

What is the forefront of transforming how machines interact with human language? Central to this transformation is data labeling, a critical method that enables machines to understand, interpret, and generate human language effectively.
Natural language processing (NLP) data labeling involves annotating text data with specific tags and labels that serve as the foundation for training machine learning (ML) models. This process includes categorizing parts of speech, identifying points like names and locations, and assessing sentiment in text.
Accurate and consistent data labeling is essential for building robust NLP systems that perform language translation, sentiment analysis, and text classification tasks. As AI (artificial intelligence) continues to cover various industries, the demand for precise NLP data labeling has never been greater. Let’s explore this topic in more detail!
What is NLP data labeling?
Natural language processing data labeling is an essential process in artificial intelligence and machine learning, focusing on preparing textual data for model training. It concerns annotating or tagging text data with specific labels that provide context and meaning, enabling machines to accurately understand and process human language.
NLP data labeling is a mix of art and science, requiring human annotators with a deep understanding of language and context. The role of human annotators is critical in ensuring that the labels accurately reflect the intended meaning. Consistency and accuracy in labeling are paramount, directly impacting the quality and performance of the resulting machine-learning models.
In fact, NLP labeling transforms unstructured text into structured data that machine learning models can interpret. This transformation is vital for training models to perform language translation, sentiment analysis, and text classification tasks. For example, when developing a sentiment analysis tool, the text must be labeled as positive, negative, or neutral so the model can recognize these sentiments in new, unlabeled data.
Advancements in tools and platforms for data labeling have streamlined the process, allowing for greater scalability and efficiency. Automation and semi-automated approaches are also being explored to reduce the burden on human annotators while maintaining high standards of quality.
NLP data labeling is the basis for developing intelligent language models. It helps machines comprehend and interact with human language, driving innovations in AI applications that reshape industries and enhance everyday interactions. As the domain of NLP continues to increase, accurate and efficient data labeling will remain a vital factor in the success of AI-driven language solutions.
How does it work?
NLP data labeling is a systematic process that covers preparing and annotating text data to make it usable for machine learning models. Below is a precise look at how NLP labeling works:
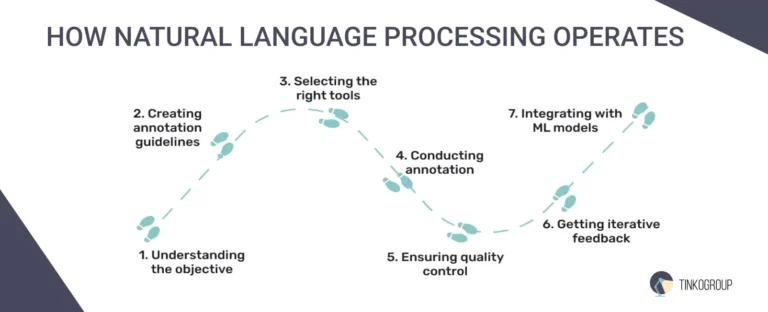
1. Understanding the objective
This involves determining the specific goals of the developed model, such as sentiment analysis, entity recognition, or text classification. Comprehending the end goal helps determine the types of labels needed and the level of granularity required in the labeling process.
2. Creating annotation guidelines
These guidelines for annotators are a blueprint, guaranteeing consistency and accuracy in the labeling process. They outline the specific labels to be used, how to handle ambiguous cases, and any applicable rules or exceptions. Clear guidelines help reduce annotation variability and improve the quality of the labeled data.
3. Selecting the right tools
Various tools and platforms are available for NLP data labeling, ranging from simple text editors to advanced annotation software. The choice of NLP labeling tools depends on the task’s complexity and the data volume. Some popular tools include Labelbox, Prodigy, and Amazon SageMaker Ground Truth. These advanced tools often include features like collaborative annotation, quality control mechanisms, and integration with machine learning workflows.
4. Conducting annotation
Human annotators or a combination of human and automated systems work for text data labeling according to the guidelines during the annotation process. Annotators read through the text and apply the appropriate labels, such as identifying parts of speech, tagging named entities, or marking sentiment. Automation can assist in speeding up the process, especially for repetitive or straightforward tasks, but human oversight is often required to handle more complex or nuanced cases.
5. Ensuring quality control
It involves reviewing and validating the labeled data to ensure accuracy and consistency. Techniques such as double-masked annotation, where multiple annotators label the same data independently, and inter-annotator agreement metrics are used to assess the reliability of the annotations. Any distinctions are resolved through discussion and consensus.
6. Getting iterative feedback
The NLP data labeling process is often iterative, with feedback loops to improve the quality and efficiency of the annotations. Annotators may receive feedback on their work, and guidelines may be updated based on insights gained during the labeling process. Continuous improvement helps refine the labeled data, leading to better model performance.
