

For any human eyes looking into and analyzing a street scene, instantaneous recognition flashes: humans, cars, trees, road signs, and sky. For machines, however, one must go into thousands of calculations and must entail training for rigorous, methodical comprehension of visual data. Therefore semantic segmentation is the backbone of the computer vision ecosystem.
Semantic segmentation could really be seen as a procedure, aiming towards letting machines understand exactly what every pixel in an image represents. Classic object detection might merely put in bounding boxes loosely around a vehicle or pedestrian, whereas semantic segmentation goes further than that. It doesn’t simply say, “there is a car,” but instead discreetly identifies the exact pixels that belong to that car, contrasted against the pixels of road, sidewalk, or background.
Technically speaking, semantic segmentation in computer vision involves assigning a class label to every pixel in the image. It results in a class map, which is a pixel-level annotation mask discriminating regions of interest into pre-specified categories such as “car,” “building,” “sky,” or “person.” This higher-level and more precise information about the scene allows for a deeper understanding than bounding boxes, providing only rough spatial containment.
The semantic segmentation value becomes apparent in modern AI-based applications whose outcomes might hinge on pixel-level accuracy. In autonomous driving, it can guarantee the precise detection of things like road lanes, signs, curbs, and obstacles. It pinpointedly specifies the borders of tumors or organs with extreme sensitivity in medical imaging, while in agriculture, it distinguishes crops from weeds using aerial or satellite images. All these applications depend on fine-segmented images to make automated decisions that require contextual understanding, which bounding boxes cannot provide.
By moving beyond rectangular detection and into the realm of dense, per-pixel classification, semantic segmentation offers a more advanced, structured, and context-aware interpretation of visual data. It is not just an evolution of object detection, but a necessary step toward full-scene understanding in intelligent systems.
What Is Semantic Segmentation?
One of the key computer vision areas, semantic segmentation helps imbue images with a detailed understanding through meaningful assignment of labels to each pixel. This fine level of classification is different in differentiating and locating objects, as it gives an artificial intelligence ability to comprehend a complex scene at such a granular level.
Semantic segmentation, in a way, means pixel classification — each pixel in an image is classified into a certain category. To continue the previous example, an urban street scene could have pixels labeled as “road,” “sidewalk,” “vehicle,” or “pedestrian.” Because of the dense nature of the image masks, semantic segmentation identifies each pixel in the image corresponding to a class with both exact shape and location; this is quite different from common classification and detection scenarios.
Differentiate it from, semantic segmentation vs object detection, semantic segmentation vs instance segmentation:
- Object detection. Object detection identifies and locates objects by drawing bounding boxes around them. It answers the question, “Where are the objects?” but does not provide precise shapes or boundaries.
- Instance segmentation. Instance segmentation takes pixel-level classification a step further by differentiating between separate instances of the same class. For example, it distinguishes in
dividual cars or people in a crowd, whereas semantic segmentation would label all pixels belonging to “car” as one class without separation.

Semantic segmentation finds practical applications across diverse fields:
- In urban street scenes, it helps autonomous vehicles by clearly identifying roads, sidewalks, vehicles, and pedestrians, facilitating safe navigation.
- In medical imaging, it delineates organs, tumors, and other structures with high precision, assisting diagnostics and treatment planning.
- In agriculture, aerial imagery can be segmented to separate crops from weeds or soil, enabling targeted interventions.
To visualize the difference, imagine object detection as placing simple rectangles around items on a cluttered desk — you know roughly what’s inside each box, but the exact shape remains unknown. Semantic segmentation, in contrast, is like tracing the exact outline of every object on the desk, revealing their true form and position. This pixel-precise labeling enables much richer scene understanding, critical for advanced AI applications.
How Semantic Segmentation Works
How does semantic segmentation work? Semantic segmentation follows a structured pipeline that transforms a raw input image into a detailed pixel-level understanding of the scene. The process typically involves three key stages: taking the input image, performing pixel-wise classification, and producing an output mask that highlights the labeled regions.
