

Every computer vision model starts not with its architecture, but with data. Even the most modern neural network is useless without something to learn. For detection tasks, data must not only be collected but also carefully labeled. This is why the topic of correct annotations determines the success of detection model training.
The experience of many teams shows that without high-quality labels, a model cannot achieve high accuracy. In 2025, one engineer remarked in the article: “80% of success in computer vision depends on the data and only 20% on the model architecture.” And since then, this statement has only become more borne out in practice.
The main goal of this article is to demonstrate how labeling affects the training of detection models, what errors are most common, and how to streamline the process so that the final system produces consistent results.
Why Annotation Matters in Machine Learning
Annotations are the link between the human and machine worlds. A computer sees only pixels, and only labeling transforms a chaotic set of dots into information: “this is a cat,” “this is a traffic light,” “this is a tumor in the image.”
If labeling is poor, no retraining architecture will correct fundamental errors. Therefore, the quality of labels becomes the determining factor for AI model accuracy.
Explain Annotation Quality in Machine Learning
Annotation quality refers not only to the accuracy of object extraction but also to adherence to agreed-upon rules. The concept of segmentation annotation quality includes boundary accuracy, consistency between images, and class uniformity.
In practice, this looks like this: if in one image the object “bag” is labeled as “bag” and in another as “handbag,” the model perceives these as two different classes. As a result, annotation drift leads to a drop in metrics and problems with data generalization.

Real-World Consequences of Poor Annotations
The consequences of poor labeling are easily seen in the real world:
- In medical projects, incorrect tumor masks increased the error rate in annotations and reduced diagnostic accuracy by 10-15%.
- In transportation, the lack of bicycle labels in the dataset meant that the model “didn’t see” them on the road. This led to recognition errors and potentially dangerous situations.
- In retail, incorrect bounding boxes on product shelves led to frequent false positives during counting.
All these cases confirm that errors at the annotation stage have a greater impact on the system than flaws in the model architecture.
Building a Reliable Dataset for Detection Models
A reliable dataset is the foundation. Without it, even correct annotations won’t help. The approach to data collection should be systematic, with an emphasis on object detection dataset quality.
What Object Detection Training Data Should Look Like
A good dataset for training detection models should include images from different angles, backgrounds, and lighting conditions. For example, a car should be represented both during the day and at night, under direct and oblique lighting, on city streets and country roads. Only then will the model learn to generalize.
It’s important to remember: uniform data leads to weak generalization. If a system learns only from perfectly lit photographs, it will fail when confronted with reality.
Balancing Classes, Avoiding Bias, Ensuring Diversity
Another common problem is imbalance. When one class is represented by thousands of examples, and another by dozens, the model begins to favor the former and ignore the latter. To ensure training stability with correct annotations, it is necessary to:
- maintain a balance between classes,
- include rare and difficult cases,
- account for demographic diversity (in tasks with people).
For example, a 2018 MIT study showed that facial recognition systems perform worse on women and people with dark skin tones precisely because of a lack of examples in the datasets. This is a classic example of bias due to poor data preparation.
Annotation Methods and Formats
Annotations can take various forms, from simple frames to complex 3D masks. The choice of method depends on the task, budget, and time frame.
Compare Bounding Boxes vs. Polygons
Bounding boxes remain the most popular method due to their simplicity. However, they are inaccurate: objects often overlap with the background. In contrast, polygon annotations allow for precise delineation of boundaries. Experiments with the COCO Dataset showed that polygons improve AI model accuracy by 8–10% for tasks involving small objects.
When to Apply Segmentation Masks, Keypoints, or Mixed Approaches
It is needed when:
- segmentation masks are suitable for medical applications (e.g., highlighting tumors in images) and autonomous vehicles;
- keypoints are used in human motion tracking applications, such as sports, AR, and medicine;
- mixed methods are used when both precise boundaries and keypoints are important. An example is animation systems in games or VR.
Dataset Labeling Guidelines
Annotation rules are a common language for the entire team. If they aren’t documented, each annotator will work “in their own way,” and the resulting data will be chaotic.
Dataset Labeling Best Practices
To maintain high quality, annotation consistency checks are essential. Best practices include:
- clear class definitions,
- rules for complex cases (partially occluded objects),
- a consistent annotation style for all images.
Why Annotation Rules Should Be Documented for the Entire Team
Documented guidelines help avoid annotation drift. In large projects, dozens, and sometimes hundreds, of people work on the data. If everyone has a different understanding of “where an object ends,” the resulting dataset will be unsuitable for training.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Mistakes to Avoid in Detection Projects
Annotation errors occur even among experienced teams. Their consequences are noticeable already in the first epochs of training.
