
Semantic segmentation is one of the critical technologies that helps computers “see” and understand visual content in the same way humans do. It plays a vital role in the development of artificial intelligence (AI) and machine learning (ML), especially in areas where the accuracy and speed of image analysis are essential.
But what does “semantic segmentation network” really mean? How does it work, and why has it become so crucial for modern technologies? In this guide, we’ll discover the basics of semantic segmentation model, its mechanics, and its various applications.
What is semantic segmentation?
Regarding semantic segmentation meaning, it is a computer vision technique. This allows algorithms to recognize objects in an image and identify each pixel as belonging to a certain class.
For instance, semantic segmentation dataset can split the image into a street photograph, labeling each section as a road, building, car, tree, etc. Each pixel receives a specific semantic label according to the object class to which it belongs, allowing the algorithm to understand the image better.
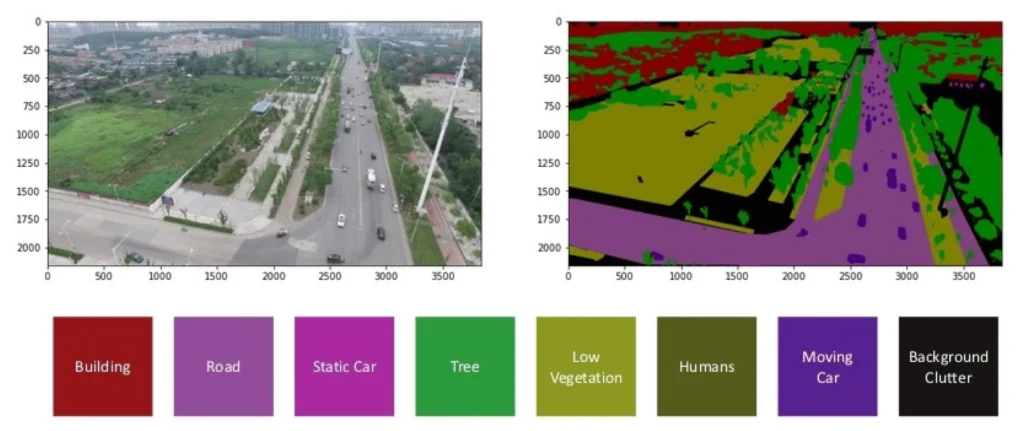
Unlike methods that work only with the whole image, the semantic segmentation model dives into detail, making the picture understandable and convenient for analyzing each element. This allows you to accurately identify and understand the boundaries between objects in the image.
Semantic segmentation vs image classification
The primary difference between image classification and semantic segmentation datasets is the level of detail obtained during the analysis. Image classification is a method by which an algorithm determines whether an image contains a particular object or class of objects.
For example, an algorithm can classify an image as “cat” or “dog,” but it does not separate each element in the image. This is similar to a general definition of the subject but without the analysis of each element.

On the other hand, in the semantic segmentation network, each pixel is defined as belonging to a specific category and grouped into corresponding areas in the image belonging to a specific class. As a result, a “map” is created, where each class of objects has its own color or designation. This provides a clear and structured image with a precise division into categories. This approach makes computer vision much more profound, and the result is more accurate.
Semantic segmentation vs instance segmentation
Another related technology is instance segmentation, which also highlights objects in an image but adds another level of detail. Unlike semantic segmentation, which focuses on classes of objects, instance segmentation separates not only by classes but also by each specific instance of an object.
For example, suppose there are multiple chairs in an image. In that case, semantic segmentation model will identify them all as “chairs,” and instance segmentation will highlight each individual chair and assign it a unique label.
