

You may Most AI teams spend 80% of their time fighting with messy data and not building cool models. Maybe you even know how it goes. Your team gets excited about a new AI project, but then someone asks, “Where’s our training data?” And suddenly, things get real.
Your data is scattered across different databases. Half the files are missing labels. The other half have labels that were clearly created by someone who didn’t understand the task. You have planned three months for your project, but now it looks like a year-long venture.
And here is something even worse. You are stuck cleaning data and hunting down annotations, and your competitors are already training models. It doesn’t mean they are smarter or better funded. They just figured out something important. They’re using prepared AI datasets.
Ready-to-use datasets for AI can be compared to a fully mapped GPS route. You can spend endless hours wandering around and trying to find your destination without such a route, or you can follow a clear path and reach your goal faster.
This guide will show you how prepared AI datasets work, when to use them, and how to pick the right ones for your projects. You will understand why AI training datasets are a must for AI teams and how these can speed up development and improve results.
Why Raw Data Is a Bottleneck in AI
Data is everything for AI – it fuels models, teaches machines to recognize patterns, and powers every AI project, be it a chatbot or a recommendation system. But at the same time, raw data scraped from the web, sensors, or user interactions is becoming a major AI problem.
Real-world data comes messy, inconsistent and unlabeled. As we already mentioned, data scientists spend 60-80% of their time on data cleaning and preparation. Another alarming truth is that the stock of human-generated data (and it’s around 300 trillion tokens!) will be fully used for AI training between 2026 and 2032. In addition to this, restrictions are also growing. In the Common Crawl dataset, restricted tokens jumped from 5–7% in 2023 to 20–33% in 2024, and nearly half of the top domains are fully restricted.
The low quality of raw data is detrimental to AI. Even small errors can put AI training at stake. Enterprises struggle with unstructured, siloed information, and 95% of all AI projects fail eventually.
Prepared datasets for machine learning can solve the quality issue. These are pre-cleaned, labeled, and structured and can be immediately used for AI training. It’s like having all the ingredients for a complex recipe – you don’t waste months on raw data. Prepared datasets minimize bias, come with proper licensing, and allow teams to focus on modeling tasks.
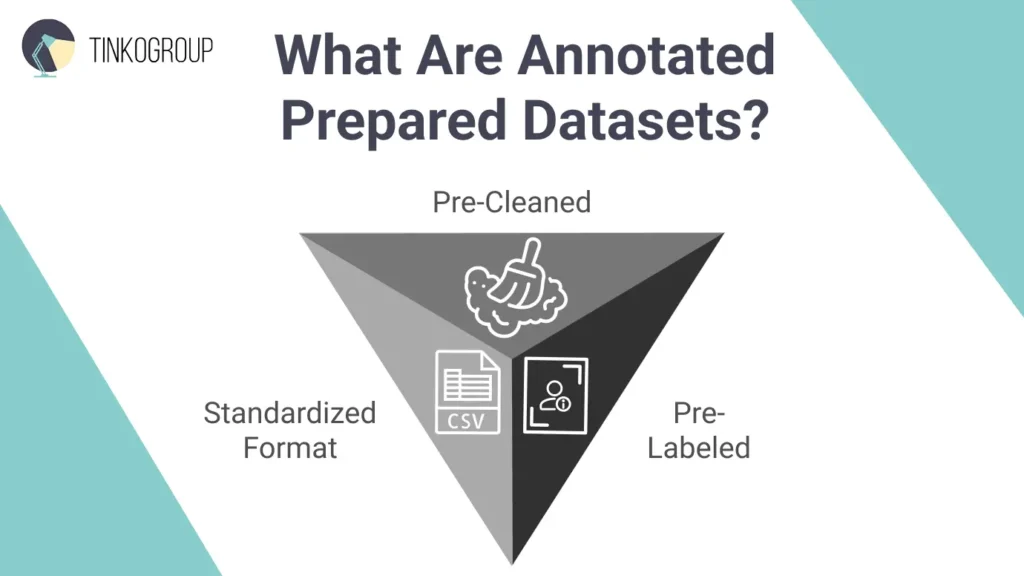
What Are Annotated Prepared Datasets?
Prepared AI datasets are collections of data that have already been cleaned, labeled and ready to use for training machine learning models. It’s a production-ready version of raw data. Of course, raw data is valuable, but it requires extensive work to become useful. And prepared AI datasets are polished, cut, and ready to train your AI models. A prepared dataset has three essential characteristics:
- Pre-cleaned. The data is cleaned up so it’s easy to work with. Duplicates and irrelevant details are removed, entries are made consistent, and missing values are either filled in or taken out.
