

In the contemporary landscape of high-stakes enterprise operations, the sheer volume of available information has created a paradox: we are drowning in data but starving for actionable intelligence. For Business Intelligence (BI) leads, Data Operations managers, and Enterprise-level catalog managers, the traditional methods of data acquisition are no longer sufficient. The modern competitive edge is found in the discipline of database research — a systematic, highly technical approach to identifying, interrogating, and liberating data from diverse environments.
Introduction: The Strategic Role of Data Discovery
At its core, database research is not merely the act of “searching” for information; it is the architectural foundation of modern business intelligence. In an era where market volatility is the only constant, the ability to pivot based on verified data is what separates industry leaders from those who merely react. When we speak of data discovery, we are referring to the strategic process of mapping the “known unknowns.” This involves identifying which datasets exist, where they are domiciled, and how they can be ingested into a corporate ecosystem to drive revenue.
For an enterprise-level catalog manager, the strategic role of discovery manifests in “Total Information Awareness.” If a competitor launches a new product line, a professional research workflow doesn’t just identify the price. It identifies the Tier-2 suppliers, the patent filings associated with the technology, the shipping manifests from government trade portals, and the technical specifications hidden within non-indexed PDF manuals. This level of granularity is what allows for true market disruption.
Why Database Research is the Foundation of Modern Business Intelligence
Business intelligence systems are only as powerful as the data they consume. If the input is shallow or “noisy,” the resulting analytics will be skewed. Database research serves as the quality control filter at the very start of the BI pipeline. By employing rigorous methodology — such as cross-referencing public records with private commercial feeds — researchers ensure that the “Single Source of Truth” within an organization is actually truthful.
Furthermore, structured research allows for predictive modeling. By analyzing historical trends within niche databases — such as specialized trade registries — BI leads can forecast supply chain bottlenecks or shifts in manufacturing costs before they hit the mainstream retail market. This proactive stance is impossible without a dedicated research engine that goes beyond the surface web.
The Challenge of “Dark Data”: Why Most Valuable Information is Hidden
One of the most significant hurdles in modern data operations is the phenomenon of “Dark Data.” According to research by Gartner, dark data is the information assets organizations collect, process, and store during regular business activities, but generally fail to use for other purposes. However, from an external research perspective, Dark Data also refers to the vast digital “basement” of the internet: non-indexed databases, gated portals, and legacy archives.
The most valuable information is hidden behind these barriers for several reasons:
- Technical obscurity. Many high-value databases use “Deep Web” architectures, meaning their content is only generated in response to a direct query and cannot be crawled by standard search engine bots.
- Access control. Private data providers and government trade portals often require authenticated sessions, specific IP whitelisting, or complex form-fills that prevent bulk indexing.
- Data fragmentation. Critical information for an e-commerce data research project might be split across three different systems: a government certification database, a manufacturer’s dealer-only portal, and an international shipping manifest.
To bridge this gap, professional researchers must act as “data archaeologists,” using advanced technical tools to unearth these records and transform them into structured, machine-readable assets.
The Landscape of Public and Private Databases
To navigate the complex world of data sourcing, one must first categorize the terrain. The landscape is split between the “Public Commons” — information mandated by law to be accessible — and “Private Enclaves” — data collected by commercial entities for profit.
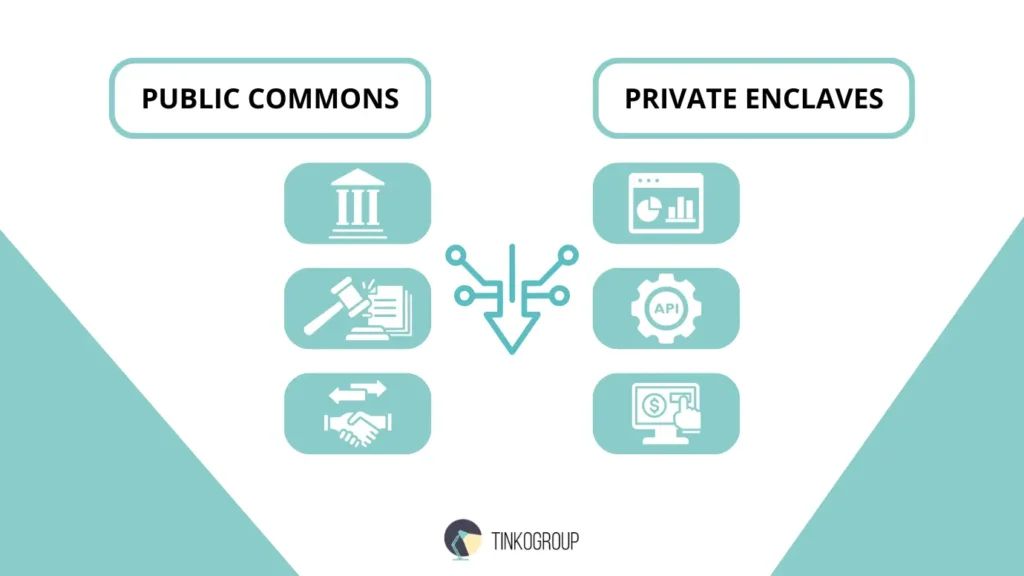
Navigating Government Registries, Trade Portals, and Commercial Providers
The “Public Commons” is perhaps the most underutilized resource in enterprise BI. Public sector data collection involves more than just reading government websites; it requires a deep understanding of international transparency laws and technical data standards (such as XBRL for financial reporting or GTIN for product identification).