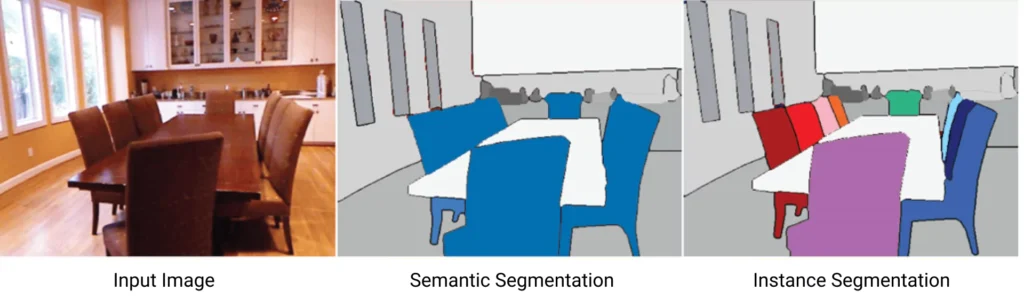
Regarding instance segmentation vs semantic segmentation issue, instance segmentation is important when general categories and specific objects need to be recognized for further analysis or interaction. For example, this can be critical in autonomous vehicles to avoid collisions, as each object needs accurate identification. In cases where the task is a general understanding of the scene, semantic segmentation is sufficient. However, when tasks require tracking joints, facial landmarks, or object structure rather than full regions, teams often rely on keypoint annotation in computer vision.
How does semantic segmentation work?
Deep learning semantic segmentation is a complex process based on machine learning and computer vision advances. It includes several important steps and techniques that allow algorithms to identify and classify each image pixel accurately.
Overview of the main processes of semantic segmentation
In fact, semantic segmentation works by step-by-step image analysis to identify classes of objects based on pixel information. Semantic segmentation algorithms first pre-process the image, which may include color normalization, noise removal, and other steps that improve the quality of the data. A machine learning model is then used to analyze the image on a pixel-by-pixel basis, assigning a specific category to each pixel.
The fundamental goal is to create a complete map of the image, where each pixel is labeled according to a feature class such as “person,” “machine,” “tree,” etc. This process breaks the scene into segments based on context, allowing the algorithm to create a complex interpretation of the image.
Machine learning algorithms play a prominent role in the semantic segmentation datasets. They use a huge number of pre-labeled images to train a model that is able to identify classes of objects in new images. The most common methods are convolutional neural networks (CNN) and their modifications.
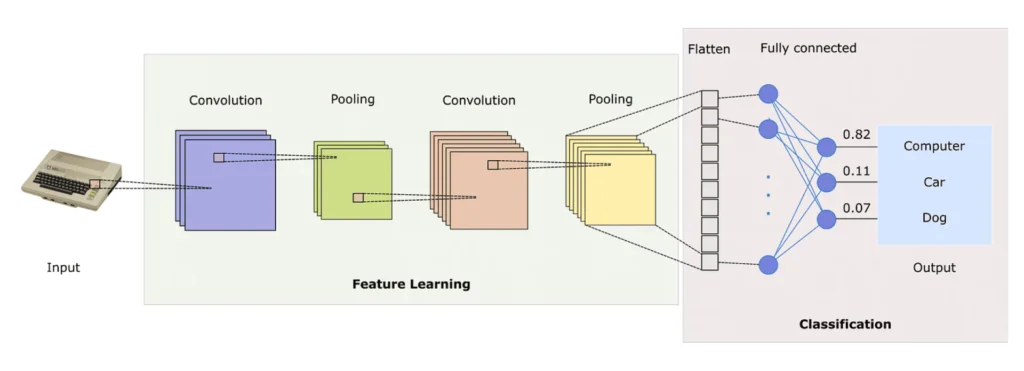
Convolutional neural networks are the basis for many semantic segmentation models. CNNs have layers that detect features of objects by analyzing texture, shapes, colors, and other details in an image. The deep layers of the CNN are trained to detect more complex features that allow more accurate identification of objects in complex scenes.
Main models used for semantic segmentation
Several best semantic segmentation models have been developed to perform semantic segmentation tasks. Each has its characteristics and approaches to pixel-level image analysis, making them suitable for different functions.
U-Net
This is one of the most popular semantic segmentation models, especially in medical diagnostics. It was designed to segment images with high accuracy even when a limited amount of training data is available. The crucial feature of U-Net is its architecture, which consists of two symmetrical parts: a downsampling path and an upsampling path. The first path extracts image features at different levels, and the second restores spatial resolution, which allows for a detailed pixel map.