- Pre-labeled. Each data point is tagged with accurate, meaningful annotations. For an image dataset, this means bounding boxes around objects, pixel-level segmentation, or descriptive tags. For text, it could be sentiment labels, named entity tags, or intent classifications.
- Standardized format. The data is delivered in a consistent, ready-to-use format, and data scientists can plug it directly into their ML pipelines.
Prepared AI Datasets vs. Raw Data
Raw data and prepared datasets differ seriously. Raw data is unprocessed information from sensors, cameras, or databases, and on its own, it’s not ready for AI training. Prepared AI datasets, on the other hand, are polished and ready to use. The key differences between them are:
- Usability. Raw data requires a lot of preparation work, and prepared data can go straight into a model.
- Quality. Raw data is messy and inconsistent, and prepared data is cleaned and reliable.
- Annotation. Raw data has no labels, and prepared data comes with expert annotations.
Common Formats
Prepared AI datasets come in various forms and are used for different AI domains. Some of the most common include:
- Tabular data comes in CSV, JSON, and Parquet formats and is used in finance, healthcare, e-commerce, and basically any field that needs analytics.
- Image data comes in simple JPEG and PNG formats and specialized ones like DICOM. It’s used for imaging, facial recognition and self-driving cars.
- Text data comes in text, JSON, and XML formats and powers chatbots, translation services, and sentiment analysis.
- Audio data comes in WAV and MP3 formats and is used for speech recognition, music recommendation engines, and diagnostic tools in healthcare.
- Multimodal data combines text, images, and sound. Today, more than half of AI projects use this type of data to deliver richer results.
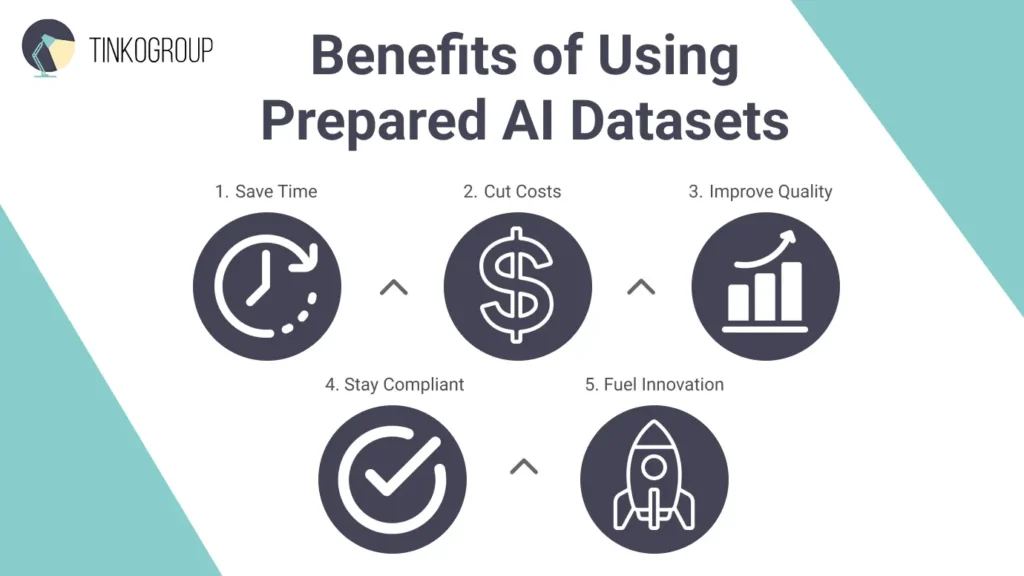
Benefits of Using Prepared AI Datasets
AI is developing at an unprecedented speed. Quality and cost play key roles in this race. That’s why more and more companies are choosing prepared datasets for AI training. Platforms like Kaggle, Hugging Face, and commercial providers such as Scale AI offer these ready-to-use datasets. And here are the compelling benefits of prepared datasets.
1. Save time. You can always create a dataset from scratch, but be ready to spend months on this task. Data preparation eats up as much as 80% of an AI project’s time. Ready-made datasets can cut this time load by 50–70%. For example, Tesla uses pre-labeled data for autonomous driving simulations, and it enables engineers to shorten weeks-long testing cycles to days.
