

If you speak more than one language, you’ve definitely experienced this. You hear a hilarious joke, a perfect mix of wordplay, timing, and cultural context. So, you rush to translate it for your friend, confident it will land just as well. But the punchline disappears in a different language. The soul of the joke – its irony, its sarcasm, its sentiment – has evaporated in translation. Why? Because “funny” wasn’t in the words themselves, but between the lines. Language is not vocabulary only. It’s nuance, implication, tone, and shared context.
Now consider a customer review that reads: “Well, that was just perfect.”
Is that praise or sarcasm? Humans will immediately figure it out based on context and tone. But for machines, it’s a puzzle that they fail to solve without training. This is the challenge and the opportunity of sentiment analysis.
Sentiment analysis, also known as opinion mining, is the way AI determines the feelings and opinions behind written text. It’s what allows businesses to read and interpret customer feedback. But businesses are facing thousands of product reviews, millions of social media mentions, endless streams of survey responses and support tickets. It’s not realistic to keep teams manually reading and understanding what customers say, as the market would have changed by then.
This is where sentiment analysis becomes a must-have business tool. It helps companies automatically understand customer emotions, identify issues early, and make sense of massive amounts of feedback. But even the most advanced algorithms fail if they are not properly trained. The “garbage in, garbage out” principle has never been more relevant.
Let’s explore how sentiment analysis in AI works under the hood, why high-quality human annotation is its foundation, and how teaching AI to read between the lines makes all the difference.
The Mechanics: How Sentiment Analysis Works
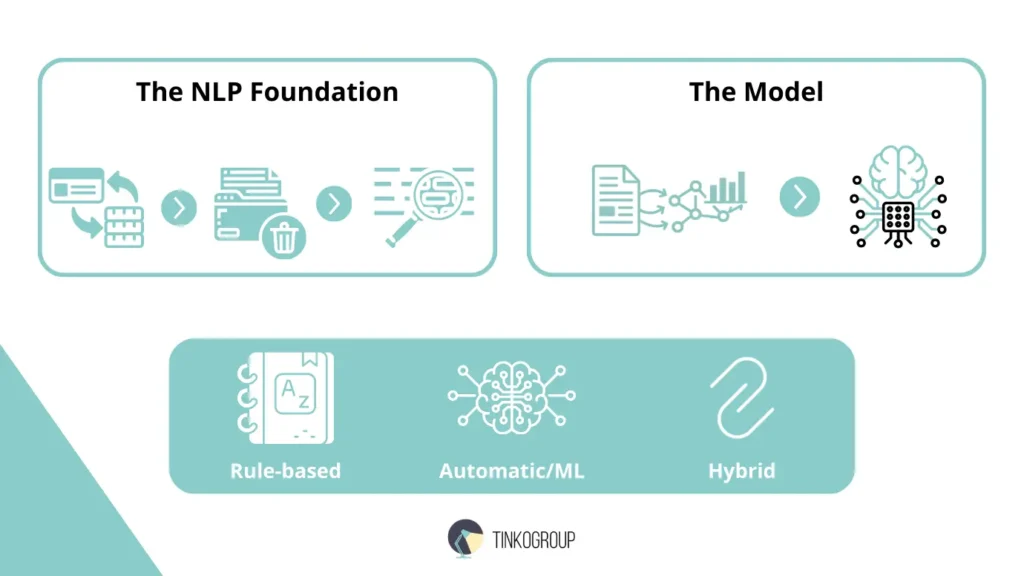
Before talking about how sentiment annotation makes all of this work, let’s see what happens when text gets into a sentiment analysis system. You will understand why good training data is so important. At its core, sentiment analysis is part of natural language processing (NLP), which enables computers to perceive human language. Computers don’t interpret sentences and emotions like people. Text must first be broken down, cleaned, and converted into a form that machines can analyze before they detect any sentiment. Let’s have a closer look at this process:
The NLP Foundation: Preparing the Text
Before any sentiment analysis can happen, the text needs to be cleaned and organized using a few basic Natural Language Processing (NLP) steps. This helps the system understand what it’s looking at.
Tokenization. This step breaks a sentence into smaller pieces, usually individual words.
For example, the sentence “The battery life is incredibly disappointing!” becomes:
[“The”, “battery”, “life”, “is”, “incredibly”, “disappointing”, “!”]