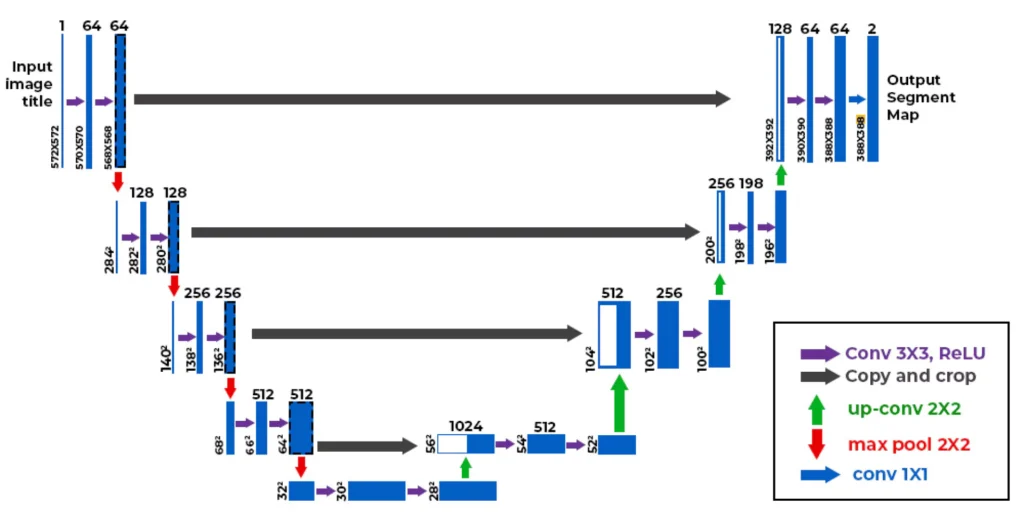
U-Net uses a layer of connections (skip connections), combining features with reduced resolution and corresponding levels in the extension path. This helps preserve details of objects more accurately and ensures high-quality segmentation, which is especially important in medical diagnostic tasks, where every pixel can be important for diagnosis.
Fully convolutional networks (FCN)
It is another essential approach in semantic segmentation networks. FCN differs in that it uses only convolutional layers instead of traditional fully connected layers, which allows it to work with images of any size. This method was originally created to adapt CNNs for semantic segmentation tasks, and it became the basis for many other models.
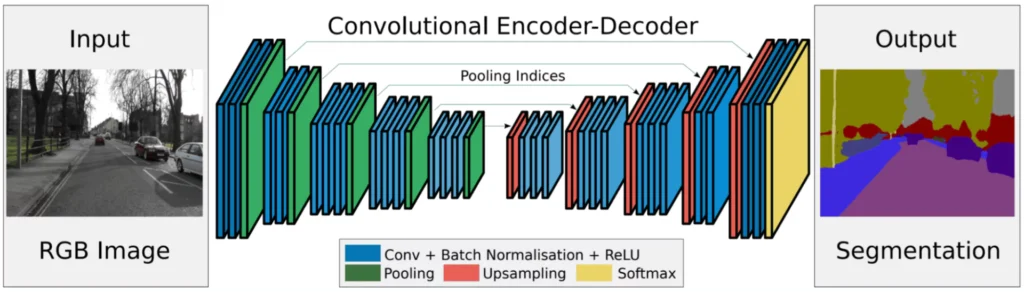
FCN goes through several stages of convolution, extracts the critical features of the image, and then uses layers that expand the dimension to create a segmented image. This provides a detailed classification of pixels by class. This is suitable for various tasks, such as the segmentation of landscapes or urban scenes, where it is important to identify several objects in the same scene.
Mask R-CNN
It is an extension of the R-CNN model and simultaneously performs two tasks: semantic segmentation and instance segmentation. Like its predecessor, Mask R-CNN selects areas in the image that may contain objects but also allows you to determine the exact boundaries of each object in these areas.
