Audio data has become valuable across various industries, from tech and entertainment to healthcare and education. The growth in applications like voice recognition systems or automated transcription services underscores the importance of accurately interpreting and using audio content. Audio data annotation involves labeling and categorizing audio recordings to train machine learning models, enabling them to understand, process, and respond to human speech and other sounds.
As we analyze audio annotation, we discover its key role in shaping the future of voice-driven technologies and its profound impact on various sectors. Let’s get started!
Audio data annotation: definition and importance
Voice annotation plays a crucial role in artificial intelligence (AI) and machine learning (ML). But what is audio data annotation? In a nutshell, audio data annotation is the process of labeling and categorizing audio recordings to create datasets from which machines can learn. This process involves identifying and tagging elements within an audio file, such as speech, music, ambient sounds, and even silence. These annotations provide context and structure to the audio data, enabling machine learning algorithms to understand and interpret auditory information more accurately.
Now, let’s check main advantages of audio annotation:
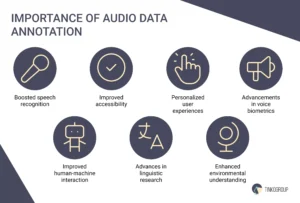
Boosted speech recognition
Audio annotation significantly improves the accuracy of speech recognition systems. By providing detailed annotations of speech patterns, phonemes, and contextual nuances, annotators enable AI models to understand and transcribe spoken language better. This is particularly important for applications like virtual assistants, automated transcription services, and language learning apps, where precision in recognizing and processing speech is paramount.
Improved accessibility
Annotated audio data is instrumental in developing technologies that enhance accessibility for individuals with disabilities. For example, detailed speech annotations help create more accurate and responsive speech-to-text applications, which can be invaluable for the hearing impaired. Similarly, audio annotations assist in refining text-to-speech systems, making them more natural and intuitive for visually impaired users.
Personalized user experiences
Companies can create more personalized and engaging user experiences by employing annotated audio data. Annotations that capture nuances in speech, such as tone and emotion, enable AI systems to respond more contextually. This is particularly beneficial in customer service applications, where understanding a user’s emotional state can lead to more effective and satisfying interactions.
Advancements in voice biometrics
Voice biometric systems rely heavily on annotated audio data to accurately verify and authenticate users based on their unique vocal characteristics. Detailed annotations that include various speech attributes, such as pitch, cadence, and accent, help these systems differentiate between exact individuals. This enhances security in applications like banking, secure access systems, and personal devices.
Improved human-machine interaction
Many AI systems aim to facilitate more natural and intuitive human-machine interactions. Audio annotation is critical to achieving this, as it enables machines to better understand human speech patterns, contextual cues, and even non-verbal sounds. This leads to the development of more responsive and human-like AI assistants and interactive systems.
Advances in linguistic research
Audio annotation also contributes to advancements in linguistic research. Researchers can gain deeper insights into language structures, evolution, and usage by providing detailed annotations of various languages, dialects, and speech patterns. This, in turn, informs the development of more sophisticated and inclusive language models and translation systems.
Enhanced environmental understanding
Beyond speech, audio data annotation is crucial for systems that interpret environmental sounds. This includes applications in smart homes, security systems, and autonomous vehicles. By annotating sounds such as alarms, footsteps, or engine noises, these systems can better understand and respond to their surroundings, enhancing safety and efficiency.
Common types of audio annotation
The types of voice annotation are diverse, each tailored to meet specific needs and applications. Below are the various types of audio annotation, illustrating their significance and how they contribute to the development of sophisticated auditory AI systems.
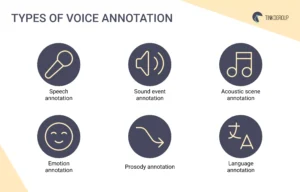
Speech annotation
This is one of the most common types of audio annotation, focusing on transcribing spoken words within an audio file. It includes:
- Phonetic annotation: Marking individual phonemes (the smallest sound units in speech) within a recording. This is crucial for speech recognition systems, enabling them to understand and differentiate between subtle phonetic variations.
- Word-level annotation: Transcribing audio at the word level, providing a clear representation of spoken language. This is essential for applications like automated transcription services and virtual assistants.
