

In the vast world of data, two essential concepts are crucial in enhancing machine learning (ML) algorithms – data labeling and annotation. These terms may sound similar, but they each bring unique elements. Consider your data a puzzle. These processes are essential for unlocking its full potential. Let’s explore the main differences between data annotation and labeling to clarify their distinct roles in enhancing the effectiveness of information for artificial intelligence (AI) systems.
So, what is data labeling and annotation?
Data labeling
In general, data labeling is the act of marking information, or rather metadata, according to a specific data set to focus on increasing machine understanding. Simply put, data labeling selectively classifies data, images, text, audio, video, and patterns to improve AI implementations.
According to the report, the data labeling market is expected to grow to USD 5.5 billion by 2026 and register more than 30% CAGR throughout the forecast period.
Data labeling is a detailed process that includes the following steps for categorical training of AI models:
- Collecting data sets using strategies such as in-house, open-source, and vendor.
- Label datasets based on computer vision, deep learning, and NLP (natural language processing) capabilities.
- Testing and evaluating produced models to determine deployment intelligence.
- Satisfying the acceptable quality of the model and ultimately releasing it for general use.
Types of data labeling
Different types of data require distinct labeling methods to ensure accurate model development. Here, we delve into various data labeling techniques for diverse data types:
Image tagging
It involves associating descriptive keywords or labels with specific elements in an image. This facilitates the recognition of objects, scenes, or characteristics within the image. For example, labeling a photograph of a beach might include tags such as “ocean,” “sand,” and “umbrella.”
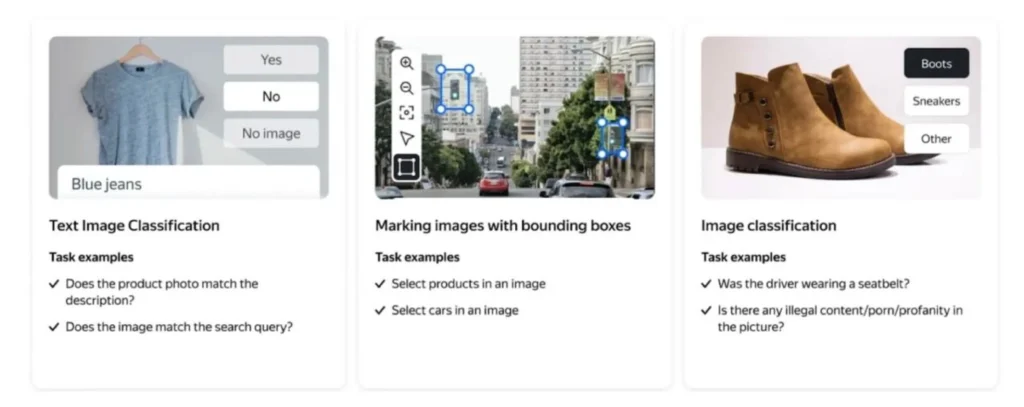
Audio classification
Each audio data segment is labeled according to the sound it represents. This could involve identifying genres in music, distinguishing between different spoken languages, or classifying environmental sounds like footsteps or bird chirps.
Video annotation
It extends the concept of image tagging to the temporal domain. It involves labeling objects, events, or actions within a video sequence. This is crucial for video surveillance, autonomous vehicles, and action recognition applications.
Text summarization
This type involves condensing large blocks of text into concise and coherent summaries. The labeling process here includes identifying key sentences, extracting essential information, and capturing the text’s overall meaning.
Object recognition
It focuses on identifying and labeling specific objects within an image. This goes beyond image tagging by requiring precise localization of objects.
Instance segmentation
This type takes object recognition a step further by identifying objects and distinguishing between separate instances of the same object. For example, in a picture with multiple people, instance segmentation would label each person individually.
Semantic segmentation
It involves labeling each pixel in an image with a class label, providing a detailed understanding of the scene. This is particularly useful in applications like medical imaging, where differentiating between tissues or structures is critical.
Sentiment analysis
This type focuses on determining the emotional tone expressed in a piece of text. Labeling in sentiment analysis involves categorizing text as positive, negative, or neutral. This is widely used in social media monitoring, customer feedback analysis, and market research.
Main benefits
In artificial intelligence and machine learning, data labeling is the secret weapon that makes everything work better. Let’s talk about the critical advantages of data labeling.
Cost-effectiveness
Companies can significantly reduce the time and resources traditionally associated with manual annotation through automated and streamlined labeling processes. Additionally, a well-labeled dataset improves the learning efficiency of machine learning models, minimizing the need for extensive fine-tuning and reiteration.