Now, the system has simple and manageable material to work with.
Stop-word removal. Next, the system removes common words that don’t add much meaning on their own, such as “the,” “is,” “and,” or “in.” Now, the sentence looks like this: [“battery”, “life”, “incredibly”, “disappointing”, “!”]
This allows the model to focus on the words that actually express an opinion or emotion.
Lemmatization. Finally, words are reduced to their basic form. For example, “disappointing,” “disappointed,” and “disappoints” are all reduced to “disappoint.” So, the system understands that different versions of the same word usually mean the same thing and doesn’t treat them as completely separate words.
The Model: How AI Classifies Text
Once the text has been cleaned and broken into tokens, the system can analyze it. In a machine-learning approach, the model has already been trained on large amounts of text that humans have labeled with sentiment.
Feature extraction. First, the text is turned into numbers so the computer can work with it. Words with similar meanings are placed close together in this numerical space. This helps the model understand that words like “terrible” and “awful” express similar negative feelings, even though they are different words.
Classification. Next, the model compares the text to examples it has seen before during training, such as “I love this” labeled as positive or “This is terrible” labeled as negative. Based on those patterns, it assigns a sentiment label and often a confidence score, which shows how sure it is about the result.
Rule-based vs. Automatic (ML) vs. Hybrid approaches: A Brief Comparison.
There are different approaches to sentiment analysis.
Rule-based. This system follows a fixed set of rules and sentiment dictionaries. Words like “excellent” = positive and “poor” = negative are pre-scored, and the system adds up the scores for a text. It’s simple and easy to understand, but struggles with slang, sarcasm, negation, and context. For example, “This product is sick!” can be misread.
Machine learning. ML models learn from labeled examples instead of fixed rules. They can handle nuance, new expressions, and complex sentences. Accuracy depends on the quality and relevance of the training data – a model trained on movie reviews usually fails on financial or medical texts.
Hybrid. Hybrid systems combine both approaches. Rules handle clear-cut cases, and ML manages ambiguous or tricky language. This mix gives both control and flexibility and makes hybrid systems the most reliable choice for real-world business applications.
Types of Sentiment Analysis
Imagine you ask someone how their day went, and they reply, “Fine.” Alternatively, they can say, “The morning was fantastic because I finished a big project, but then I got stuck in awful traffic for an hour, and now I’m exhausted.” Sentiment analysis works the same way. It can provide a precise answer or detailed insight. What type should you choose? It depends on the business question you need to answer and how much detail you need from the data.
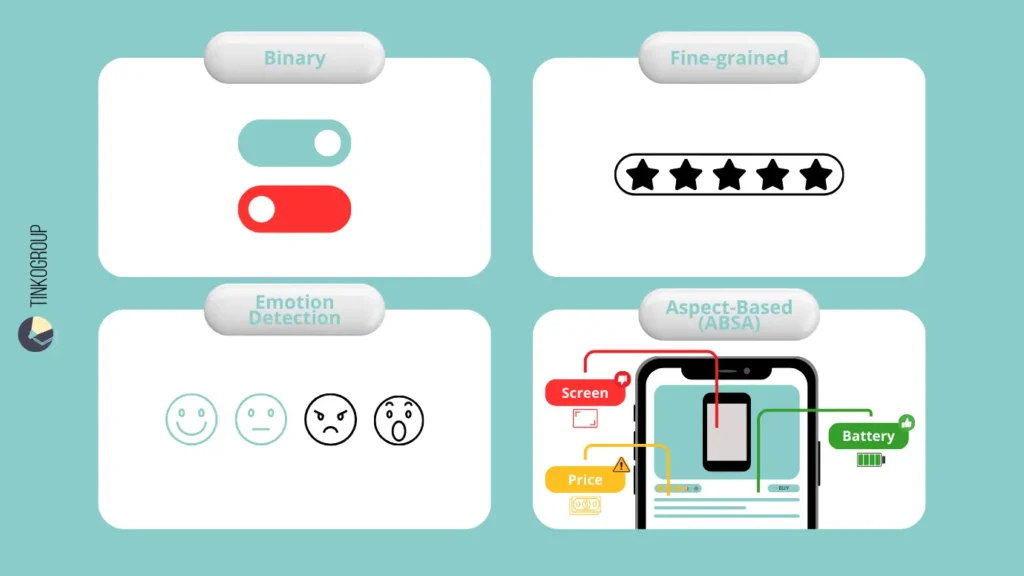
Binary analysis
Binary analysis is the simplest form. Text is classified as either Positive or Negative. It’s fast and easy and gives a broad overview of opinions. For example:
- “This update is helpful!” – positive
- “Worst customer service ever.” – negative
Binary analysis works well for quick checks or large-scale monitoring. You can use it to scan social media mentions or product reviews. But it misses nuance. Mixed opinions or neutral statements are often forced into one category, which can hide important insights.