- Sentence-level annotation: Identifying and marking complete sentences within a speech. This helps in understanding the context and structure of spoken language, which is important for natural language processing (NLP) applications.
- Speaker diarization: Differentiating and tagging parts of an audio recording based on who is speaking. This annotation type is essential for multi-speaker environments, such as meetings or interviews, allowing AI to attribute speech to each speaker correctly.
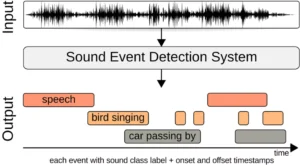
Sound event annotation
This process involves identifying and labeling specific sounds within an audio recording, such as event detection, temporal annotation, and categorical audio annotation.
Event detection is about marking the occurrence of distinct sound events, such as doorbells, sirens, or footsteps. It is critical for applications in security systems, smart home devices, and environmental monitoring.
Temporal annotation covers tagging sound events’ exact start and end times within a recording. This precision is critical for real-time sound detection systems and for training AI models to recognize the duration and context of sounds.
Categorical annotation involves classifying sounds into predefined categories, such as human speech, animal sounds, mechanical noises, etc. This type of voice annotation helps build comprehensive sound databases and for applications in sound classification and recognition.
Acoustic scene annotation
Below are two main categories of acoustic scene annotation:
Scene classification
Labeling audio recordings based on the type of environment, such as a busy street, a quiet park, or a bustling cafe. This is useful for context-aware applications and for enhancing the environmental understanding of AI systems.
Contextual annotation
Providing additional context about the recording environment, such as the presence of multiple overlapping sounds or specific background noises. This helps AI systems to better interpret and react to complex auditory scenes.
Emotion annotation
This type of voice annotation involves tagging audio data with emotional labels to capture the sentiment or emotional state expressed in the recording. This includes basic emotion labeling and complex emotion annotation.
Basic emotion labeling is about identifying fundamental emotions such as happiness, sadness, anger, or fear within speech. This is important for applications in customer service, sentiment analysis, and mental health monitoring.
On the other hand, complex emotion annotation covers recognizing and labeling more nuanced emotional expressions, such as sarcasm, frustration, or enthusiasm. This adds depth to AI’s understanding of human emotions and improves interactions in emotionally sensitive applications.
Prosody annotation
The prosody voice annotation focuses on the rhythm, stress, and intonation of speech. This includes:
- Pitch annotation: Marking variations in pitch throughout the speech, which is important for understanding intonation patterns and for applications in language learning and speech synthesis.
- Stress and emphasis annotation: Identifying words or syllables that are stressed or emphasized in speech. This helps in understanding speech dynamics and improving naturalness in text-to-speech systems.
- Rhythm and pauses annotation: Tagging rhythmic patterns and pauses in speech. This audio annotation type is crucial for improving the fluency and naturalness of synthetic speech and for better understanding conversational dynamics.
Language annotation
Language annotation involves labeling audio recordings based on the language spoken. This includes:
Monolingual annotation
Tagging recordings where a single language is spoken. This is essential for building language-specific datasets for speech recognition systems.
Multilingual annotation
Identifying and labeling multiple languages within a single recording. This is critical for developing multilingual speech recognition and translation systems.
Comprehensive audio annotation process
This detailed process ensures that machines can accurately interpret and respond to auditory information, leading to more sophisticated and practical AI applications. Here is the voice annotation process detailing each step and its significance in developing intelligent auditory systems.

1. Data collection and preparation
This involves gathering diverse audio recordings relevant to the specific application or research project. The quality and variety of the audio data are crucial, as they directly impact the effectiveness of the resulting AI model. Data sources can include naturalistic recordings, controlled recordings, and synthetic data (generating artificial audio using software to simulate specific sounds or speech patterns).
Once the data is collected, it needs to be prepared for voice annotation. This involves the following steps:
- Quality checking: Ensuring the audio recordings are clear, free of excessive noise, and appropriately formatted.
- Segmentation: Dividing long audio recordings into smaller segments. This makes the annotation process more efficient and precise.
2. Annotation execution
With guidelines in place and tools ready, this step involves labeling and categorizing the audio data by trained annotators. The audio annotation process typically includes:
Listening and identification
Annotators listen to the audio segments and identify specific elements based on the guidelines. This can include recognizing phonemes, words, sounds, or emotional tones.