Flexibility
Whether it’s image recognition, natural language processing, or any other AI application, the labeling framework can be tailored to meet specific needs. Furthermore, as data volumes grow, scalable labeling solutions enable organizations to seamlessly expand their datasets, ensuring that machine learning models remain relevant and effective in dynamic environments.
Access to skilled experts
By using the expertise of professionals in data science and domain-specific knowledge, companies can elevate the precision of their machine-learning models. This access to skilled experts not only refines the labeling process but also contributes to the overall success of AI applications.
Improved accuracy and quality control
Data labeling enhances accuracy by providing explicit annotations and facilitates robust quality control mechanisms. Through systematic validation processes and continuous refinement, companies can identify and rectify labeling errors, ensuring that the models are trained on high-quality datasets.
Now, let’s move on to another block in the data annotation vs. data labeling battle – we will explain the essence of data annotation with its common types and essential benefits.
Data annotation
In artificial intelligence and machine learning, data annotation is fundamental in preparing and enriching datasets. This involves the process of labeling and categorizing the data, giving important context and meaning to the raw data. What is the essence of data annotation, its purpose, methods, and significance in advancing AI?
Data annotation is the practice of adding metadata, labels, or tags to raw information that makes it understandable and suitable for machine learning algorithms. It bridges the gap between unstructured and structured data needed for AI models. Data annotation involves the application of human knowledge and intelligence to interpret, classify, or label certain features, objects, or characteristics in a dataset.
Thus, annotating data is essential in AI, contributing to various applications such as computer vision, processing, and speech recognition. By realizing the importance of high-quality annotations and using best practices, we can unlock the full potential of AI and drive innovation across industries.
Types of data annotation
Various types of data annotation techniques are employed across different modalities to enhance the understanding and performance of machine learning models. Let’s check the key types of data annotation:
Text annotation
In fact, this type involves labeling and highlighting specific information within textual data. This can include sentiment analysis, named entity recognition, or any other task where identifying and categorizing text elements is crucial.
Video annotation
It is the process of labeling objects, actions, or events within video frames. This can range from identifying and tracking objects over time to annotating specific actions or behaviors within the video sequence.
Image annotation
This type of data annotation includes labeling objects, regions, or features within an image, enabling machine learning models to recognize and understand visual elements.
Audio annotation
It involves labeling different audio data segments, such as speech recognition, sound classification, or identifying specific events within an audio clip.
Semantic segmentation
This segmentation involves labeling each pixel in an image with a corresponding class, creating a detailed and precise understanding of the objects and their boundaries within the image.
Bounding boxes
This type of data annotation is a widely used technique for object detection and localization. It involves drawing rectangles around objects of interest within an image, providing a spatial reference for the model.
3D cuboids
It is essential for tasks involving three-dimensional space, such as autonomous driving. This type entails labeling objects with three-dimensional rectangular boxes, allowing models to perceive depth and size accurately.

Polygon annotation
This type of data annotation involves outlining the contours of objects with irregular shapes. Moreover, this technique is particularly useful when dealing with objects that cannot be accurately represented by rectangles, providing a more nuanced understanding of their boundaries.
Thus, each type of data annotation serves a specific purpose, catering to the diverse needs of machine learning applications across different domains.
Regarding the data annotation vs. data labeling battle, it is now essential to discover what advantages data annotation has.
Crucial advantages
What is the significance of data annotation? It plays a vital role in the development and training of AI models. Here are some key reasons why data annotation is essential:

- Training AI models: Annotated data is the basis for training AI models. By providing labeled examples, data annotation allows algorithms to learn patterns, make predictions, and generalize from training data.
- Algorithm validation: Such data is essential for evaluating the performance and accuracy of AI algorithms. By comparing the predictions made by the model with the values annotated by humans, the efficiency and reliability of the algorithm can be evaluated.
- Improved performance: Quality annotated data improves the performance and accuracy of AI models. Accurate and detailed annotations provide the necessary signals for learning algorithms to make informed decisions, leading to reliable and accurate predictions.
Hence, data annotation is at the heart of AI development, allowing algorithms to learn, understand, and make accurate predictions. Through the process of labeling and categorizing data, the unstructured becomes structured, providing AI models with meaningful insights and actionable solutions.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Data labeling vs data annotation: comparing table
In the field of data-driven technologies, the accurate interpretation and utilization of data play a pivotal role. Two key processes contributing significantly to this are data labeling vs. annotation. While often used interchangeably, these terms encompass distinct methodologies with unique purposes.