At the start, the input image—whether it is a street photo, a medical scan, or satellite imagery—is fed into a deep learning model designed specifically for segmentation tasks. The model analyzes every pixel, assigning a probability that the pixel belongs to a particular class. This results in a pixel-wise classification, where the model predicts labels for each pixel independently but considers spatial context.
The final output is a segmentation mask, often visualized as a colored overlay on the original image, where each color corresponds to a different class. This mask is essentially a class map—a 2D grid where each pixel’s value represents its predicted category.
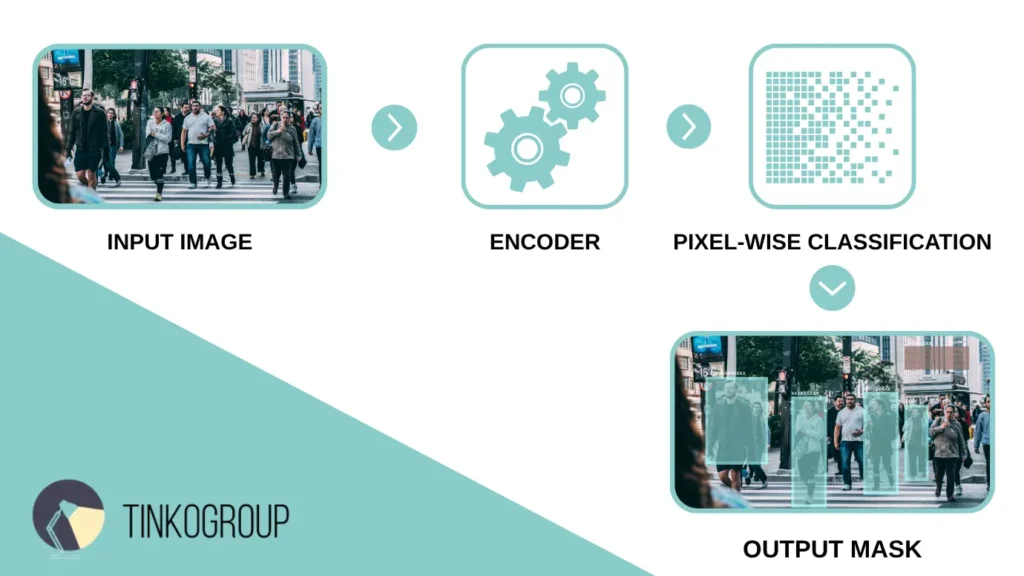
Common Semantic Segmentation Architectures. Several well-established neural network architectures underpin semantic segmentation models. Each brings its own approach to balancing precision, computational efficiency, and contextual awareness:
- Fully convolutional networks (FCN). One of the pioneering models, FCN replaces fully connected layers with convolutional ones to produce spatially dense predictions. It laid the foundation for pixel-level tasks by enabling end-to-end training on segmentation masks.
- U-Ne. Originally developed for biomedical image segmentation, U-Net introduced an encoder-decoder structure with skip connections. These skip connections help retain fine-grained spatial details by combining high-level semantic information with low-level image features.
- DeepLab. This architecture utilizes atrous (dilated) convolutions and spatial pyramid pooling to capture multi-scale context, improving accuracy on complex scenes. DeepLab models are widely used in applications requiring detailed segmentation.
- Mask R-CNN. Though primarily an instance segmentation model, Mask R-CNN also produces pixel masks by extending object detection frameworks to include a mask prediction branch, effectively combining detection and segmentation.
Understanding Class Maps, Heatmaps, and Overlays. What is semantic segmentation used for? To fully grasp how the best semantic segmentation models convey their predictions, it is essential to understand the key visualization outputs: class maps, heatmaps, and overlays. These representations help translate raw model data into interpretable images, allowing practitioners to evaluate model performance and communicate results effectively. Each serves a distinct purpose in illustrating how pixels are classified and with what confidence.