7. Integrating with ML models
Finally, the labeled data is integrated into the machine learning pipeline. It serves as the training data for models, allowing them to learn patterns and relationships within the text. The quality of the labeled data directly impacts the models’ accuracy and effectiveness, emphasizing the importance of a robust NLP data labeling process.
Main types of data labeling in NLP
Among the various types of NLP labeling, utterance, intent, and entity are key for building robust conversational AI systems and other language-based applications. We prepared an in-depth look at these three fundamental types of NLP data labeling:

Utterance
This NLP labeling type involves annotating individual expressions or statements made by users, typically in conversational AI or chatbot interactions. An utterance is a complete segment of text or speech that a user might input into a system. For example, an utterance in a customer service chatbot could be, “I need help with my account.”
Labeling utterances is crucial for capturing the variety of ways users might communicate their needs, which helps in training models to recognize and process diverse language patterns. Accurate utterance labeling ensures the system can handle phrasing and contextual variations effectively.
Intent
This type of NLP data labeling categorizes the purpose or goal behind a user’s utterance. It involves identifying what the user intends to achieve with their input, such as requesting information, making a reservation, or reporting an issue. For example, if a user says, “I want to book a flight,” the intent label might be “Flight Booking.”
In fact, intent labeling is fundamental for building dialogue systems and virtual assistants that can understand user queries and respond appropriately. By categorizing intents, models can provide relevant answers or perform specific actions based on the user’s needs, improving the overall user experience.
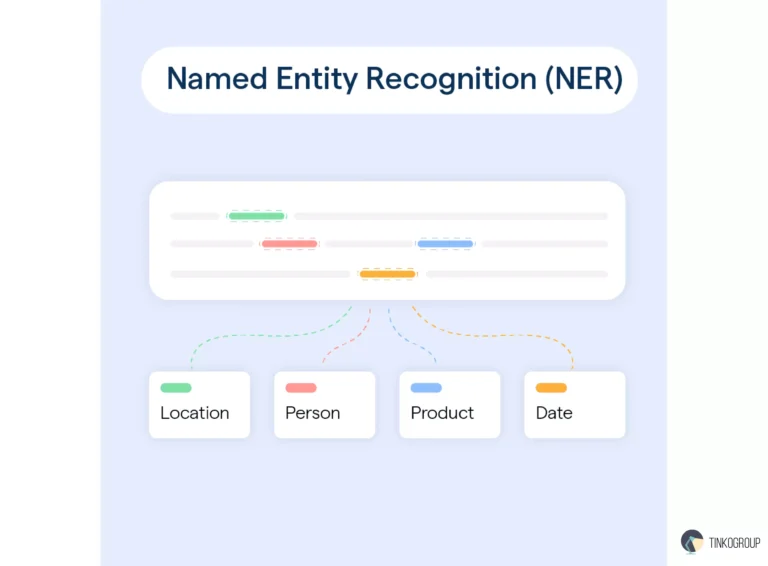
Entity
This NLP labeling type focuses on identifying and tagging specific pieces of information within an utterance that are critical for understanding the user’s request. Entities are usually vital elements such as names, dates, locations, or product names that provide context to the intent. For instance, in the utterance “I want to fly to New York on June 10,” the entities would be “New York” (a location) and “June 10” (a date).
Labeling entities helps models extract relevant details from user inputs, enabling them to perform tasks like booking flights or providing information based on specific user preferences. Entity recognition is essential for precise and contextual responses in conversational interfaces.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Understanding NLP data labeling costs
The NLP labeling process can come with significant costs, which vary depending on several factors. Analyzing these costs is important for budgeting and optimizing the data labeling process. Below is a detailed look at the key elements that influence NLP labeling costs:
Volume of data
Larger datasets require more extensive annotation efforts, which can increase costs proportionally. For example, labeling thousands of sentences or documents will generally cost more than labeling a few hundred due to the increased time and labor involved. Correctly estimating the data needed for your NLP labeling project and planning accordingly can help manage costs effectively.
Complexity of labeling tasks
The complexity of the NLP data labeling task also impacts costs. Simple tasks like binary sentiment classification (positive or negative) are less expensive than complex tasks like named entity recognition (NER) or multi-class classification, requiring a deeper understanding of the text and more nuanced annotations. More complicated tasks demand more skilled annotators and often involve additional quality control measures, increasing the overall cost.
Quality of annotations
Ensuring high-quality annotations is essential for the effectiveness of the NLP model. Higher-quality annotations require well-trained annotators and rigorous quality control processes, which can add to the cost.
Investing in thorough training and regular calibration of annotators, as well as implementing quality checks, helps maintain the quality of the labeled data but can also increase costs. The balance between price and quality is crucial, as poor-quality data can undermine the performance of your NLP models.
Progressive technology
The tools and technologies used for NLP data labeling can also affect costs. Advanced annotation platforms with features like automated suggestions, collaborative labeling, and integration with machine learning workflows may come with higher subscription fees or licensing costs.