Let’s delve into a comparative table highlighting the critical aspects of data annotation vs. data labeling to shed light on their main differences.
| Criteria | Data labeling | Data annotation |
| Definition | Assigning descriptive labels to data points, typically for supervised learning tasks. | Adding metadata or explanatory notes to enhance the understanding of data, making it more comprehensible for machine learning models. |
| Application | Commonly used in image and speech recognition, where labeled data is crucial for training algorithms. | Widely applied in various domains such as computer vision, natural language processing, and object detection to provide context and meaning to data. |
| Objective | Enhances the predictive capabilities of machine learning models by providing labeled examples for training. | Improves data comprehension by adding contextual information, aiding in better model interpretation and decision-making. |
| Scope | Primarily focuses on categorizing and classifying data into predefined labels. | Encompasses a broader spectrum, including bounding box annotations, keypoint annotations, and semantic segmentation, depending on the complexity of the data. |
| Human involvement | Requires human annotators to apply predefined labels accurately. | Involves annotators who not only label data but also add contextual information, requiring a deeper understanding of the data. |
| Use cases | Image recognition, speech-to-text, sentiment analysis. | Autonomous vehicles, medical image analysis, language translation. |
| Tools | Utilizes labeling tools that facilitate the assignment of predefined labels to data points. | Requires advanced annotation tools capable of handling various annotation types, such as bounding boxes, polygons, and text. |
| Output | Labeled datasets that serve as input for training machine learning models. | Annotated datasets provide a richer understanding of data, aiding model interpretability and decision-making. |
| Purpose | Enhances model accuracy by providing clear input labels for training. | Enriches data with contextual information, improving model understanding and decision-making. |
| Level of detail | Focuses on predefined labels, offering a more straightforward classification approach. | Allows for nuanced detailing, including object boundaries, relationships, and intricate features within the data. |
| Expertise required | Generally requires less specialized knowledge, as it involves assigning predefined labels. | Demands a higher level of expertise, with annotators needing a deeper understanding of the data context and domain-specific intricacies. |
Thus, understanding the nuances between data labeling and data annotation is crucial. While data labeling primarily focuses on categorization, data annotation goes beyond enriching the data with contextual information. Both processes play vital roles in enhancing the performance and interpretability of machine learning models, making them indispensable in the pursuit of accurate and meaningful insights from data.
Valuable methods and techniques of data annotation and labeling
The importance of accurate and well-annotated data cannot be overstated. Data annotation and labeling are critical in training machine learning models, enabling them to recognize and understand patterns, objects, and relationships. Let’s check common methods and techniques of data labeling and annotation.

Manual annotation
It is one of the oldest and most reliable methods, where human annotators meticulously label data points. This approach is often used for complex tasks that require human intuition, such as image recognition, sentiment analysis, or speech-to-text transcription. While accurate, manual annotation can be time-consuming and demand substantial human resources.
Semi-supervised learning
To alleviate the challenges posed by manual annotation, semi-supervised learning employs a combination of labeled and unlabeled data. This method allows algorithms to learn from more minor annotated data and then apply that knowledge to unlabeled data. This approach is beneficial when acquiring labeled data on a large scale is impractical or expensive.
Active learning
It takes a strategic approach by allowing the machine learning model to select the most informative data points for annotation. The algorithm actively seeks feedback from the user, who then annotates the chosen data. This iterative process optimizes the model’s performance with minimal annotation efforts, making it an efficient choice for resource-constrained projects.
Transfer learning
This method involves pre-training a model on a large dataset and then fine-tuning it on a smaller dataset with specific annotations. Transfer learning capitalizes on the knowledge gained during the initial training, reducing the need for extensive annotation on the target dataset. This method is particularly advantageous when working with limited annotated data.
Crowdsourcing
It taps into the collective intelligence of a diverse group of individuals to annotate large datasets swiftly. Platforms like Amazon Mechanical Turk allow tasks to be distributed to a crowd of workers, making it a cost-effective solution for projects with massive amounts of data. However, maintaining quality control and ensuring consistency in annotations can be challenging with this method.
Weak supervision
It involves using heuristics, rules, or domain knowledge to generate noisy labels for the data. While the labels may not be entirely accurate, the model can still learn valuable patterns. This method is handy when obtaining precise annotations is difficult or expensive.
Automated annotation
It relies on algorithms to generate labels for data without human intervention. This method is effective for tasks where patterns are well-defined and machines can quickly identify patterns. However, the accuracy of automated annotation heavily depends on the task’s complexity and the algorithm’s quality.
Common challenges and limitations
Like any process, data labeling and annotation come with their fair share of challenges and limitations. Let’s check them together.
- Need for skilled annotators: Finding and maintaining a team of skilled annotators for data labeling is a significant challenge, as it requires individuals who can consistently interpret data accurately. Training and retaining such personnel can be time-consuming and expensive, which is why it’s important to develop clear annotation guidelines for annotators to ensure consistency and reduce ambiguity.
- Subjectivity in labeling: The subjective nature of labeling poses a challenge, with different annotators interpreting the same data differently. This subjectivity can result from variations in perspectives, background knowledge, and mood, leading to inconsistencies in labeled datasets.