Label application
Applying the appropriate labels to the identified elements within the audio segments. Annotators must ensure accuracy and consistency in their labeling.
Temporal marking
Marking the start and end times of specific sounds or speech elements. This is particularly important for time-based annotations, such as phonetic or sound event annotations.
3. Quality assurance and review
Checking the quality is a critical step in the audio annotation process. Quality testing involves reviewing the annotated data to ensure accuracy, consistency, and completeness. This step typically includes peer review, automated checks, and consensus building.
Peer review covers having multiple annotators review each other’s work to identify and correct any errors or inconsistencies. Next, automated checks involve using software tools to automatically detect and flag potential issues, such as mislabeled segments or missing annotations. Then, consensus building is about resolving discrepancies through discussion and consensus-building among annotators to ensure a unified annotation standard.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

4. Data integration and finalization
Once the annotated data has passed the quality assurance checks, it is integrated into the larger dataset. This step involves:
- Data aggregation: Combining individual annotated segments into a cohesive dataset that can be used for training AI models.
- Format conversion: Ensuring the annotated data is in the appropriate format for the intended application, such as converting to specific file types or database structures.
- Metadata addition: Adding relevant metadata to the annotated data, such as annotation timestamps, annotator IDs, or quality scores, to facilitate future reference and analysis.
5. Model training and validation
The final step in the audio annotation is using the annotated data to train and validate AI models. It is about:
Model training
Feeding the annotated data into machine learning algorithms to develop models that can recognize and interpret audio elements.
Validation and testing
Evaluating the performance of the trained models using a separate validation dataset. This step ensures that the models are accurate, reliable, and generalizable.
Continuous improvement
Iteratively refining the models and the annotation process based on validation results and real-world feedback. This may involve collecting additional data, revising annotation guidelines, or improving audio annotation tools.
Main challenges of audio annotation
Like any complex data annotation task, annotating audio data presents several challenges that can impact the annotation process’s accuracy, efficiency, and scalability. Below, we prepared the key challenges of voice annotation and discussed strategies to address them.

Subjectivity and interpretation
Unlike text or image annotation, where boundaries and features are often more clearly defined, audio annotation involves capturing nuances such as accents, speech variations, and emotional tones. Different annotators may interpret these nuances differently, leading to inconsistencies in annotation quality.
Solution: Establishing clear voice annotation guidelines and providing annotators with training sessions can help mitigate subjectivity. Using reference datasets and conducting regular inter-annotator agreement tests can also ensure consistency across annotations.
Quality of audio data
The quality of audio recordings can vary significantly, impacting the annotation process. Poor audio quality, background noise, overlapping speech, and low recording fidelity can make it challenging for annotators to identify and label speech or sound events accurately.
Solution: Pre-processing audio data to remove noise and enhance clarity can improve annotation accuracy. Advanced audio editing tools and noise reduction techniques can also help clean up audio recordings before annotation.
Annotation granularity
Another challenge is determining the appropriate level of annotation granularity. Depending on the application, annotations may need to capture phonetic details, word boundaries, emotional cues, or environmental sounds. Balancing detail with practicality and ensuring voice annotations align with the project’s specific goals can be complex.
Solution: Tailoring audio annotation guidelines to match the project requirements is essential. Breaking down complex annotations into manageable tasks and prioritizing annotations that provide the most value to the AI system can streamline the process.
Scalability and volume
Handling large volumes of audio data efficiently poses significant challenges. As datasets grow, annotating each audio segment manually becomes time-consuming and resource-intensive. Scaling annotation efforts while maintaining consistency and quality is a common hurdle.
Solution: Implementing automated or semi-automated audio annotation tools can help increase throughput and reduce manual effort. Using machine learning techniques for initial labeling or pre-annotation can also speed up the process without compromising accuracy.
Privacy and ethical considerations
Audio annotation may raise privacy concerns, especially when dealing with sensitive or personal information in conversations or recordings. Ensuring data anonymization and strict data protection measures are essential to maintaining privacy and ethical standards.