2. Cut costs. Manual data labeling is expensive – the annotation of one item can reach $1–5. Imagine the cost for large projects which include millions of objects. Studies show that prepared datasets reduce AI development costs by 30–40%. OpenAI trained ChatGPT with the help of massive public datasets like Common Crawl to avoid sky-high expenses.
3. Improve quality. High-quality datasets reduce errors and biases that often slip into raw data. Cleaning and preparing a dataset is no longer a technical step – it is a mandatory risk mitigation strategy. However, it’s very expensive – Gartner reports that poor data quality costs the average organization $12.9 million to $15 million annually. The same principle applies to commercial data workflows, where standardized processes like Shopify product upload standardization help reduce errors, maintain accuracy at scale, and protect downstream business decisions.
4. Stay compliant. Data rights and privacy rules are getting stricter every year. Prepared datasets usually come with built-in usage rights and privacy safeguards, and reduce legal risks. This is critical for AI models, as for 2025, the cumulative total of GDPR fines has reached nearly 6 billion euros.
5. Fuel innovation.
Prepared datasets also give smaller companies a chance to compete. In agriculture, startups use free satellite imagery from NASA to train models that predict crop yields. According to a 2024 IDC report, 60% of enterprises now rely on third-party datasets, which is 40% more than in 2020. It allows various industries to advance.
Types of Prepared Datasets
Prepared AI datasets can be categorized into two groups: by what the AI is trying to learn, and by who can access the data.
Prepared AI Data by AI Domain
Prepared datasets are like shortcuts for AI. You don’t need to spend months collecting and cleaning data now. You can find ready-to-use sets that are already labeled and organized. This makes training faster, cheaper, and usually more accurate. Here’s how they show up in different AI domains.
Prepared datasets for NLP
AI that works with text uses solid datasets for better performance.
- Chatbots learn from resources like the Cornell Movie Dialogs or MultiWOZ. These datasets contain thousands of real or simulated conversations and let models learn context, intent, and natural-sounding responses.
- Sentiment analysis uses IMDb Reviews or Twitter Sentiment140 to train models to recognize positive, negative, or neutral opinions. Here, text is labeled as positive, negative, or neutral. So, AI models can track brand reputation, monitor social media, and even predict market trends.
- Translation apps use datasets like WMT or OPUS, which pair text in different languages. They help apps like Google Translate handle idioms, slang, and even specialized vocabulary in medicine or law.
Prepared datasets for computer vision
AI can also be trained to “see” objects, and for this, experts use labeled images and video.
- Autonomous driving systems use KITTI or nuScenes datasets. These are filled with road scenes that label cars, pedestrians, lanes, and traffic signs under different lighting and weather. This variety makes self-driving models safer and more reliable.
- Retail uses COCO or Fashion-MNIST, which label everyday objects or clothing. These datasets support shelf monitoring, product recognition, and even customer behavior analysis in stores.
- Healthcare uses sets like ChestX-ray14 or MIMIC-CXR. These contain anonymized, labeled scans used to train AI to detect pneumonia, tumors, and other conditions and help doctors with faster and more accurate diagnostics.
Prepared datasets for speech/audio
Audio datasets capture how people actually speak, accents and all.
- Transcription tools train on LibriSpeech or Mozilla Common Voice, which pair hours of speech with text. This powers meeting apps and accessibility tools for the hearing impaired.
- Voice recognition relies on VoxCeleb or Google AudioSet, which identify speakers and even emotions. These datasets strengthen biometric security and make assistants much smarter.
Prepared AI Data by Availability
You can use open or proprietary data to train your AI model.
- Open-source prepared datasets are free but somewhat risky. For example, Hugging Face or Kaggle are accessible to everyone. You can download them, experiment, or even contribute improvements. This speeds up innovation since researchers don’t have to start from scratch. Another free dataset, the GLUE benchmark, is widely used to test NLP models and lets researchers and companies compare results on the same standard tasks.
But open data isn’t perfect. There are issues with quality, biases and privacy, as often this data isn’t filtered well. There’s also a risk of misuse. For instance, datasets can be used to create deepfakes. That’s why free sets require ethical guidelines and ongoing audits.
- Custom proprietary datasets are built in-house or purchased from specialized providers. These are tailored for specific needs and usually contain cleaner, more reliable data. It’s, for example, Netflix’s viewing data, which powers its recommendation engine and gives the company a competitive edge.
The biggest downside of custom prepared datasets is their cost. They are created by experts with strict compliance. Usually, these datasets are locked away.On the flip side, they protect sensitive information and intellectual property.