Common Annotation Mistakes
The most common errors are:
- incomplete labels (objects forgotten),
- bounding box extending beyond the object,
- different classes for the same object.
Examples of How These Errors Reduce Model Performance
These errors lead to a drop in accuracy and an increase in false positives. For example, a Stanford study showed that incomplete labels in 12% of images reduced AI model accuracy by 9 mAP points.
Choosing the Right Tools
Choosing an annotation tool isn’t just a matter of interface convenience. It directly impacts object detection dataset quality and future training stability with correct annotations. Even if a team adheres to uniform guidelines and conducts regular annotation consistency checks, weak software can ruin their efforts. Some tools are suitable for quick projects with a limited budget, while others are better suited for industrial-strength tasks involving tens of thousands of images and complex annotation scenarios. Therefore, before starting annotation, it’s important to understand the available solutions and how they differ from each other.
Review of Annotation Tools for AI Models
When it comes to the practical side of annotation, specialists rarely limit themselves to manual annotation in graphic editors. Specialized platforms can help reduce the error rate in annotations, mitigate the risk of annotation drift, and improve the overall speed of a team’s work. However, the market is saturated with dozens of solutions, each promising the perfect combination of simplicity and quality. To avoid getting lost, it’s helpful to look at some of the most popular tools and understand what tasks they solve best.
Comparison Table: Open-Source vs Commercial
Before choosing an annotation platform, it’s important to understand the difference between open-source and commercial solutions. Open-source tools are often free and flexible, but require more time for setup and maintenance. Commercial services offer advanced features, built-in QA tools, and technical support, but they come at a cost. Comparing these two approaches will help the team choose the optimal tool based on the project’s scale and budget.
| Feature | Open-source (LabelImg, CVAT) | Commercial (Labelbox, Supervisely) |
| Cost | Free | Subscription / License |
| Support | Community | SLA + Technical Support |
| Scalability | Medium | High |
| Additional Features | Minimal | QA, Analytics, Integrations |
From Annotations to Training
Once all images are labeled, the data moves on to the model training stage. This is where correct annotations truly shines. Any labeling inaccuracy, class imbalance, or labeling inconsistency directly impacts model metrics, reducing its ability to generalize to new data.
How Annotations Influence Model Metrics
Annotation quality directly impacts key metrics: precision, recall, mAP, and other indicators. If bounding boxes or polygons are inaccurate, the model receives inconsistent signals during training. For example, partially occluded objects without correct labeling lead to the algorithm misclassifying them, increasing false positives.
Thus, object detection dataset quality becomes the limiting factor for AI model accuracy, regardless of the neural network’s power or the complexity of the architecture. In practice, even small labeling errors in 5-10% of the data can reduce model accuracy by 8-12%, which is critical for industrial applications.
Improving Model Accuracy with Annotations through QA and Iterative Feedback
To minimize the error rate in annotations, companies implement several levels of quality control:
- peer review — multiple annotators check the same image, identifying discrepancies;
- iterative feedback — the results of the initial model training are analyzed, and the annotations of complex objects are adjusted if necessary;
- automated QA — systems check for empty bounding boxes, class intersections, and object sizes before training.
In one e-commerce project, the use of such practices increased product recognition accuracy from 72% to 89%, and error correction time was halved.
A Step-by-Step Process for How to Train Your Detection Model with Correct Annotations
Below is a practical process that helps build a stable pipeline for training detection models using correct annotations:
- Define the task — what objects need to be recognized and with what accuracy.
- Form classes — define a clear hierarchy of objects, avoiding duplicate categories.
- Create annotation rules — document instructions for the entire team.
- Train the annotation team — explain how to work with edge cases and complex objects.
- Perform initial annotation — annotate a small control sample of data to check consistency.
- Perform QA — apply peer review and automated checks, fix any errors.
- Run model training — use a validated dataset, train the network.
- Analyze results and adjust — evaluate metrics, identify problematic objects, update the annotation if necessary, and repeat.
This approach not only improves AI model accuracy but also ensures training stability with correct annotations, reducing the number of iterations and the effort required to correct errors after training.
Quality Assurance in Annotations
The quality of annotations is a critical factor determining the success of a model’s training. Even if the annotations are done carefully, without systematic checking, errors can accumulate, reducing AI model accuracy and increasing the risk of annotation drift. Quality assurance should combine manual and automated methods.