- A class map is the core output, assigning each pixel a label. It’s typically represented as a grayscale or color-coded image where pixel values correspond to classes.
- A heatmap shows the confidence levels of the model’s predictions per pixel, often highlighting areas with high uncertainty.
- An overlay is a visualization technique where the segmentation mask is superimposed on the original image with transparency, enabling intuitive understanding of which regions belong to each class.
Analogy. Imagine semantic segmentation as the digital equivalent of coloring a complex coloring book—but instead of a child using crayons, an AI system uses mathematical models to fill in each space with precise intent.
Consider a photograph of a bustling city street. A simple object detection model might draw rectangles around the cars, pedestrians, and buildings. This is useful, but it’s like circling items with a marker—it tells you where something is, but not its shape or exact footprint.
Now, picture a segmentation model working on that same photo. Instead of rectangles, it goes pixel by pixel, carefully “painting” every pedestrian in blue, every car in red, the road in gray, and the trees in green. It doesn’t just know that a tree exists — it knows exactly where every leaf begins and ends. This level of detail is what makes semantic segmentation so powerful.
To make it even more relatable, think about how Google Maps satellite view differs from the map view. The map might outline parks, roads, and rivers with simplified blocks. The satellite view, however, shows exactly where the trees are, how buildings cast shadows, and where the pavement meets the grass. That transition from generalized shape to high-resolution understanding is precisely what semantic segmentation achieves in AI.
For developers, it’s like moving from a wireframe to a rendered 3D model. For machines, it’s the difference between guessing where something is and truly “seeing” it.
Key Use Cases
Semantic segmentation plays a pivotal role in various industries by enabling machines to interpret visual data at a granular level. Below are some real-world applications:
- Autonomous Vehicles – Lane and Road Segmentation. In autonomous driving, semantic segmentation is crucial for identifying drivable areas, lane boundaries, and obstacles. For instance, the “Lane Area Semantic Segmentation” model assists self-driving cars in accurately understanding road lanes, facilitating safer navigation.
- Medical Imaging – Tumor and Organ Boundary Detection. In healthcare, semantic segmentation aids in delineating tumors and organs from medical scans. For example, MedSAM, a universal model, segments various anatomical structures and pathologies across different imaging modalities.
- Agriculture – Crop Segmentation from Aerial Imagery. Semantic segmentation is employed in agriculture to monitor crop health and detect anomalies. Research utilizing the Agriculture-Vision dataset demonstrates how segmentation models can identify weed clusters, nutrient deficiencies, and other agricultural anomalies from aerial imagery.
- Satellite Imaging – Land Use Classification. Satellite imagery analysis benefits from semantic segmentation to classify land into categories like urban areas, forests, and water bodies. Studies show that deep learning models can effectively segment land cover types, aiding in environmental monitoring and urban planning.
- AR/VR – Separating Objects from Background. In augmented and virtual reality, semantic segmentation enhances user experience by accurately separating foreground objects from backgrounds. This segmentation allows for realistic integration of virtual elements into real-world scenes, improving interaction quality.
Benefits of Semantic Segmentation
Semantic segmentation offers distinct advantages that make it indispensable in advanced computer vision applications. Its ability to analyze images at a granular level unlocks benefits far beyond those achievable with simpler techniques.
Precise Object Boundary Detection. One of the most significant strengths of semantic segmentation is its capability to detect exact object boundaries. Unlike bounding boxes that enclose an object with rough rectangles, semantic segmentation outlines the true shape of objects at the pixel level. This precision is critical in domains like medical imaging—where accurately identifying tumor margins can influence treatment decisions—and in autonomous driving, where distinguishing the exact edges of obstacles can prevent accidents.
Useful for Decision-Making in Automation. By providing detailed, pixel-level information, semantic segmentation enables automated systems to make more informed and safer decisions. For example, in industrial automation, robots equipped with segmentation models can differentiate between objects and background materials, allowing for precise manipulation or sorting. In agriculture, drones use segmentation data to target specific areas needing treatment, optimizing resource use and crop yield.