Fine-grained analysis
Fine-grained sentiment analysis uses a multi-point scale, often 1–5 stars, or labels from Very Negative to Very Positive. This approach captures shades of opinion. For example:
- “It’s okay, does the job.” – neutral
- “I’m absolutely thrilled with this purchase!” – very positive
This type is good for product reviews and surveys. Сompanies see the difference between mild satisfaction and extreme enthusiasm, or between slight disappointment and deep frustration.
Emotion detection
Emotion detection can identify specific human emotions, for example, joy, anger, sadness, fear, surprise, or disgust. For example:
- “I’m furious and feel completely disrespected.” – anger
This level of detail is useful for customer support – it allows routing angry customers to senior agents, or for content moderation – it easily identifies posts with harmful or hateful emotions. Emotion detection is used in mental health and wellness applications to detect emotional states from text.
Aspect-Based Sentiment Analysis (ABSA)
ABSA looks at specific features or aspects mentioned in the text and assigns sentiment to each. Let’s take this hotel review:
“The location was perfect and the bed comfortable. However, the room was dusty and the breakfast disappointing.”
ABSA reads it as follows:
- Location – positive
- Bed – positive
- Cleanliness – negative
- Breakfast – negative
It provides actionable insights. The company immediately knows what to promote (location, bed) and what to fix (cleaning, breakfast). ABSA is more complex because the AI must identify the entity (hotel), extract aspects (location, bed, breakfast), and link the right sentiment to each.
How to choose the right sentiment analysis model?
- Binary analysis can flag a problem if it exists.
- Fine-grained analysis shows how strong feelings are.
- Emotion detection identifies the type of emotion.
- ABSA pinpoints exactly where issues are.
Together, these tools turn a massive amount of feedback into a clear picture.
Sentiment Annotation: The Foundation of Accurate Analysis
Let’s have a closer look at a well-known axiom in computer science – Garbage In, Garbage Out (GIGO). It is the unshakeable first law of artificial intelligence. You can deploy the most sophisticated neural network, the latest transformer model, but if you train it on shallow data, its output will be flawed. In sentiment analysis, this means an AI may correctly parse every word in a sentence but completely misinterpret the human heart of the message.
High-quality sentiment analysis doesn’t mean using bigger models or more computing power. It means training AI with carefully labeled data from humans, so it learns to understand text the way people do. This is why many companies look for a reliable data annotation service vendor to ensure their models are built on a solid foundation.
What Is Sentiment Annotation?
It is the process of adding meaningful, consistent, and accurate sentiment tags to raw, unstructured text. Humans read unfiltered text – tweets, reviews, support chats, forum posts – and tags that capture the emotional undercurrent. These tags go beyond basic positive/negative/neutral; they can include intensity levels (mildly annoyed vs. raging), specific emotions (joy, frustration, sarcasm), aspects (if it’s ABSA), or even confidence flags for tricky cases. Human annotators turn unstructured data into a structured “round truth” dataset that a machine learning model can use to learn patterns.
How Is Annotation Workflow Built?
Phase 1. Creating Sentiment Annotation Guidelines
The very first step is to create clear annotation guidelines. It’s a shared rulebook everyone must follow. It removes guesswork and answers tricky questions upfront.
For example:
How should sarcasm be labeled?
What counts as neutral feedback?
Is “not bad” positive or neutral?
Does “killing it!” mean success or something negative?
The guidelines explain it in plain terms. For instance, for the sentence “Well, that was just perfect,” a guideline may say: Label this as Sarcastic Negative when overly positive words like “perfect” or “great” are used to describe a clearly bad outcome.
This level of clarity ensures everyone labels text the same way. Otherwise, different annotators would make different judgment calls and create messy, inconsistent data that confuses the AI.