Prepared Datasets vs. Raw Data
When building AI, it’s always a dilemma whether to use prepared AI data or raw data. Prepared datasets are already cleaned, labeled, and ready to use, and raw data needs a lot of work before it’s usable. Your decision influences timelines, costs, and results. So, let’s dig deeper.
Side-by-Side Comparison of raw and AI-ready data
A side-by-side comparison makes it easier for teams to see the trade-offs and pick the option that best fits their goals and budget. This table details the critical differences across multiple parameters of both solutions.
| Parameter | Raw Data | Prepared Datasets |
| Cleanliness and quality | Unstructured, and often messy. May contain noise, duplicates, missing values. | Pre-cleaned and pre-processed. Quality checks remove all inconsistencies. |
| Annotation and labeling | Completely unlabeled. An entire annotation pipeline must be built from scratch. | Expertly pre-labeled and annotated. |
| Initial Cost | Cost of acquisition only. However, further preparation investment is needed. | Higher upfront cost. |
| Total Cost of Ownership (TCO) | Very high (includes hidden costs for data preparation). | Predictable and often lower TCO. |
| Time to Usability | Very slow (months) | Extremely fast (days or weeks) |
| Technical expertise required | High | Low |
| Customization and flexibility | Total control | Limited flexibility |
| Scalability | Challenging | Inherently scalable |
| Compliance and security | You are solely responsible for everything. | Reputable providers deliver datasets that are compliant with major regulations. |
| Risk of Bias | Unmitigated and opaque | Potentially mitigated |
When to Use Raw Data
Prepared datasets win the above comparison without a doubt, but sometimes raw data is the only option. Raw data comes straight from the source – sensors, logs, or public repositories – and hasn’t been cleaned or labeled yet. It takes more work, but in certain cases, it’s the option.
- No prepared dataset exists for a particular niche. In areas like rare diseases or unique IoT sensor projects, you often need to collect your own data.
- Your market is very specific. Let’s say you are training a farming AI system that relies on drone footage, soil data, and local weather. Generic datasets don’t cover these details.
- You’re testing new ideas. Raw data gives you full control – you can experiment without the limits of pre-made datasets.
- You want an edge. Startups may build their own datasets to get something unique that competitors can’t copy.
- You’re on a budget. Free sources like the UCI Machine Learning Repository can be a good start if you’re willing to prepare the data yourself.
The downside is that raw data needs a lot of resources – storage, computing power, and skilled people. But if your project requires custom detail and innovation, it’s a good idea to start with raw data.
Risks of Skipping Preparation
Many are making this mistake. Data preparation is usually skipped because deadlines are tight, or the budget simply isn’t set up for it. However, it can quickly derail an AI project.
Bad performance is the most obvious risk. If a model trains on messy or unbalanced data, it may latch onto noise instead of patterns. That means predictions that don’t hold up in the real world. In healthcare, for example, duplicate scans in a dataset could trick an algorithm into overcounting certain cases. Such cases lead to dangerous false positives or negatives.
Bias is another problem. Real-world data often carries social imbalances. If you don’t catch it early, your model may quietly learn to replicate those same biases. Skipping preparation makes this much harder to spot.
Legal and privacy risks are also a big concern. Modern regulations (for example, GDPR or HIPAA) demand strict safeguards. If you use raw data without anonymization or fail to check dataset compliance, you can end up with fines, breaches, or reputation loss.
Slowdowns and wasted money. More bugs, higher compute costs, and shaken trust can all pile up. In safety-critical areas like autonomous driving, those mistakes could cost lives.
The lesson is simple – no matter the source, always validate and clean your data. It’s the foundation of trustworthy AI.
Challenges and Limitations of Prepared AI Datasets
Ready-AI datasets make building models faster and easier, but they’re not ideal. You can avoid costly mistakes when you know these drawbacks upfront. Here are some of the biggest issues you can face:
Not Always Plug-and-Play
A common misconception is that prepared datasets are ready to use in any AI project. In reality, they often need adjustments to fit specific domains or unique project requirements. For example, a general NLP dataset like GLUE works well for broad tasks but is not so good for specialized areas such as legal or medical texts, where terminology and context differ. Fine-tuning adds time and costs.
Similarly, a dataset like COCO, designed for everyday objects, may not cover niche tasks like detecting industrial defects. If you decide to use it, you will need to make a custom pipeline.