Enables Pixel-Level Understanding vs Region-Level. Unlike traditional image analysis techniques that classify broad regions or entire objects, semantic segmentation empowers machines with pixel-level understanding. This finer granularity supports applications requiring contextual awareness—such as separating overlapping objects, understanding scene composition, and identifying subtle texture differences. This level of detail ensures that AI systems can respond to complex environments with higher accuracy and reliability.
Types of Segmentation
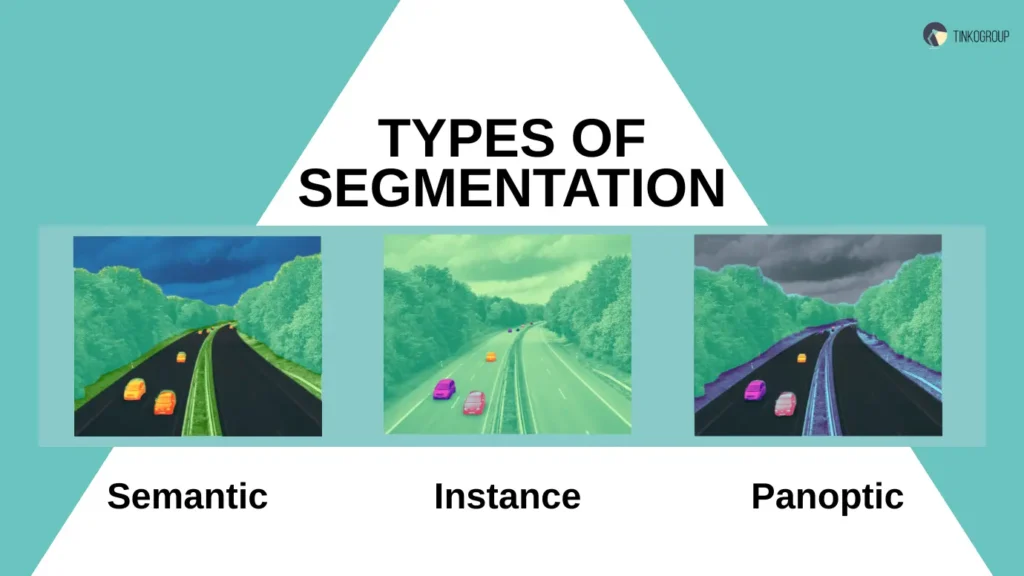
Semantic segmentation is part of a broader family of image segmentation techniques in computer vision. Understanding the differences between these types is essential for selecting the right approach based on the task requirements. Below is a comparison of the three main segmentation types:
| Type | Description | Granularity | Example Use Case |
| Semantic | Assigns a class label to every pixel, grouping all objects of the same class together without distinguishing individual instances. | Class-level | Tumor detection in medical imaging, where all tumor pixels are labeled regardless of separate tumors. |
| Instance | Distinguishes individual objects within the same class by assigning unique IDs to each instance. | Instance-level | Counting people in a crowd or tracking individual vehicles in traffic surveillance. |
| Panoptic | Combines semantic and instance segmentation to provide a full-scene understanding, labeling all pixels with class and instance information. | Full scene | Autonomous vehicle perception, where both object classes and individual instances are crucial for navigation. |
Annotation Techniques for Semantic Segmentation
Creating high-quality datasets is fundamental for training effective semantic segmentation models. The process centers on precise pixel-level labeling, which can be performed either manually or with assisted tools.
Pixel-Level Labeling: Manual vs Assisted. Manual annotation involves human annotators carefully labeling each pixel, which ensures high accuracy but is extremely time-consuming and labor-intensive. To speed up this process and reduce human error, many teams employ assisted annotation tools that leverage AI models to generate preliminary masks. Annotators then review and refine these masks, balancing efficiency with precision.