Solution: Following data protection regulations such as GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act), obtaining informed consent from participants, and anonymizing sensitive information before annotation are critical steps. Implementing secure data handling practices and conducting regular audits can further mitigate privacy risks.
Audio annotation services at Tinkogroup
Audio data annotation is a critical process that enables the development of sophisticated AI and ML systems capable of understanding and interpreting sound. Our data annotation company offers a comprehensive range of audio annotation services tailored to meet our client’s diverse needs. If you’re looking for regional partners, check out some of the top data annotation companies in the UK known for delivering high-quality voice annotation services for AI and ML applications.
Choosing our voice annotation services comes with numerous benefits that enhance the quality and effectiveness of your projects:
Industry expertise
Our team consists of highly skilled annotators with extensive experience in audio data annotation. We understand the nuances of different types of audio data and ensure precise and consistent labeling.
Advanced technologies
We use progressive annotation tools and platforms to ensure the accuracy, efficiency, and scalability of our services. Our technology enables us to handle large volumes of data while maintaining high-quality standards.
For example, you can employ Praat within various annotation tools. This is a universal tool primarily used for speech and acoustic signal analysis. Although it is not solely dedicated to annotation, it provides features for labeling and analyzing sound data, making it valuable for audio annotation projects.
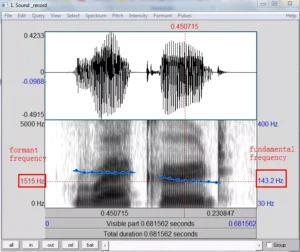
Praat’s capabilities include the detailed annotation of phonetic and acoustic characteristics, making it a valuable tool for researchers and linguists working on speech-related projects. Also, Praat offers scripting capabilities, enabling users to automate repetitive annotation tasks and streamline the overall voice annotation process.
Customized solutions
We recognize that every project is unique, and we tailor our services to meet each client’s specific needs. Whether you require detailed phonetic annotations or broad acoustic scene labeling, we provide solutions that align with your goals.
Quality assurance
Our specialists implement rigorous processes to ensure our annotations are accurate, consistent, and reliable. Our multi-layered review system includes peer reviews and automated checks to maintain the highest quality standards.
Scalability
Our services are designed to scale with your needs. Whether you have a small project or require large-scale annotations, we can deliver high-quality results.
Timely delivery
We understand the importance of meeting deadlines. Our efficient workflow and dedicated team ensure we deliver the audio annotation services on time without compromising quality.
When outsourcing your audio data annotation needs, it’s essential to be informed—use this guide on how to evaluate a data annotation vendor to ensure your project is in the right hands.
Bottom line
The future of technology is increasingly voice-driven, and the detailed work of audio data annotation is at the heart of this evolution. By transforming raw audio into structured data, we enable machines to better understand and interact with the world around them, creating opportunities for innovation and enhancing user experiences across the board.
Our data processing company specializes in providing advanced audio annotation services tailored to meet the unique needs of your projects. Contact us to learn how our expert team can transform your audio data into actionable insights and drive your success. Take the first step towards discovering the full potential of your audio data!
What is sound annotation?
Sound annotation involves labeling or marking specific sounds within audio data. It's used to identify and categorize sounds such as speech, music, noise, or particular events like alarms or clicks. This process helps train machine learning models to recognize and differentiate sounds effectively.
What is speech annotation?
Speech annotation is the process of marking or labeling segments of spoken language within audio recordings. It involves identifying individual phrases/sentences a speaker says. This annotated data is vital for training speech recognition systems and enabling AI models to understand spoken language.
What is audio annotation for AI?
Audio annotation for AI refers to annotating audio data to enable machine learning algorithms to understand and interpret sound. This includes labeling different types of sounds, identifying speech, music, or environmental noise, and marking specific events/characteristics within audio recordings.
What is the difference between annotation and transcription?
Audio annotation involves adding descriptive labels or tags to specific parts of an audio recording (speaker emotions, background noises, etc). In contrast, transcription converts spoken language into written text, capturing exact words from audio recordings without additional categorization.
How to annotate a speech?
Annotating speech involves several steps: segmentation (dividing the audio into manageable segments), labeling (assigning labels to each segment), transcription (transcribing the spoken content into text), and quality check (ensuring the annotated data is reliable for training AI models).