Government Registries and Legal Entities
Every legitimate business entity leaves a paper trail. By accessing national registries (such as Companies House in the UK or the SEC EDGAR system in the US), researchers can verify the corporate structure of suppliers and competitors. This is vital for risk management and due diligence. For example, if an e-commerce lead is looking to source a specific category of electronics, they can use these registries to identify the parent companies behind “white-label” brands, allowing them to go straight to the source and bypass middlemen.
International Trade Portals and Customs Data
Trade portals are the “secret weapon” of internet research for product data. Systems like the UN Comtrade Database or private aggregators of Bill of Lading (BoL) data provide a real-time view of global commerce. By analyzing these databases, a researcher can see exactly how many units of a specific SKU are being shipped from a factory in Shenzhen to a competitor’s warehouse in Rotterdam. This level of visibility is the ultimate form of competitive intelligence.
Commercial Data Providers and API Aggregators
While public data is often free, it is frequently “messy” and delayed. Commercial providers — such as Bloomberg for financials, Nielsen for retail trends, or specialized aggregators for data normalization services — provide cleaned, high-velocity data. The challenge here is integration. A professional research workflow must define how to blend these expensive private feeds with “scraped” public data to create a comprehensive market view without blowing the budget.
The Difference Between Surface Web Search and Deep Database Exploration
To the uninitiated, “searching the web” means using a search engine. To a Data Operations manager, this is only the tip of the iceberg.
- The surface web. This consists of static pages and content that search engines like Google can index. It is useful for general sentiment and high-level pricing but lacks technical depth.
- The deep web. This is where the real database research happens. It includes any content that is hidden behind a search form. If you want to find the specific torque requirements for an industrial drill SKU, that data likely lives in a manufacturer’s SQL database, served only when a specific part number is entered. It is not “crawlable” in the traditional sense.
Deep exploration requires automated data extraction tools that can mimic human interaction: filling out forms, selecting items from dropdown menus, and handling “infinite scroll” or complex AJAX-based pagination. Without these techniques, your research is limited to what the world wants you to see, rather than the raw truth of what exists.
Methodology of Professional Database Research
To transition from ad-hoc data gathering to an industrial-grade operation, a team must implement a rigorous, repeatable methodology. This is not about “finding information”; it is about building a data pipeline that functions with the precision of a manufacturing assembly line.