Phase 2. Labeling the Data
When the rules are ready, annotators (teams of linguists, domain experts, or trained crowd workers) start working with the text using annotation platforms (Prodigy, LabelStudio, or custom tools). They read, analyze context, apply tags, and sometimes add comments (“This is sarcastic because of the exaggeration + eye-roll emoji”). To scale the work, the system sends only confusing or uncertain texts to human reviewers, so their time isn’t wasted. Quality should also be checked by more than one person. Plus, results must be regularly reviewed to catch mistakes early.
Why Humans Are Irreplaceable
You may wonder why this labeling can’t be fully automated. The answer is simple – AI struggles with the language nuance. An untrained system has no real-world awareness. It doesn’t know that “sick” can mean “ill” or “amazing.” It doesn’t understand that “This app is insane!” is high praise in a gaming review, but a red flag in healthcare software. And it certainly doesn’t catch the eye-roll hidden in a sarcastic “Yeah, right.”
Humans immediately see these hidden things. We teach AI how language actually works in real life. Annotators are a bridge between words and the actual meaning behind them. When someone labels “This feature is a workaround” as negative or understands that “interesting choice” often implies criticism, they’re encoding real-world context into the data. Humans are irreplaceable for handling:
- sarcasm and irony
- cultural and industry language
- context and ambiguity
At its core, sentiment annotation is a large-scale effort to capture human emotional intelligence in data form. Annotators are teaching AI how people think, speak, and imply meaning. The final dataset is not a simple list of labels, but a collection of human judgments.
That’s why investing in expert-led annotation is a must. It’s the foundation of any sentiment analysis system that aims to truly understand customers. The algorithm may be the engine, but high-quality annotated data is the fuel. Without it, accurate insight simply isn’t possible.
Measuring Quality & Handling Challenges
How to achieve accuracy in sentiment, which is inherently subjective? Rigorous validation is needed. When you create a training dataset, you must be sure the data isn’t a collection of individual biases. To build a robust model, we must quantify the reliability of our human annotators and create a system that catches errors before they become part of the AI’s logic.
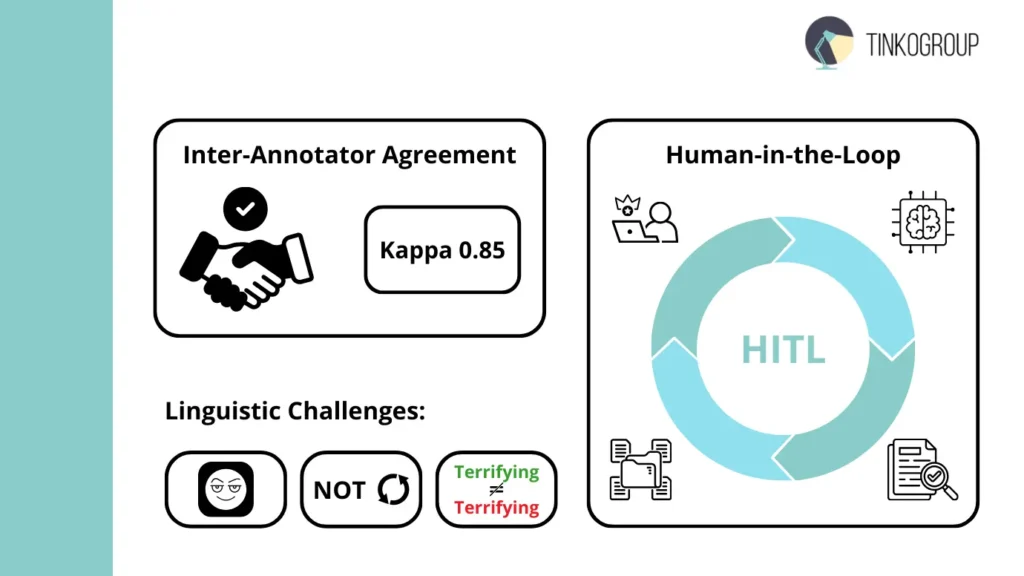
Measuring Inter-Annotator Agreement
How do we know if our labels are actually correct? We use Inter-Annotator Agreement (IAA). If two people look at the same tweet and one labels it “Happy” while the other labels it “Sarcastic,” the data is “noisy.”