- Scalability issues: Manual labeling becomes impractical as datasets grow in size. Although automated labeling solutions are being explored, achieving high accuracy and adapting to diverse datasets remain ongoing challenges. Balancing manual and computerized approaches is crucial for efficiency.
- Maintaining data quality: Ensuring data quality and relevance over time is a concern. As models evolve, labeled datasets need continuous updates. Outdated or biased datasets can limit a model’s ability to adapt to new information, affecting its effectiveness.
- Privacy and ethical considerations: Annotating sensitive or personal data raises privacy and security concerns. Striking a balance between collecting enough information for effective machine learning and respecting privacy rights requires careful consideration, often involving legal and ethical considerations.
- Cost constraints: The cost associated with data labeling, from hiring and training annotators to investing in technology and infrastructure, can be a significant limiting factor. This financial burden may pose challenges, especially for smaller organizations or projects with tight budgets.
Thus, overcoming these hurdles requires a combination of technological innovation, ethical awareness, and a strategic balance between human and automated processes. As the field evolves, addressing these challenges will be crucial for unlocking the full potential of machine learning applications.
Advanced tools for data labeling and annotation
When choosing the proper data labeling vs. annotation toolset, which is synonymous with a robust data labeling platform, the following factors need to be considered:
- The type of intelligence you want the model to have through certain use cases;
- The quality and experience of data annotators so that they can use the tools with accuracy;
- Your quality standards;
- Compliance requirements;
- Commercial, open-source, and free tools;
- The budget you have.
Tools for data labeling and annotation:
- Amazon SageMaker Ground Truth,
- SuperAnnotate,
- Labelbox,
- Supervisely,
- Kili,
- LabelImg,
- RectLabel,
- Filestage,
- VGG image annotator,
- LabelMe.
Our vast expertise in data labeling and annotation
Now is the time to tell you about our experience in delivering data labeling and annotation services.
Tinkogroup is a leading data labeling outsource company that prioritizes quality, adheres to schedules, and delivers results beyond client expectations. The team consists of professionals skilled in various data labeling services. Our offerings include image labeling, text summarization, audio classification, video annotation, product categorization, semantic and instance segmentation, object recognition, landmarks, and attribute categorization.
We use diverse data labeling software (CVAT, LabelBox, Imglab, LabelMe, Sloth, etc.) and provide expertise in road damage extraction, autonomous driving, real estate recognition, e-commerce, urban settings, and more. Thus, clients describe working with Tinkogroup in the data labeling field as comfortable and profitable.
Tinkogroup also delivers data annotation services in the USA and beyond, and for those focused on the UK market, here’s a curated list of data annotation companies based in the UK that are worth considering. We specialize in data classification, enjoying tasks related to order and clarity. Our company is skilled in collecting, cleaning, validating, and tagging information.
The projects we create include data annotation outsourcing for various industries such as insurance, technology, traffic, e-commerce, and marketing. At Tinkogroup, we prioritize quality, professionalism, and adherence to agreements.
Our data annotation services cover a range of tasks, including data tagging and classification for images, labeling for voice systems used in chatbots and speech recognition, categorization for text projects, and processing video materials. It also includes semantic segmentation, bounding box tools for object classification, polygon annotation, 3D cuboids for understanding volumetric dimensions, lines and splines for accurate boundaries, and landmark labeling for movement trajectory.

Conclusion
While data annotation and labeling are often used interchangeably, they play distinct roles in data science. Data labeling involves assigning meaningful labels to specific data points, making it easier for machines to understand and learn from the information. On the other hand, data annotation goes beyond labeling by adding additional context or information to the data, enhancing its overall quality and usefulness.
In general, both processes are crucial for effectively training machine learning models, as they contribute to creating robust and accurate algorithms. Whether it’s identifying objects in images or recognizing patterns in text, the careful combination of data labeling vs. annotation ensures that AI systems can make informed decisions. As the field continues to evolve, a clear understanding of the differences between these two practices will be essential for using the full potential of artificial intelligence.
Ready to elevate your data game? Trust us to deliver precise data labeling and annotation services tailored to your unique business needs. Let’s transform your raw data into a valuable asset for cutting-edge AI applications. Contact Tinkogroup today to start a data-driven future here!
FAQ
What is data labeling and annotation?
Data labeling is the process of assigning meaningful and descriptive labels or tags to different elements within a dataset. Data annotation goes beyond labeling by adding additional information or context to the labeled data.
How does data annotation differ from data labeling?
Data labeling primarily involves assigning labels or tags to different elements in a dataset. It is about categorizing and identifying specific features within the data. Data annotation extends beyond mere labeling by providing additional layers of information.


