model generalizes well in real-world applications.
5. Implement continuous evaluation and iteration
Training an LLM doesn’t end with fine-tuning. Continuous evaluation and iterative improvements are crucial for maintaining and enhancing the model’s performance.
Benchmarking
Regularly benchmark the model against industry standards and similar models to ensure it meets performance criteria. Depending on the model’s intended application, this can be done through automated testing on various language tasks, such as text generation, classification, or translation.
User feedback
Incorporating user feedback is another effective way to improve the model iteratively. Real-world users can identify areas where the model struggles, providing valuable insights for refining its performance.
Post-deployment monitoring
Once the model is deployed, it’s essential to monitor its behavior in production environments. Monitoring tools can track how well the model performs over time, highlighting areas that need adjustment or improvement.
Challenges and considerations in LLM training
Training an LLM presents challenges and considerations as its complexity grows alongside the demand for more accurate, scalable, and context-aware systems. Several aspects need careful attention to develop a reliable and fair model.

Data volume and quality
To train your own LLM, you can rely on diverse and comprehensive datasets to comprehend various linguistic patterns, but managing and processing such large amounts of data is resource-intensive. Moreover, guaranteeing the data’s high quality is critical. Poorly curated or biased data can lead to inaccurate or harmful outputs. It’s not just about quantity but quality—ensuring the data is free from errors, irrelevant information, or skewed representations is essential for building reliable models.
Computational resources and costs
Training LLMs demands significant computational power, which can be prohibitively expensive. Large-scale models like GPT-3 require vast amounts of GPU (graphics processing unit) or TPU (tensor processing unit) resources, increasing the cost of training and extending the time needed to complete it.
This can be a significant barrier for smaller companies or research teams. Beyond compute, data labeling itself can drive up your costs—here’s a breakdown of the true cost of annotating 10K labels and how to reduce it without sacrificing quality.
Additionally, as the model size grows, so do the hardware and energy requirements, raising sustainability concerns and making it challenging to balance performance with efficiency.
Ethical concerns and bias
Since LLMs are trained on large-scale datasets collected from the internet and other sources, they are likely to inherit any biases present in the LLM training data. This can lead to models that produce biased, harmful, or offensive outputs, especially in sensitive use cases like customer service or healthcare.
Developers must consider strategies for reducing bias, such as employing fairness algorithms and carefully curating datasets to reduce harmful stereotypes.
Overfitting and generalization
Another challenge is preventing overfitting, where the model performs well on LLM training data but struggles to generalize to new, unseen tasks. Striking a balance between training on specific tasks and ensuring the model is adaptable is vital.
Techniques such as cross-validation, regularization, and dropout can help, but this remains a constant challenge in LLM development.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Real-world applications and case studies
Training LLMs have seen outstanding success in real-world applications across industries, transforming how organizations use natural language processing (NLP) to solve complex challenges. LLMs are paving the way for more sophisticated interactions between humans and machines.
Customer support and virtual assistants
Companies like Google and Amazon use LLMs to power virtual assistants such as Google Assistant and Alexa. These models are trained on vast conversation datasets, allowing them to understand user queries and provide contextually accurate responses.
For example, Microsoft Azure’s AI platform provides a chatbot service that allows businesses to create intelligent virtual agents. One notable case is a major telecommunications provider that integrated LLM-powered chatbots to streamline customer service queries. By using Microsoft’s LLMs, the company reduced average response times by 30% and improved customer satisfaction scores.
Content generation and summarization
LLM training data have revolutionized content creation, with models like GPT-3 used to write articles, generate creative copy, and summarize documents. These models can mimic human writing styles and produce coherent text across different domains. For example, content generation platforms utilize LLMs to help writers and marketers quickly produce high-quality material.
Let’s talk about OpenAI’s GPT-3 for automated content creation. A media company used GPT-3 to assist in content creation for its news articles and blog posts. The company’s editorial team tasked the LLM with summarizing long-form articles and generating drafts for less complex stories. The result? A significant boost in productivity, with the model providing first drafts that only needed minor editing.
Education and language learning
The LLM training process also impacts education, especially language learning and personalized tutoring systems. By providing real-time feedback and interactive learning experiences, LLMs help learners improve their language skills. These systems adapt to individual learning styles, making education more accessible and customized.
For example, Duolingo, a popular language learning platform, integrated LLMs into its language lessons to offer more interactive and dynamic learning experiences. By analyzing user mistakes and learning patterns, the LLM adapts the course difficulty in real-time, providing personalized language challenges. This approach increased user engagement by 15% and improved learning outcomes, as users received immediate feedback and custom-tailored lessons based on their proficiency level.
Ecommerce and product recommendations
Ecommerce platforms greatly benefit from training LLM on custom data, using it for personalized product recommendations and customer engagement. By analyzing customer behavior, search history, and purchasing patterns, LLMs can recommend products tailored to individual preferences, improving user experience and boosting sales.
For instance, Shopify implemented LLMs in its recommendation engine to provide personalized product suggestions for its e-commerce clients. By integrating this AI-driven recommendation system, one of Shopify’s largest fashion retailers saw a 20% increase in conversion rates.
At Tinkogroup, our expert team played a crucial role in effective text labeling in commercial building. The project focused on categorizing commercial building permit descriptions to uncover patterns and trends within commercial construction activities. The aim was to provide deeper insights into how recent regulatory changes affected the sector.
By organizing the data, stakeholders could better understand shifts in construction volume, project types, and investment priorities. The result was a well-structured dataset that allowed the client to make informed decisions about future construction policies and market strategies based on reliable, data-driven insights.
Learn more about how our expertise can transform your business – check out our outstanding case studies.
Conclusion
In summary, training LLMs is a complex process that enables machines to engage with human language at an exceptional level. By mastering language structures, contextual understanding, and pattern recognition, LLMs can perform a wide range of tasks, from content generation to problem-solving.
If you’re looking to upgrade your AI projects with expert data processing and annotation services, our professional company is here to assist. With years of experience, we provide precise and scalable solutions to support your LLM training process needs. Contact us to boost your AI development!
What is LLM training?
Large language model (LLM) training teaches a machine learning (ML) model to understand and generate human language. These models are built using vast amounts of text data from books, websites, and other sources, which helps them recognize patterns, grammar, and context in language.
How do you train an LLM?
Training an LLM involves feeding large datasets to learn language structures and patterns. It starts with unsupervised learning, predicting words, or generating text. Fine-tuning adjusts the model using specific data, followed by validation to ensure accuracy, with iterative improvements as needed.
What are the phases of LLM training?
There are three main phases: pretraining (the model builds foundational learning of language patterns), fine-tuning (this stage adjusts the model to perform more effectively in specific applications), and evaluation and iteration (the model is evaluated on particular tasks to measure performance).
Is ChatGPT an LLM?
ChatGPT is a type of LLM developed by OpenAI. It is designed to understand and generate text based on its input. ChatGPT is trained on extensive text data and fine-tuned to perform well in conversational contexts, making it helpful in answering questions, generating content, and more.