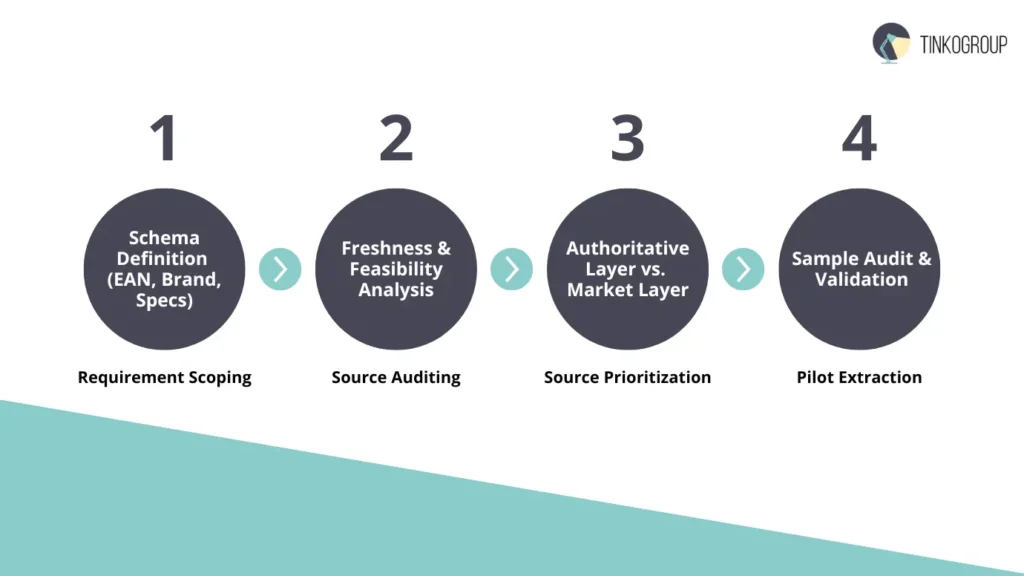
Establishing a Research Workflow: From Source Identification to Data Extraction
A professional research workflow is a multi-stage process designed to minimize “noise” and maximize “signal.” For a Data Operations manager, the workflow follows a specific lifecycle:
- Requirement scoping and schema definition. Before a single query is run, the team must define the target data schema. What attributes are required? (e.g., EAN, Brand, Weight, Wattage, Material). Without a predefined schema, the research becomes unfocused and leads to “data swamp” conditions.
- Source auditing and feasibility analysis. Not all sources are created equal. Researchers evaluate potential targets based on Data Freshness, Granularity, and Accessibility. A feasibility study determines if a source requires a custom API wrapper or if it can be accessed via headless browser automation.
- Source prioritization. Sources are ranked. A manufacturer’s direct Technical Data Sheet (TDS) is always prioritized over a third-party retail listing. This ranking is codified into the extraction logic to ensure that “Tier 1” data always overwrites “Tier 2” data in the event of a conflict.
- Pilot extraction and validation. A “sample set” (typically 1-2% of the total target volume) is extracted and manually audited. This identifies edge cases — such as non-standard units of measure or unexpected character encoding (UTF-8 vs. ISO-8859-1) — before a full-scale run is initiated.
How to Build a Source Hierarchy for E-commerce Data Research
In the realm of e-commerce data research, accuracy is the ultimate KPI. If a database lists a laptop’s RAM as 8GB when the manufacturer’s spec sheet says 16GB, the business suffers financial loss through returns and brand erosion.
To ensure maximum data accuracy, we implement a source hierarchy matrix:
- The authoritative layer (The “Gold Standard”). This includes the original manufacturer’s internal databases, PDM (Product Data Management) exports, and official whitepapers. These are the only sources trusted for technical specifications.
- The regulatory layer. Government certification databases (like the FCC for electronics or EPREL for energy efficiency in Europe) serve as a secondary check. These are legally mandated records and are highly reliable for verifying compliance data.
- The distribution layer. Wholesale portals and B2B distributor feeds. These are excellent for real-time stock levels and logistics data (weight/dimensions), but can sometimes lag behind the manufacturer for technical updates.
- The market layer. Aggregators and major competitors. These are used only for price-scraping and “gap analysis” — identifying which products are currently trending that your catalog might be missing.
By strictly adhering to this hierarchy, a research team ensures that the database research output is not just voluminous but definitive.
Overcoming Technical Barriers in Data Sourcing
The deeper the value of the data, the higher the walls built around it. Modern data sourcing is a constant “arms race” between researchers and the security measures of high-value portals.
Navigating Legacy Systems: Outdated UIs and Lack of APIs
A common frustration in public sector data collection is the reliance on “Legacy Infrastructure.” Many government and trade registries run on systems designed in the late 1990s.
- The “Viewstate” problem. Old ASP.NET websites often rely on massive hidden “Viewstate” parameters. Standard scrapers fail here because they don’t maintain the complex session state required to navigate through pages.
- Complex pagination and AJAX. Many portals use non-restful URLs. This means the URL in the browser doesn’t change when you go to page 2, 3, or 4. Extracting data from these requires “Session Persistence” and event-driven triggers within a headless browser to “click” and “wait” for the DOM to update.
- Lack of APIs. When there is no API, the browser is the API. We build “Wrappers” around the front-end, treating the HTML elements as data fields.