Compatibility can also be an issue. A dataset formatted for TensorFlow may need conversion for PyTorch. Always test datasets in a sandbox environment before full deployment to see all potential gaps.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Bias and Data Quality Issues
Bias and data quality still happen in prepared AI datasets. Mistakes often creep in during annotation or come from the source material itself. For instance, crowdsourced labeling done quickly to save costs can introduce mislabels and hurt model accuracy. Cultural biases are also common – datasets often overrepresent Western viewpoints, so models may misread sarcasm or local expressions.
Data quality is another risk. Uncleaned duplicates or outliers can skew results, and historical biases and lead to discriminatory outcomes in hiring and surveillance.
Careful audits can solve these problems. Tools like AIF360 help detect and reduce bias, but you must fully understand how to use these tools first. So, even with ready-made datasets, teams must not forget about thorough checks.
Cost and Licensing Concerns
High-quality prepared AI datasets are not always affordable to startups, academics, and small businesses. Premium datasets from companies like Scale AI or Appen can cost thousands or even millions of dollars. Specialized data, such as HIPAA-compliant medical images, is even pricier because of expert labeling and privacy safeguards.
Licensing is another challenge. Some datasets limit commercial use, redistribution, or modifications. Even free open-source datasets, like those on Hugging Face, may have licenses that restrict certain uses, creating potential legal risks. Proprietary datasets often lock users into vendor ecosystems, reducing flexibility and causing vendor dependency.
For teams with limited budgets, synthetic data can be an alternative, though it may compromise quality. When you plan to use a ready dataset, check not only its cost but also the terms of use and scaling potential. Is there a solution? Yes, it’s a balanced approach – mix prepared datasets with custom enhancements and ethical reviews. This way, you will maximize benefits and avoid common pitfalls.
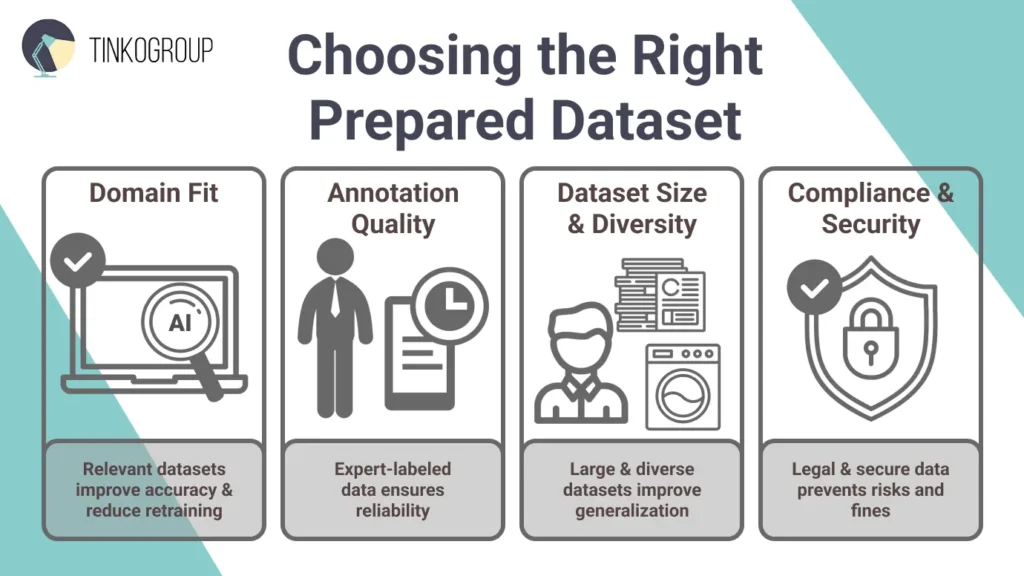
How to Choose the Right Prepared Dataset
The success of your AI project largely depends on the dataset you choose to train it. It affects your model’s accuracy, fairness, and performance. So, here is what matters most when you are choosing a dataset.
Domain fit. The first step is to check whether the dataset matches your project’s domain. Even the best data is useless if it’s unrelated. For example, building a medical AI requires specialized datasets like ChestX-ray14 rather than general image sets like ImageNet. Check the dataset’s description, source, and sample data. Preview tools and metadata summaries help assess fit. A relevant dataset reduces retraining and improves accuracy from the start.
Annotation quality. Next, look at who did the labeling – domain experts, crowdsourced workers, or automated tools? High-quality datasets are annotated by experts, like doctors, for healthcare data. Also, investigate how labels were in a particular dataset. Metrics like Cohen’s Kappa (>0.8) show strong agreement. Poor labeling introduces noise and bias. Ask providers for sample annotations to test accuracy before you pay for access.