Tools: Labelbox, CVAT, V7
Several specialized tools support semantic segmentation annotation:
- Labelbox. A collaborative platform offering AI-assisted labeling, workflow management, and quality control features.
- CVAT (Computer Vision Annotation Tool). An open-source tool widely used for pixel-level annotations with support for mask editing, interpolation, and integration with machine learning pipelines.
- V7. A cloud-based tool providing automation-assisted labeling, version control, and powerful visualization options tailored for segmentation projects.
Choosing the right tool depends on project scale, budget, and required annotation quality.
Challenges in Semantic Segmentation
While semantic segmentation has become essential in advanced computer vision systems, implementing it successfully at scale is far from trivial. From the complexity of data annotation to the technical hurdles in training models, the path to high-performing segmentation pipelines presents a range of challenges. Understanding and proactively addressing these obstacles is critical for building trustworthy, production-ready AI systems.
Labor-Intensive Labeling. Perhaps the most immediate bottleneck in semantic segmentation projects is the sheer volume of manual work required. Unlike bounding box annotations, which can be completed in seconds, drawing detailed masks for each object class—especially in high-resolution images—can take several minutes per image. In video segmentation, the time required compounds rapidly, as each frame must be carefully labeled or interpolated with minimal drift.
This becomes especially problematic in domains like medical imaging, where annotators need not only labeling skill but also domain-specific expertise. In these cases, radiologists or trained technicians must be involved, increasing costs and limiting scalability.
Tinkogroup Expert Tip: Leverage hybrid pipelines that combine AI-assisted labeling tools with manual review workflows. Pre-annotations generated by models can reduce initial effort by up to 70%, allowing skilled annotators to focus on accuracy refinement and edge cases.
Class Imbalance. A frequent issue in real-world datasets is class imbalance—some object categories appear in far greater numbers than others. For instance, in urban street scenes, pixels labeled as “road” or “sky” may vastly outnumber those labeled “pedestrian” or “traffic light.” When not properly addressed, this imbalance biases models toward dominant classes, resulting in poor generalization and unreliable predictions for minority categories.
Correcting for class imbalance may require targeted data collection, oversampling techniques, or weighted loss functions during model training. But these strategies are only effective when the underlying annotation accurately reflects the true diversity of the environment.
Tinkogroup Expert Tip: During dataset planning, analyze pixel distribution across classes early on. If necessary, re-balance through strategic sampling or synthetic data augmentation. Always validate performance on minority classes with class-specific IoU metrics.
Overlapping Classes and Occlusions. Many scenes contain visually overlapping objects or instances from different classes in close proximity—people walking in front of cars, trees partially obscuring buildings, or transparent objects like glass or water. These cases introduce uncertainty not only for the model but also for the human annotators. Deciding where one object ends and another begins is often subjective, especially without 3D context or additional sensory input.
Overlapping classes also increase the risk of annotation inconsistencies across a dataset. One annotator may segment the full occluded object, while another may only label the visible part. This inconsistency leads to noise in the training data and confuses the model during learning.
Tinkogroup Expert Tip: Use layered annotation policies, where each class is assigned a visibility priority. Provide clear documentation on how to treat occluded areas and train annotators with examples. Consider panoptic segmentation when both class and instance precision are required.

Ambiguous Object Boundaries. Semantic segmentation demands a level of precision that’s often unattainable in visually ambiguous conditions. In cases with blurred edges, shadows, reflections, or low-contrast textures, defining a “correct” boundary becomes subjective—even among experts. For instance, separating fog from background objects, or delineating skin from clothing in thermal imagery, often involves interpretive judgment.
These gray areas lead to label noise—inconsistencies that weaken model training and reduce reliability in deployment environments. Over time, the accumulation of small boundary errors can result in significant drops in performance, especially in applications where pixel-level accuracy is critical.
Tinkogroup Expert Tip: To improve annotation reliability in ambiguous cases, adopt consensus-based labeling (multiple annotators per image), and conduct cross-validation reviews. Label uncertainty can also be incorporated into the model itself through soft labels or Bayesian training approaches.