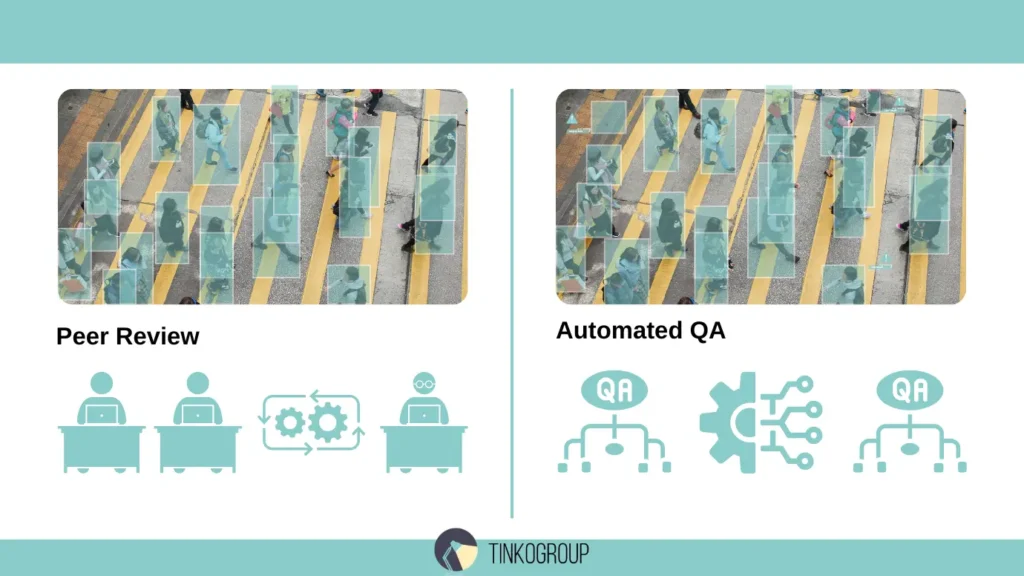
Peer Review and Consensus Methods
One of the most reliable ways to reduce errors is peer review. With this method, each image is annotated by two different experts, and a third checks the results for consistency.
The advantages of this approach:
- inconsistencies and missed objects are identified;
- the annotator’s subjectivity is eliminated — what one annotator considers “insignificant” may be critical to another;
- annotation drift is reduced, especially in large-scale projects with tens of thousands of images.
In practice, in large-scale projects on autonomous vehicle systems, the use of peer review has reduced errors by 15–20%, directly improving the accuracy of object recognition on the road.
Automated QA Checks Before Training
Manual checking is important, but it doesn’t replace automation. Automated QA checks help identify:
- empty or too-small bounding boxes;
- duplicate objects and classes;
- format mismatches or incorrect labels.
These checks are performed before training begins, saving resources and reducing the risk of the model “learning” errors. By combining automated checking with peer review, teams achieve high training stability with correct annotations, increasing the reliability and predictability of results. This becomes especially important in computer vision tasks that rely on precise spatial labeling, such as line annotation for roads, lanes, and boundaries.
Example: in an e-commerce project, automated checking of all images before training identified 7% of problematic labels, which were immediately corrected. After retraining, the AI model accuracy increased from 78% to 91%, and bug fixing iterations became twice as fast.
Conclusion
Correct annotations are the foundation of any detection project. Errors at this stage are the most costly: they reduce accuracy, increase the risk of bias, and delay the product’s time to market.
Good annotation is a combination of diverse data, strict rules, QA, and the right tools. With this approach, training detection models become stable, and the resulting system demonstrates high accuracy.
Tinkogroup helps build a full data management cycle: from annotation rule development to QA and team support. Learn more on the services page.
Why do correct annotations matter more than model architecture in detection tasks?
Because a detection model learns directly from labeled examples, annotation quality defines what the model considers “correct.” Even the most advanced architecture cannot compensate for missing objects, inconsistent classes, or inaccurate boundaries. In practice, errors in just 5–10% of annotations can significantly reduce metrics like precision, recall, and mAP, making data quality the main limiting factor for model performance.
How can teams ensure stable model training with high-quality annotations?
Stable training requires a structured annotation pipeline: clear and documented labeling guidelines, diverse and well-trained annotators, peer review, automated QA checks, and iterative feedback from model results. Combining human review with automated validation before training helps detect errors early and prevents annotation drift as datasets scale.
What are the most common annotation mistakes in object detection datasets?
The most frequent mistakes include incomplete labeling (missing objects), loose or oversized bounding boxes, inconsistent class names for the same object, and unclear handling of occlusions. These errors introduce noise into training data, leading to false positives, poor generalization, and unstable training results, especially in real-world conditions.