Technical Workarounds for Geo-blocking, Rate Limits, and CAPTCHAs
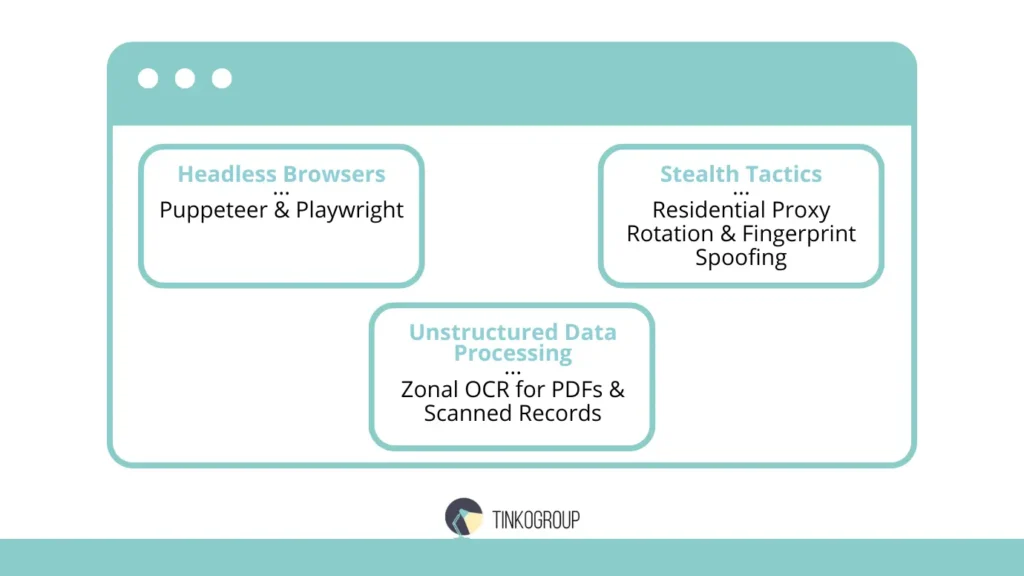
Sophisticated targets employ “Anti-Bot” technologies (like Akamai, DataDome, or Cloudflare). To maintain a successful automated data extraction flow, a research specialist must utilize several advanced workarounds:
- Residential proxy rotation. Data center IPs are easily flagged and banned. Professional research requires a pool of millions of rotating residential IP addresses. This makes the extraction requests appear to come from legitimate home users in specific geographic regions, bypassing geo-blocks.
- User-agent and fingerprint spoofing. Modern security systems check the “Browser Fingerprint” — including screen resolution, installed fonts, and GPU drivers. We use specialized libraries to randomize these fingerprints for every request, preventing “Pattern Recognition” bans.
- Headless browser stealth. Tools like puppeteer-extra-plugin-stealth are used to hide the fact that the browser is being controlled by a script. This involves patching variables like navigator.webdriver, which sites check to detect bots.
- Handling advanced CAPTCHAs. When a site triggers a CAPTCHA (hCaptcha, reCAPTCHA v3), we integrate automated solvers that use AI to identify patterns or solve the challenge in real-time, ensuring the extraction pipeline remains uninterrupted.
Leveraging Deep Web Research for SKU to Find Hidden Specifications
Standard retail sites are often “sanitized” for the general consumer. They lack the technical “nitty-gritty” that enterprise-level catalog managers require.
By conducting deep web research for SKU, we bypass the retail interface entirely:
- Hidden directory crawling. Often, manufacturers store high-resolution technical diagrams or assembly instructions in sub-directories that are not linked on the main site but are accessible via direct URL manipulation.
- Metadata extraction from media files. Sometimes, the most accurate “last updated” date or original author of a specification is hidden in the EXIF data of an image or the XMP metadata of a PDF file.
- Foreign language cross-referencing. A product might have minimal data on its US English site, but exhaustive technical details on its German (DE) or Japanese (JP) regional site. A professional researcher knows how to crawl international variations of the same database to find the “missing link” of information.
Automation in Database Extraction
In the early days of e-commerce, teams of manual data entry clerks would spend months copy-pasting specifications from manufacturer catalogs into Excel. Today, that approach is not just slow — it is a competitive liability. To manage a modern enterprise catalog, automated data extraction is the only viable path.
Transitioning from Manual Search to Automated Data Extraction
The shift to automation is a strategic leap. It requires moving from a “Search” mindset to a “Crawl” mindset. Manual searching is linear; automation is exponential. When an organization automates its database research, it stops looking for individual items and starts mapping entire digital ecosystems.