High Cost of QA at Scale. Maintaining annotation quality becomes exponentially harder as dataset sizes increase. When thousands—or even millions—of images are involved, manually reviewing each label becomes infeasible. Yet a single faulty batch of annotations can significantly degrade model accuracy.
Automated QA tools for segmentation remain limited compared to classification or object detection. Metrics like mIoU offer high-level insights but may miss systemic issues like mask bleed, inconsistent class labeling, or missing small objects.
Tinkogroup Expert Tip: Integrate QA checks at multiple stages: initial labeling, post-annotation audits, and model-driven validation using confusion matrices and error heatmaps. Tinkogroup uses a layered QA semantic segmentation pipeline that combines sampling, AI-assisted error detection, and gold standard benchmarks to maintain label integrity across large-scale projects.
Best Practices for Semantic Segmentation Projects
Achieving high-quality semantic segmentation results depends heavily on the rigor and structure of the annotation process. Implementing semantic segmentation best practices ensures data integrity and improves model performance.
Clear Labeling Instructions. Providing annotators with comprehensive and unambiguous labeling guidelines is essential. Instructions should cover class definitions, edge cases, and handling of ambiguous regions to minimize inconsistency. Visual examples help annotators understand complex scenarios and align with project goals.
Annotator Training. Proper training and onboarding of annotators ensure they grasp the nuances of pixel-level labeling. Training sessions can include practical exercises, feedback loops, and updates on evolving annotation standards. Skilled annotators are more efficient and produce higher-quality masks.
Using Gold Standards and Review Loops. Integrating gold standard datasets — expertly annotated samples — into annotation workflows helps monitor annotator accuracy. Coupled with iterative review loops, this approach identifies and corrects errors early, maintaining dataset quality throughout the project lifecycle.
Validation Metrics (IoU, mIoU). Employing quantitative metrics is vital for evaluating annotation quality and model performance. The Intersection over Union (IoU) metric measures the overlap between predicted masks and ground truth, reflecting accuracy at the pixel level. The mean IoU (mIoU) averages IoU across all classes, providing a balanced view of model performance on diverse categories.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Tools for Semantic Segmentation
Selecting the right annotation tool is critical for the success of semantic segmentation projects. The semantic segmentation tools must balance usability, accuracy, collaboration capabilities, and integration with machine learning workflows. Below is an in-depth review of four popular annotation platforms that excel in different aspects.
CVAT. CVAT (Computer Vision Annotation Tool) is an open-source, web-based annotation platform developed by Intel. It is widely adopted in the computer vision community for tasks including semantic segmentation, object detection, and video annotation.
Key features:
- Advanced annotation tools. CVAT semantic segmentation offers polygon, brush, and superpixel segmentation tools, which allow annotators to create highly precise masks at the pixel level. Its interpolation feature helps streamline annotation for video frames by automatically propagating labels.
- Customizable workflows. Users can configure annotation pipelines to fit project-specific requirements, including task assignments, annotation stages, and review processes.
- Collaboration and management. CVAT supports multi-user environments with role-based access controls. Annotators, reviewers, and project managers can work concurrently, tracking progress and ensuring quality.
- Integration friendly. Being open-source, CVAT can be integrated into automated labeling workflows and custom ML pipelines, which is invaluable for continuous learning and large-scale projects.
Considerations: As an open-source tool, CVAT requires self-hosting and maintenance, which might need dedicated IT resources for optimal performance.
Labelbox. Labelbox is a commercial, cloud-based platform designed to simplify and scale data annotation, with a particular focus on enterprise needs.
Key features:
- AI-assisted labeling. Labelbox integrates pre-annotation features powered by machine learning, which can automatically generate segmentation masks that annotators then refine, significantly reducing manual effort.
- Project and quality management. The platform includes robust tools for workflow management, version control, and annotation auditing. This ensures consistent quality and helps identify annotator errors early.