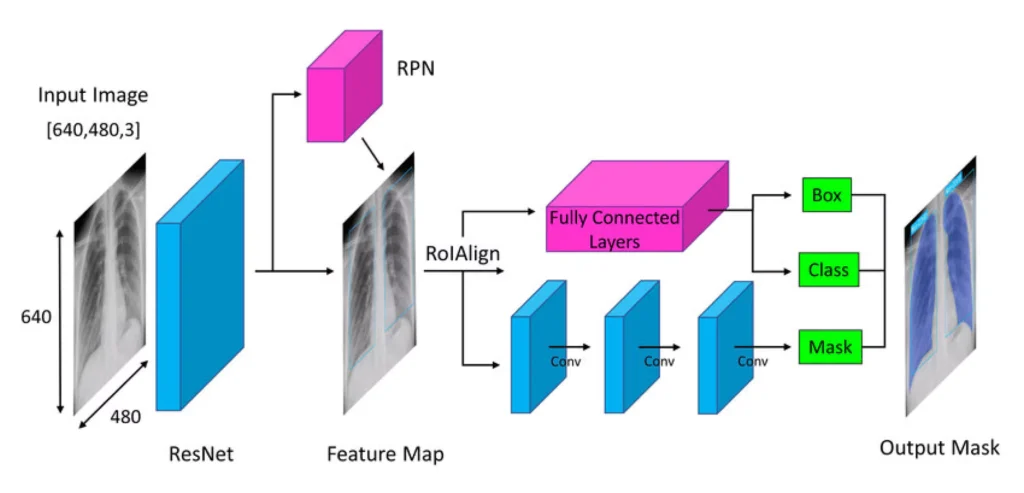
This is especially useful for tasks where it is essential to determine the object’s class and distinguish each instance separately. For example, in scenes with a large number of people, masked R-CNN can segment each person as a separate instance. This is a significant advantage in video surveillance systems or augmented reality (AR) applications where interaction with individual objects is critical.
DeepLab
It is a series of semantic segmentation models designed to improve image processing quality and object recognition accuracy by introducing various innovations in convolutional networks. One of the main innovations introduced by DeepLab is the use of dilated convolutions.

Dilated convolutions allow you to increase the field of view of neurons without reducing the image’s resolution. This means that the model can take into account wider contexts for each pixel while maintaining a high level of detail at the pixel level. This approach is especially useful for analyzing objects at different distances, as it allows you to recognize near and far objects with the same accuracy.
Pyramid scene parsing network (PSPNet)
This network was developed to improve the quality of image semantic segmentation, especially when considering both local and global contexts is essential. It uses a pyramid parsing method that allows the model to capture information at different levels of resolution, which increases its ability to recognize complex scenes.
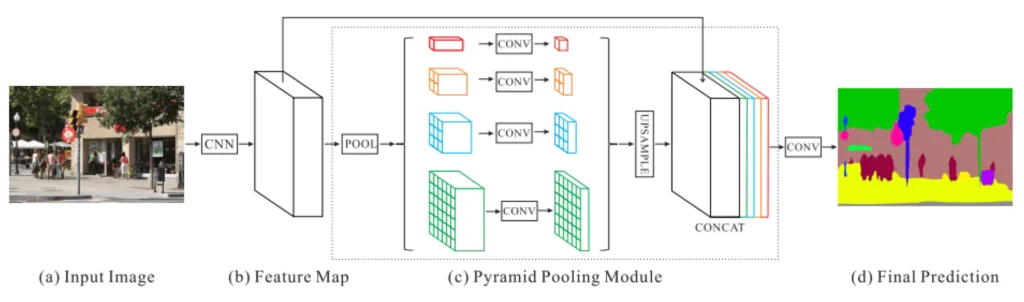
PSPNet divides the image into pyramidal blocks of different sizes, which allows different levels of information about the scene to be obtained. Thanks to this, the model can handle both large and small details at the same time while preserving the context and structure of the scene.
Why does semantic segmentation matter?
Semantic segmentation algorithms increase the productivity and quality of decisions by reducing the need for human intervention to make decisions in critical scenarios. Systems that use semantic segmentation are more informative and can analyze complex scenes independently.
How semantic segmentation powers AI innovation
One of the critical advantages of semantic segmentation models is its ability to improve the accuracy and reliability of computer vision significantly. This is particularly important for AI, enhancing its ability to analyze real-world scenes with pixel-level detail. Thanks to this segmentation, algorithms can recognize objects in the general context and at each pixel, determining a specific object class.
Understanding what exactly is depicted in each fragment of the image helps the AI to make more informed decisions, which is critical in many complex and sensitive scenarios. For example, autonomous vehicles must correctly recognize identical parts of different objects (road, pedestrians, road signs) for safe driving.
If the system cannot distinguish a pedestrian from other objects or recognize the boundaries of the road, it can lead to emergency situations. Semantic segmentation datasets help such systems to ensure safe, reliable operation even in complex and unpredictable conditions.