The transition involves three core shifts:
- From ad-hoc to scheduled. Automation allows for “Delta Scraping” — only extracting data that has changed since the last run. This ensures the database is always “fresh.”
- From browsing to interrogating. Automation tools don’t just “see” the page; they interrogate the underlying API calls and JSON structures that the website uses to populate its front end.
- From human error to algorithmic precision. A script does not get tired. It will extract 100,000 SKUs with the same precision as the first one, ensuring that “Material” always goes into the “Material” column.
The Role of Headless Browsers and Custom Scrapers
Modern web architecture (Single Page Applications or SPAs) has made simple “curl” or “wget” requests obsolete. Most data today is rendered dynamically via JavaScript. This is where headless browsers like Puppeteer, Playwright, and Selenium become essential for internet research for product data.
- DOM interaction. Custom scrapers use these browsers to simulate a human user. They can click “Load More” buttons, wait for “Spinners” to disappear, and hover over elements to trigger “Tooltips” that contain hidden specifications.
- State management. High-value databases often require complex multi-step navigation (e.g., Select Region -> Select Language -> Enter Catalog ID). Headless browsers maintain the session cookies and local storage state required to reach these deep pages.
- Parallelization. By running hundreds of headless browser instances in a “Cloud Cluster,” a research team can compress six months of manual research into a single weekend.
Handling Unstructured Data: Using OCR for Scanned Documents and PDF Records
A persistent myth in data science is that all data is “digital.” In reality, many legacy manufacturers and government agencies still distribute critical information in “Static” formats: PDFs, TIFF images, or even scanned faxes of technical drawings.
To capture this, the automation pipeline must include an OCR (Optical Character Recognition) layer.
- Zonal OCR. For standardized documents like invoices or spec sheets, we define specific “Zones” where data (like SKU or Price) is always located.
- Computer vision (CV). Advanced scrapers use AI to identify tables within a PDF, even if the table has no borders. It “sees” the alignment of text and reconstructs the grid into a CSV or JSON format.
- Handwriting recognition. In some specialized public collection sector data projects, researchers must even process handwritten ledger entries from old trade registries, requiring sophisticated neural networks to convert script into data.
Data Normalization and Quality Control
Extraction is only the beginning. Raw data is often “dirty” — it contains duplicates, varying units of measure, and inconsistent naming conventions. Without cleaning, this data is toxic to a Business Intelligence system.
Why Raw Data Requires Cleaning: Addressing Duplicates and Errors
When you pull data from five different sources for the same SKU, you will inevitably find:
- Inconsistencies. Source A says “Color: Midnight Blue,” Source B says “Color: Blue,” and Source C says “Color: M-Blue.”
- Formatting errors. One source uses “kg,” another uses “lb,” and a third uses “grams.”
- Encoding artifacts. Symbols like “ø” or “©” might turn into “” if the character encoding is not handled correctly.
Failing to address these issues leads to “Data Fragmentation,” where a single product appears three times in your catalog under different names.
The Importance of Data Normalization Services
Professional data normalization services act as a “refinery.” They take the crude extracted data and put it through several algorithmic stages:
- Standardization. Mapping all variations of an attribute to a single “Master Value” (e.g., “M-Blue” → “Midnight Blue”).
- Unit conversion. Automatically converting all weights, dimensions, and electrical specs into a single global standard (e.g., Metric or Imperial).
- Deduplication (Fuzzy Matching). Using “Levenshtein Distance” algorithms to identify when two records are actually the same product, even if the titles are slightly different.
- Enrichment. Filling in “Gaps.” If Source A has the weight but lacks the EAN, and Source B has the EAN but lacks the weight, the normalization process “merges” them into a single, perfect record.
Bridging the Gap: PIM and PDM Integration
The final destination for this research is the Product Information Management (PIM) or Product Data Management (PDM) system.
- Data liquidity. The goal is to move from “Research” to “Production” without manual intervention.
- API mapping. The normalized data is mapped to the specific fields of the enterprise PIM (such as Akeneo, Riversand, or Salsify).
- Validation rules. Before ingestion, the data passes through “Gatekeeper” rules. If a SKU is missing a “Main Image” or a “Mandatory Price,” it is flagged for human review, ensuring only 100% complete data reaches the live storefront.
Expanding the Scope: Competitive and Visual Intelligence
Modern database research has evolved. It is no longer enough to scrape prices and dimensions. In the visually-driven world of e-commerce, the “Image Asset” is as much a data point as the SKU itself. Strategic data operations now incorporate visual signals to understand market trends and competitor positioning.