However, these tools can enhance efficiency and reduce the time required for labeling, potentially offsetting some costs. Evaluating the trade-offs between tool capabilities and expenses can help you select the most cost-effective solution for your project.
Outsourcing vs. in-house labeling
Deciding whether to outsource or handle data labeling in-house can significantly impact costs. Outsourcing to specialized NLP data labeling companies like Tinkogroup can be cost-effective for large volumes of data or complex tasks, as these companies have the infrastructure and expertise to handle labeling efficiently.
On the other hand, in-house labeling might be more suitable for smaller projects or when a high degree of control and customization is needed. Weighing the pros and cons of each approach and considering factors like scalability, power, and cost efficiency is essential.
Project management and overheads
Project management (coordinating annotators, managing data security, and overseeing the labeling process) can also contribute to costs. Effective project management ensures that the NLP labeling process runs smoothly and data quality is maintained, but it requires resources and time. Allocating appropriate resources for project management helps minimize delays and ensure that the labeling process is completed on schedule.
Tinkogroup experience in data labeling
At our data labeling company, we take pride in our extensive experience in NLP data labeling. Our expertise spans a wide range of NLP labeling tasks, and our proven methodologies ensure that we deliver high-quality labeled data tailored to each project’s unique needs.
Tailored solutions for diverse needs
Whether you’re working on a chatbot, a sentiment analysis tool, or a language translation model, we tailor our data labeling services to align with your objectives. Our ability to adapt to different NLP labeling tasks and project scopes allows us to provide customized solutions that meet your needs effectively and efficiently.
Robust quality control processes
Providing the accuracy and reliability of labeled data is crucial for developing high-performing NLP models. Our company employs rigorous quality control measures to maintain the highest standards of data labeling.
We implement double-anonymized annotation processes, inter-annotator agreement assessments, and continuous feedback loops to ensure consistency and precision in our labeled datasets. This meticulous approach guarantees that our data meets the highest quality benchmarks and supports the success of your NLP applications.
Advanced tools
We employ advanced NLP data annotation platforms that streamline the labeling workflow and enhance efficiency. Our tools are equipped with features such as automated suggestions, collaborative annotation, and integration with machine learning pipelines, which optimize the labeling process and reduce turnaround times.
By staying at the forefront of technological advancements, we ensure that our data labeling services remain innovative and effective.
Experienced annotators and trainers
Our team consists of highly skilled annotators who deeply understand language and context in the labeling process. We invest in comprehensive training programs to keep our annotators well-informed about the latest labeling techniques and industry best practices. This expertise enables them to handle complex and nuanced labeling tasks accurately and consistently.
Commitment to data privacy and security
Data privacy and security are critical in our operations. To safeguard sensitive information, we adhere to stringent data protection protocols and comply with relevant regulations. Our commitment to maintaining data confidentiality ensures that your data is handled with the utmost care and integrity throughout the labeling process.
Conclusion
This NLP data labeling process supports the development of sophisticated AI models. It drives the innovation and accuracy needed for applications ranging from chatbots and virtual assistants to automated translation and sentiment analysis. The future of NLP labeling lies in creating more comprehensive labeled datasets, allowing machines to understand and process the complexities of human language with greater precision.
Unlock the full potential of your NLP labeling projects with our expert data processing services. Our experienced team ensures high-quality, consistent annotations to power your models. Contact us to learn how we can drive innovation in your business!
What is data labelling in NLP?
Data labeling in natural language processing (NLP) involves annotating text data with important tags that help machine learning models understand and process human language. This can include tagging parts of speech, identifying named entities like people/locations, and categorizing text sentiment.
What is data labeling for AI?
Data labeling for AI (artificial intelligence) is the process of annotating datasets to train machine learning models to make predictions/decisions based on input data. This involves adding informative tags or labels to data points (images, audio, or text), which serve as ground truth for the model.
Which are examples of data labeling?
Examples of data labeling include image labeling (tagging objects like cars and traffic signs), text annotation (marking sentiment in social media posts or labeling parts of speech), and audio annotation (transcribing speech to text or labeling sounds in audio data for recognition systems).
How to label text data for machine learning?
Text data labeling for machine learning involves several steps: defining the objective, creating annotation guidelines, selecting a labeling tool, training annotators, and conducting quality control.
Is data labeling hard?
Data labeling can be challenging due to several factors, including high accuracy, consistency among annotators, and handling large data volumes. Our experts carefully plan and execute, especially for complex tasks like understanding context in NLP or identifying subtle differences in image labeling.
What is a technique that uses data that is labeled?
Supervised learning is a technique that uses labeled data. It involves training a machine learning model on a labeled dataset to learn the relationship between input features and output labels. Supervised learning is used for tasks like image classification.