- Collaboration. Real-time collaboration features allow teams to work simultaneously, assign roles, and monitor project progress via dashboards.
- Scalability. Its cloud infrastructure allows organizations to scale projects easily, supporting large datasets and numerous users without infrastructure concerns.
Considerations: Labelbox operates on a subscription model, which can be cost-prohibitive for smaller teams or academic projects.
V7. V7 is a cloud-native annotation platform that emphasizes speed and automation without compromising on annotation precision.
Key features:
- Smart segmentation tools. V7 employs AI to generate initial masks, enabling annotators to perform quick corrections rather than starting from scratch.
- Intuitive interface. The tool offers polygonal and brush-based annotation modes, combined with a streamlined user interface that reduces learning curves for new annotators.
- Collaboration and iteration. V7 supports real-time multi-user collaboration and integrates tightly with ML workflows, allowing continuous dataset improvement through iterative model retraining and active learning.
- Dataset management. It provides version control and detailed analytics on annotation progress and quality.
Considerations: While V7 offers a free tier, advanced features and enterprise-grade support require paid plans.
Labelme. Labelme is an open-source, lightweight annotation tool primarily used in academic research and small-scale projects.
Key features:
- Simple polygon annotation. Labelme provides basic polygon annotation capabilities suitable for semantic segmentation tasks, enabling annotators to label regions manually.
- Local deployment. It is easy to install and run locally, requiring minimal setup without the need for cloud infrastructure.
- Flexibility. The tool supports various annotation formats, making it compatible with many machine learning frameworks.
Considerations: Labelme lacks advanced features such as collaborative workflows, AI-assisted annotation, and project management tools, which limits its utility in larger or commercial projects.
Conclusion
Semantic segmentation has become a cornerstone of modern computer vision, enabling machines to understand the world with pixel-level precision. Unlike traditional detection methods that provide only rough outlines, segmentation delivers detailed, structured interpretations of scenes—essential for critical applications in autonomous driving, medical imaging, agriculture, AR/VR, and beyond.
Its power lies in its granularity: the ability to recognize not just what is in an image, but exactly where each element is, down to the pixel. This level of understanding is key for building intelligent systems that rely on accuracy, context, and real-time decision-making.
Whether you’re developing a self-driving system, training medical AI models, or building complex AR environments, the success of your project depends on the quality of your training data. That’s where expert annotation comes in.
Tinkogroup specializes in large-scale pixel-level labeling, custom, model-ready datasets, and high-accuracy annotations tailored to your unique project needs. Our experience across industries and deep understanding of quality assurance in annotation pipelines allow us to deliver data you can trust.
Want pixel-perfect segmentation for your AI project? Let’s talk.
FAQ
What is the main difference between semantic segmentation and object detection?
Object detection identifies and locates objects using bounding boxes—essentially drawing rectangles around items of interest in an image. Semantic segmentation, on the other hand, assigns a class label to every individual pixel in the image, creating highly detailed masks that capture the exact shape and location of each object. This allows for more precise understanding, especially in applications that require boundary-level accuracy.
Why is semantic segmentation so important in AI projects?
Semantic segmentation provides pixel-level detail that’s essential in industries where precision matters. In autonomous driving, it enables cars to differentiate between lanes, sidewalks, and road signs. In healthcare, it helps doctors and AI systems distinguish between tumors and healthy tissue in scans. In agriculture and remote sensing, it’s used to classify land cover or crop types with extreme spatial precision. Simply put, it enables machines to see and understand complex scenes with human-level granularity.
How does semantic segmentation handle overlapping or occluded objects?
Standard semantic segmentation treats all pixels of the same class as a single entity, which can cause issues when objects overlap (e.g., two people standing close together). To address this, more advanced approaches like instance segmentation or panoptic segmentation are used. These methods not only classify pixels but also assign them to individual object instances, helping models differentiate between overlapping or occluded elements.