To measure this scientifically, we use Cohen’s Kappa. Unlike simple percentage agreement, Cohen’s Kappa calculates how often annotators agree and also takes into account the possibility of them agreeing by sheer chance.
- A score of 0.81–1.00 indicates “Almost Perfect” agreement.
- A score of 0.61–0.80 is considered “Substantial” and is usually the target for high-quality sentiment datasets.
To maintain these scores, projects often use Adjudication, where a third, more experienced “Master Annotator” reviews cases where the first two annotators disagreed and provides the final, authoritative label.
Human-in-the-Loop for Safety
Absolutely each model may contain edge cases with low-confidence prediction. A Human-in-the-Loop (HITL) system helps here. When the model analyzes a new piece of text, let’s say a tweet like, “Just what I needed today, another system outage,” – it may offer a sentiment label (“Negative”) with only 55% confidence. A HITL system is programmed to automatically flag this low-confidence prediction and route the original text back to a human annotator for review. The human makes the definitive judgment (in this case, likely “Sarcastic_Negative”), and this new tag is returned to the training dataset.
This creates a powerful virtuous cycle: humans handle the hard cases, their decisions improve the dataset, the model retrains on better data, becomes more confident, and flags fewer ambiguous cases over time. HITL doesn’t mean a model is weak. On the contrary, it’s a sign of continuously learning and improving AI models.
Sentiment Analysis Challenges
We cannot 100% rely on fully automated systems because of several linguistic challenges:
- Sarcasm and irony. This remains the most difficult task. A phrase like “Oh, I love spending four hours on hold” contains only positive words (“love”) but carries a negative intent. Without the context (the frustration of a long wait), a machine will fail.
- Negation handling. The word “not” is also tricky, based on where you use it. “Not bad” is actually a positive sentiment, while “Not as good as I expected” is negative. Modern models must be trained to look at the entire sentence structure rather than just individual words.
- Context. Some words are chameleons. In a review for a horror movie, the word “terrifying” is a 5-star compliment. In a review for a new car’s braking system, “terrifying” is a failure.
These cases are traps for machines, but humans easily remove them and teach AI to read the intent of the speaker, not the dictionary definition of their words.
The Role of the Dataset
Training a sentiment analysis model is an act of teaching. And every great teacher knows that the material you use determines what the student learns. In AI, this material is the sentiment analysis dataset. This collection of text, carefully labeled by humans, is the only way the model learns what happiness, frustration, approval, or sarcasm is. That’s why the dataset’s quality completely determines how well the AI understands sentiment.
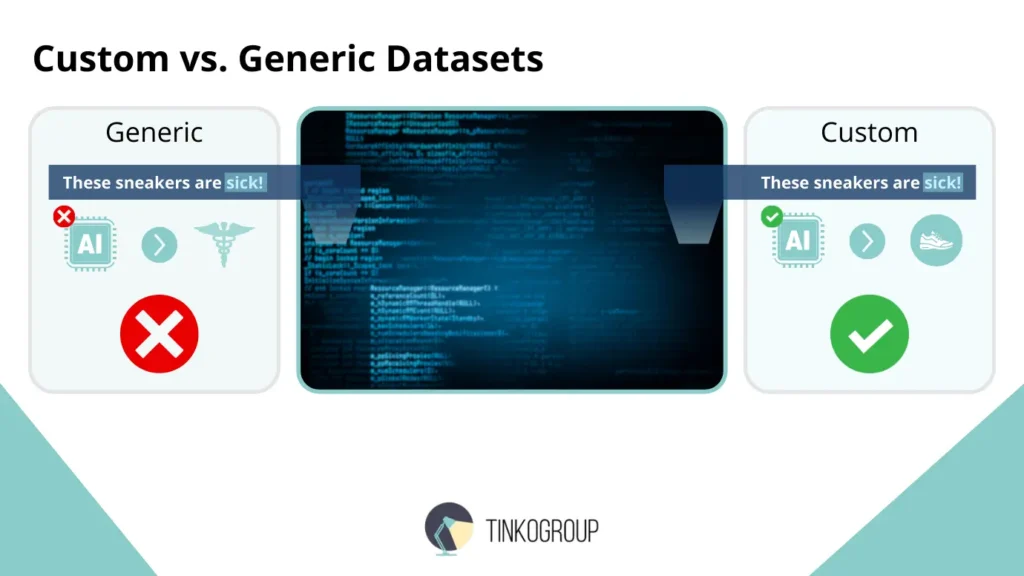
The Minuses of Generic Open-Source Datasets
There are lots of popular open-source datasets that have helped AI learn sentiment. For example, IMDB movie reviews have thousands of labeled reviews saying whether a movie is good or bad. Other datasets, like TweetEval, capture short, slang-filled social media posts. There are also financial datasets, product reviews from Amazon or Yelp, and even multilingual or mixed media datasets on platforms like Hugging Face. They are all free, easy to use and can be used for testing ideas or building simple models.