Integrating Competitor Image Research and Market Research for E-commerce Visuals
A product’s visual presentation can be the difference between a high conversion rate and a high bounce rate. To stay ahead, enterprise catalog managers must treat images as structured data.
- Visual gap analysis. By performing competitor image research, a team can identify which brands are moving toward 3D renders, 360-degree spins, or augmented reality (AR) files. If your database shows that 80% of market leaders in “High-End Audio” use lifestyle photography rather than white-background studio shots, your research informs your creative budget.
- Image metadata extraction. Professional scrapers don’t just download images; they extract the metadata (EXIF). This can reveal when a competitor’s photo was taken, what camera was used, and if the image was processed with specific software — giving clues about their creative pipeline.
- Automated image tagging. Using Computer Vision (CV), we can automatically tag thousands of images with attributes like “Color,” “Angle,” “Room Type,” or “Presence of Human Model.” This turns a folder of 100,000 files into a searchable database of market research for e-commerce visuals.
Case Study: Building a 50k+ SKU Catalog Using Multi-Source Database Research
Let’s look at a real-world execution for a Tier-1 Consumer Electronics retailer expanding into a new European territory.
The Challenge: The client needed a fully localized catalog of 50,000 SKUs (Laptops, Home Appliances, Mobile) in 45 days. They had no existing database and only a list of EANs (European Article Numbers).
The Execution:
- Phase 1. Deep Web Discovery: We used the EAN list to query 12 different government certification databases and 30+ manufacturer-dealer portals. This provided the “Raw Technical DNA” for each SKU.
- Phase 2. Automated Extraction: Using a cluster of 500 headless browsers, we scraped technical manuals (PDFs) from the manufacturers’ support sites.
- Phase 3. OCR and Normalization: We ran an OCR pipeline to extract specifications from those PDFs and used our data normalization services to convert all measurements to local metric standards.
- Phase 4. Visual Intelligence: We performed competitor image research to find the highest-resolution assets available, ensuring the client’s site looked premium from Day 1.
The Result: The catalog was delivered in 38 days — 7 days ahead of schedule. The data accuracy was audited at 99.8%, and the client saw a 14% higher conversion rate compared to their previous manual-entry pilot project.
Conclusion: The ROI of Structured Research
The “Return on Investment” for professional database research is not just about having more data — it is about Data Liquidity. It is the ability to turn a market opportunity into a live, selling product in hours rather than weeks.
Efficiency Gains: Speed-to-Market vs. Manual Data Entry
In a manual environment, an experienced content manager can accurately create 15 to 20 complex SKUs per day. For a 50,000-SKU catalog, that is nearly 2,500 man-days.
With automated data extraction and professional research:
- Speed. The same 50,000 SKUs can be “discovered” and “normalized” in under 14 days.
- Cost. The cost-per-SKU drops by approximately 75–85% when factoring in the reduction of human oversight and error-correction.
- Quality. Automated validation ensures that no SKU is missing a “Required Field,” preventing costly “Broken Links” on the live storefront.
Navigating the complexities of database research is a technical burden that most internal BI teams aren’t equipped to handle at scale. Tinkogroup’s research specialists act as your scalable engine. We provide the infrastructure, the proxy networks, the custom scrapers, and the normalization logic to deliver verified, structured datasets directly into your product data management systems.
Whether you are launching a new marketplace, auditing your competitors, or expanding into international territories, don’t let “Dark Data” be your blind spot. Let us illuminate your path to market dominance with data that is as accurate as it is exhaustive.
What is the difference between the surface web and the deep web in database research?
The surface web is what search engines index — general pricing, basic product pages, public news. The deep web is everything behind a search form or login: manufacturer spec databases, dealer portals, government registries. For enterprise catalog work, the deep web is where accurate, granular data actually lives.
Why can’t a business rely on a single data source for its product catalog?
Because no single source is complete. Manufacturer portals have precise specs but no stock data. Distributor feeds have logistics info but lag on updates. The solution is a source hierarchy — layering each source by authority, so the final record pulls the best attribute from the most reliable place.
How does data normalization affect catalog quality?
Raw data from multiple sources is always inconsistent — different units, different color names, duplicate records. Normalization standardizes everything, merges attribute gaps across sources, and removes duplicates. The result is a catalog that is accurate, searchable, and ready to sell — not one that generates returns and support tickets.