Dataset size and diversity. A dataset must be large and varied enough for models to generalize. Thousands to millions of samples may be needed, depending on the task. Diversity is also critical. Facial recognition datasets, for instance, should include multiple ages, ethnicities, and lighting conditions to avoid bias. Small datasets can work if you’re fine-tuning an existing model, but if you’re training a model from scratch, you’ll need a much larger dataset.
Compliance and security. Data must follow laws like GDPR, HIPAA, or CCPA to avoid fines or reputational risk. Additionally, data must be anonymized, consented, and free of personal identifiers. Penalties are high here – if you use non-GDPR datasets in EU projects, you may pay up to 4% of your global revenue. Always review licenses and consult legal experts before use.
Future of Prepared Datasets
AI spreads across industries, and prepared AI datasets are becoming smarter and more adaptive. In 2025, datasets are shifting from static collections to dynamic resources. What can we expect next?
Synthetic + Prepared Data
Synthetic data, generated by AI models, is increasingly integrated with real datasets to address data scarcity and privacy concerns. For instance, in autonomous vehicles, synthetic datasets simulate rare scenarios like adverse weather, augmenting real-world data for more robust training. This hybrid approach boosts model accuracy and reduces data collection costs.
Multimodal Datasets
Multimodal datasets combine text, images, and audio to train AI systems that can process information in a manner similar to humans. They are used in applications like virtual assistants, video captioning, and accessibility tools. This trend accelerates advancements in entertainment (AI-driven film editing) and education (interactive learning apps).
Decentralized datasets
These are collections of data that stay in multiple locations instead of being stored all in one place. Instead of sending all the raw data to a central server, AI models are trained where the data lives – on local devices, servers, or company networks. This method is often called federated learning. Decentralized datasets also let smaller organizations contribute to AI projects without giving up control of their data. It’s valuable for sectors like healthcare and finance, where sensitive information is prevalent.
Mini Case Study
How to use prepared datasets in AI projects? Actually, even small-scale prepared AI datasets, let’s say under 10,000–50,000 samples, pre-cleaned and annotated, are proving highly valuable for startups, SMBs, and specialized projects. They allow teams to prototype quickly, test affordably, and focus on quality over quantity. Such datasets make AI affordable for organizations with limited resources.
Case in Point: Tinkogroup prepared a dataset for an IT client, including 8,000 text messages labeled for entity recognition (names, locations) and sentiment (positive/negative/neutral), along with 10,000+ annotated images. Using Labelbox, they achieved 98% annotation accuracy in six months.
This dataset accelerated NLP model training by 40–50%, reducing development from months to weeks. Sentiment labels improved tone detection for customer analysis, and image annotations streamlined visual asset management.
Why is it important?
E-commerce startups can use similar datasets to train chatbots, improve query accuracy and user engagement. Retail SMBs can repurpose image annotations for inventory management. Small datasets also simplify compliance (e.g., GDPR anonymization) and reduce computing needs, and make AI accessible on standard hardware.
Conclusion
If you want to succeed in today’s AI world, you must be fast, accurate and compliant. When you start with a high-quality, pre-annotated dataset, you are efficient on all three fronts. It cuts months of manual work, improves model performance with precise labels, and ensures regulatory compliance from day one.
Prepared AI datasets are a foundation of modern AI development. Solid, reliable data allows scientists and engineers to focus on building, testing, and refining AI models that create real-world impact. And it works equally well across all industries.
Ready to accelerate your AI projects?
You have already invested enough time and resources in building datasets from scratch. Now, it’s time to scale. Contact Tinkogroup to explore how we can help you develop smarter, faster, and more effective AI – trust us and we will turn your ideas into actionable results in the blink of an eye!
Why should I pay for a prepared dataset instead of using free raw data?
Free raw data often requires months of cleaning and labeling, which delays launch and increases hidden costs. Prepared datasets are production-ready, allowing you to start training immediately and reducing development time by up to 70%.
Are prepared AI datasets safe to use legally (GDPR/CCPA)?
High-quality prepared datasets from reputable providers are anonymized and adhere to privacy laws like GDPR and HIPAA. However, always verify the licensing terms to ensure the data allows for commercial use in your specific region.
What if there is no prepared dataset for my specific niche?
If a ready-made dataset doesn’t exist, you need a custom solution. You can combine smaller available datasets with synthetic data or partner with companies like Tinkogroup to collect and annotate a unique dataset tailored to your project’s needs.