But these generic datasets aren’t enough for real business needs. They are broad, but shallow. They teach AI the language of movies, social media, or general reviews. Consider these stark contrasts to see the possible complications:
- Healthcare vs. retail. In a generic dataset, the word “sick” is always negative. In a dataset of sneaker reviews, “These kicks are sick!” is a strong positive. A model trained on general data would simply fail spectacularly in a specialized context.
- Legal vs. social media. The statement “The motion was sustained” is a neutral fact in a legal dataset. Language is precise and unemotional. On Twitter, sentiment is conveyed through emojis, slang, and hyperbole. A generic model trained on social chatter would be useless for analyzing legal document sentiment, and vice versa.
- Financial markets. Here, sentiment is often signaled by implication and market context. “The company delivered steady growth” may be coded as positive in a general sense, but if analysts were expecting explosive growth, the same phrase could carry a negative sentiment for traders. The ground truth is relative to market expectations.
The Necessity of a Custom Sentiment Analysis Dataset
A custom sentiment dataset is essential for accurate, real-world AI. Language changes fast – new slang, industry jargon, and cultural references appear constantly, and generic datasets can’t keep up. When you build a dataset from your own sources, for example, customer reviews, support tickets, surveys, and internal reports, you teach AI the specific language of your business. It starts to understand your business world.
A custom dataset is also a competitive asset. A model trained on your own data captures your brand voice, your industry nuances, and your customers’ expressions. You will never achieve it with a generic dataset. The algorithm is the tool, but the dataset is the knowledge base that turns AI from a guesser into a true expert.
Industry Use Cases
Today, businesses use Natural Language Processing to solve practical problems. Sentiment analysis is not a nice-to-have” metric but an integral part of smart decision-making. Let’s look at some real-world sentiment analysis examples to see how understanding the feelings and opinions behind text can give companies a competitive edge and make their operations more efficient.
Finance – Trading Based on News Sentiment
Financial markets don’t move based on numbers alone. Many things also depend on emotions like fear, optimism, and uncertainty. Of course, investors reacе to facts, but they also react to how news sounds and feels. Sentiment analysis is an important tool in modern trading. Studies of financial news and online discussions show that changes in sentiment appear right before actual price movements, and these changes are closely connected to earnings reports, economic data releases, or major global events.
Many banks, hedge funds, and trading firms now use sentiment analysis to process huge amounts of information in real time. Traders rely on AI models that scan headlines, analyst notes, and social media posts and turn them into clear sentiment signals. For example, platforms used by firms like Bloomberg and JPMorgan include sentiment indicators that highlight unusually positive or negative news around specific companies or markets.
Overall, sentiment analysis helps traders react faster, manage information overload, and spot early signs of risk or opportunity. It doesn’t replace traditional financial analysis, but it adds valuable insight into market mood.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Politics – Analyzing Voter Sentiment
Voters don’t always express their opinions neatly in surveys, but they do express emotions –frustration, hope, anger, excitement – constantly online. This is where sentiment analysis becomes especially useful. A recent large-scale study of political discourse on social media showed that sentiment analysis can detect shifts in public opinion during major political events, such as debates, scandals, or policy announcements. This research studied over 10 million social media posts from different platforms during the 2023–2024 election cycle to see how well sentiment analysis can capture public opinion.
The researchers used the BERT model to analyze emotions and reactions to political debates, announcements, and campaigns. They found a strong link between online sentiment and real election outcomes. Sentiment patterns predicted major political events with about 78% accuracy. The study also showed that people express emotions differently across platforms and demographic groups, and it highlighted challenges such as echo chambers and algorithm bias.