Benefits of semantic segmentation for various industries
Medicine
In medical diagnostics, semantic segmentation models help in the accurate detection of pathologies in medical images. This is particularly useful in fields such as radiology, where the boundaries of tumors or other abnormalities must be precisely defined.
CNNs integrated with semantic segmentation methods are able to identify even the smallest pathological changes that may go unnoticed by the human eye. Thanks to such technology, the quality of diagnosis improves, and the accuracy of treatment increases, which, in turn, positively affects patients’ health.
Agro-industry
In agriculture, semantic image segmentation is used to recognize different types of vegetation, identify pests, and assess the condition of crops. Farmers can implement more efficient processing of land plots and optimize costs for fertilizers, water supply, and other resources.
For example, accurate segmentation allows artificial intelligence systems to distinguish healthy from diseased plants and apply appropriate processing methods. This leads to increased productivity and optimization of agricultural production processes.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Retail and consumer behavior analytics
Computer vision semantic segmentation helps video management systems identify the behavioral patterns of shoppers in a store, which is valuable information for marketers and store owners. For example, the system can recognize and analyze which store areas receive more customer attention, which products attract more attention, and how customers move between shelves.
In general, this data helps optimize product placement, increase sales, and improve the customer experience.
Ecology and management of natural resources
Semantic image segmentation helps track changes in natural landscapes and monitor the environment. For example, segmentation technologies can detect changes in green vegetation, predict the spread of pests, or control water pollution. This helps to take timely measures to protect natural resources and combat environmental problems.
Common challenges in semantic segmentation
Semantic segmentation is a powerful tool in computer vision, but it faces some challenges like any technology. Understanding these problems will help better adapt algorithms and models to their actual use conditions.

1. Complexity of image processing
Images can have different lighting, viewing angles, and backgrounds, making it difficult to segment objects accurately. In cases where objects overlap or have similar colors and textures, algorithms may misclassify pixels, leading to segmentation inaccuracies.
2. Limited amount of annotated data
Training semantic segmentation models require large datasets with accurately annotated images. However, creating such sets is a time-consuming and costly process. Many industries face the problem of a limited number of annotated images, which negatively affects the quality of models. Without sufficient data, models may not be accurate enough when working with new, unfamiliar images.
3. Overlapping objects
In situations where objects overlap or have complex contours, semantic segmentation models may experience difficulties. Determining the exact boundaries between objects can be difficult, especially when dealing with scenes with a lot of detail.
For example, in natural landscapes, trees can merge with bushes, making it challenging to identify and classify each object.
4. Requirements for computing resources
The processes involved in semantic segmentation networks are usually computationally intensive, which can be a problem for some applications. To achieve high accuracy, models require significant computing power, especially when dealing with large amounts of data or high-quality images. This can make it difficult to implement semantic segmentation in systems with limited resources.
5. Universality of models
It has been observed that many semantic segmentation models are sensitive to specific learning conditions. This means that a model trained on one data set may perform poorly on others, even if they are visually similar. This problem makes it difficult to apply semantic segmentation in real-world environments where conditions may change.
Conclusion
Semantic segmentation models provide new opportunities for innovation in many industries by helping artificial intelligence understand and interpret visual data better. It allows you to create more accurate, safer, and efficient solutions. As technology develops, the importance of segmentation will only grow, improving the quality of automated systems.
Our professional company offers expert services to create high-quality segmented data for your computer vision and artificial intelligence needs. Contact us to help your business achieve accuracy and efficiency.
FAQ
What is the semantic segmentation approach?
The semantic segmentation approach is a computer vision technique that classifies each pixel of an image into a specific category, such as "car," "tree," or "building." This approach is crucial in autonomous driving, medical imaging, and more, where precisely understanding each image part is vital.
What is semantic and instance segmentation?
Semantic segmentation categorizes each pixel in an image into a single class, identifying areas like "road" or "car." Instance segmentation classifies each pixel and identifies each unique instance within a class. These tactics are widely used in robotics, augmented reality, and video analytics.
What are the 7 semantic categories?
Although categories can vary depending on the dataset and project goals, common examples might include person, vehicle, nature, building, furniture, animals, and background.