Overall, the research shows that sentiment analysis can be a powerful tool for understanding voter mood when context, platform differences, and data quality are carefully considered.
Customer Experience (CX) – Automating Support Ticket Routing
Companies with large customer bases, for example, Amazon, Airbnb, and telecom providers, receive massive volumes of support messages every day. They use sentiment analysis to decide which issues need urgent human attention and which can be handled automatically.
For instance, Amazon’s support systems analyze incoming messages to detect frustration or escalation. A ticket saying “This is the third time I’ve contacted support” may be flagged as high-risk even if the tone is polite. These cases are routed to experienced agents, and neutral requests go through standard workflows.
Airbnb uses similar techniques to monitor host and guest communications. When sentiment signals conflict or emotional distress, cases are escalated to trust and safety teams faster, and this prevents worse disputes.
Over time, CX teams also analyze sentiment trends to spot systemic issues. A spike in negative sentiment after an app update or policy change is an important early warning, which comes before churn or bad press appears.
Product Reviews & Feedback – Turning Opinions into Action
Companies like Apple, Netflix, and Shopify merchants always analyze their customers’ geographics and behavior. But they also process customer reviews at scale to understand why users are happy or unhappy.
Sentiment analysis allows companies to go beyond simple “positive” or “negative” labels. The system doesn’t treat a review as one emotion, but breaks it into specific aspects such as usability, performance, pricing, content quality, or customer support. For example, Netflix may see that overall sentiment is positive, but sentiment around recommendations or content discovery is becoming increasingly negative. That insight gives product teams a clear direction on what needs fixing.
This approach enables businesses to prioritize changes. If many users praise performance but complain about pricing or customer service, teams can focus resources where frustration is highest. Over time, tracking sentiment trends shows whether product updates actually improve customer perception.
Review language changes fast as new slang, sarcasm, emojis, and exaggeration appear, so sentiment analysis in machine learning must be trained on fresh, domain-specific data. Models built on outdated or generic datasets often miss subtle complaints or misunderstand praise.
Conclusion
We’ve explored the basics of sentiment analysis in AI. Now you have an idea of how text is processed and models are trained. You’ve also learned about more advanced techniques like aspect-based and emotion detection, and real-world uses in finance, politics, and customer experience. One thing becomes clear very quickly – the technology itself is no longer the hard part. Modern NLP models, open-source tools, and cloud APIs are widely available. Almost anyone can access powerful algorithms. What truly makes the difference is the data.
High-quality, human-annotated data is what teaches an AI to understand real human language. It enables models to recognize sarcasm in a tweet, understand negation in a frustrated review, detect small but important shifts in product feedback, and interpret emotion across different languages and cultures. Without carefully labeled examples, sentiment models miss the nuance that actually drives decisions.
That’s why generic, off-the-shelf datasets often fall short in real business settings. Real-world language is messy, emotional, and highly specific to each industry. If you want sentiment analysis that works reliably in practice and handles complex feedback, domain-specific language, and real customer emotion, you need more than just good models. You need the right data.
Tinkogroup specializes in high-quality sentiment annotation. We build custom datasets designed for real-world use. Whatever your business direction is, we help your AI truly understand what people mean.
Ready to move from basic sentiment tracking to insights that may repower your business? Explore Tinkogroup’s Annotation Services and build AI that reads between the lines.
Why is human annotation better than automated sentiment analysis?
While AI can process data at scale, it often misses nuances like sarcasm, cultural slang, and context-dependent meanings. Human annotators provide the “ground truth” by understanding the emotional intent behind the words, ensuring the AI learns to interpret language as a human would, not just as a dictionary.
What is the difference between Binary and Aspect-Based Sentiment Analysis?
Binary analysis is a simple “positive vs. negative” check, ideal for quick overviews. Aspect-Based Sentiment Analysis is more detailed; it identifies specific features (e.g., “battery life” or “pricing”) and assigns a sentiment to each, providing actionable insights for product improvement.
How can I ensure the quality of my sentiment dataset?
Quality is maintained through Inter-Annotator Agreement (IAA), where multiple experts label the same data to ensure consistency. Additionally, implementing a Human-in-the-Loop (HITL) system allows humans to review low-confidence AI predictions, creating a continuous cycle of improvement and accuracy.


