

In every machine learning project, regardless of the domain — autonomous driving, medical imaging, retail analytics, or NLP — there is a fundamental conflict between speed, cost, and accuracy. This is not a marketing triad. It is an operational reality.
Any team that scales data will sooner or later face a choice between AI-assisted data labeling and fully manual annotation. At first glance, the answer seems obvious: if a model can pre-label data, why pay people to do what an algorithm can do faster? But practice shows that this question is rarely resolved in a linear fashion. In professional circles, the debate over manual vs automated labeling has been going on for years. The problem is that both sides are right — but under different conditions.
This article approaches the issue not as an ideological choice, but as an economic and engineering problem.
Before moving on to hybrid models, it is necessary to clearly define the poles.
In a fully manual annotation model, annotators create markup from scratch. There is no model pre-labeling and no preliminary algorithmic hypotheses. Every bounding box, every segmentation mask, and every entity in the text is determined by a human.
This is a labor-intensive process. But it is precisely this process that creates the benchmark ground truth data — the data that becomes the reference point for evaluating models.
The manual approach has historically been considered the gold standard for annotation accuracy. In an ideal configuration with multi-level QA and high inter-annotator agreement, it is possible to achieve 99.5–99.9% accuracy. However, high accuracy comes at a price. And that price is not only expressed in direct labor costs.
The AI-assisted labeling model assumes that the algorithm first makes an assumption. Annotators then either confirm the result or correct it.
This is a type of Human-in-the-loop (HITL), but with an emphasis on preliminary automation.
This is where AI data labeling, often referred to as automated data labeling, comes into play. But in reality, automation is never completely autonomous. Even with a high baseline accuracy model, human control remains mandatory. And this is where the real engineering debate begins.
The False Binary: Why the Debate Is Misleading
In public discussions, the debate is often simplified:
- Manual — expensive, but high quality.
- AI-assisted — fast and cheap.
In practice, this is incorrect. Let’s look at three common misconceptions.

Misconception #1: AI-Assisted is always cheaper. Formally, yes. The cost per annotation is lower. But if the baseline model is wrong in 20% of cases, and the annotator spends time correcting almost every fifth annotation, the savings drop sharply. In addition, the following must be taken into account:
- the cost of training the initial model;
- computing resources;
- pipeline integration;
- retraining;
- drift monitoring.
If these elements are added to the cost of data labeling formula, the picture changes.
Misconception #2: Manual guarantees maximum quality. Manual processes also have systemic errors:
- annotator fatigue;
- interpretation discrepancies;
- context effect;
- variability of subjective assessment.
Without a strict QA system, manual labeling can have noise at the level of 2–5%. And this already affects the model.
Misconception #3: Human-in-the-loop is a universal solution. In theory, human-in-the-loop combines the best of both worlds. But in practice, HITL can lead to an “automation bias” effect: annotators begin to trust the machine more than their own analysis. This reduces annotation accuracy in complex cases.
The Economic Model: Beyond Hourly Rates
For the analysis to be objective, we need to move on to the formula.
Let:
- Ch — cost per hour of an annotator;
- Tm — average time for manual annotation of a unit;
- Ta — average time for AI annotation verification;
- E — model error rate;
- Ci — cost of AI infrastructure;
- N — data volume;
Manual model:
Total Costmanual = Ch× Tm× N
AI-Assisted Model:
Total CostAI = (Ch× Ta× N)+(Ch×Tm× E× N) + Ci
Where the second part reflects the time needed to correct errors.
Now a critical parameter appears — E (model error rate).
If E > 25–30%, AI-assisted loses its economic advantage.
If E < 10%, the advantage becomes significant.
But this is only the direct cost.
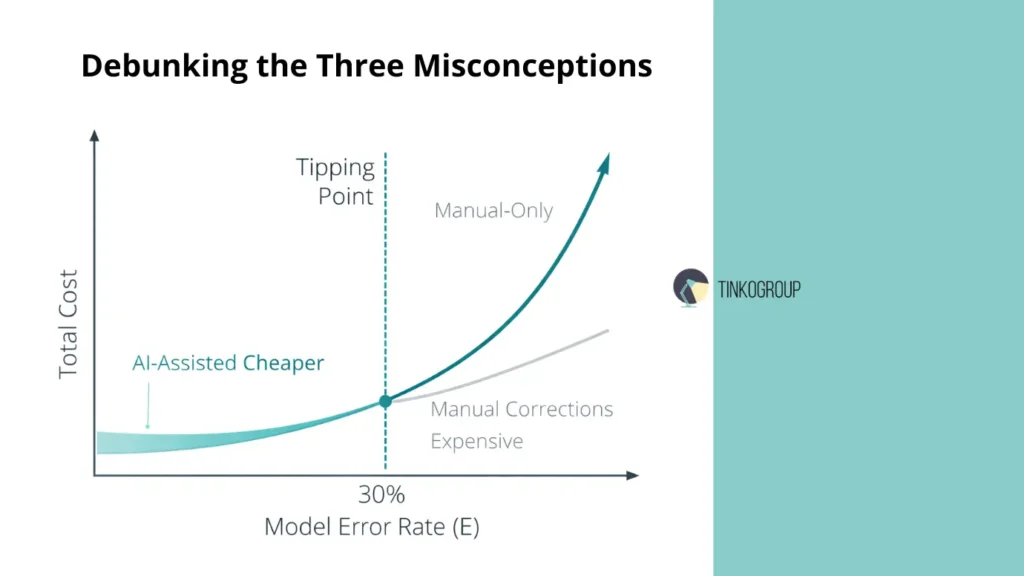
Hidden Cost: Error Propagation
Errors in labeling affect:
- precision;
- recall;
- F1-score;
- downstream business metrics.
Low-quality ground truth data can lead to model degradation in production. The cost of such degradation often exceeds the savings on labeling. This is rarely taken into account in data labeling efficiency calculations.
Data Labeling Efficiency Is Not Speed
The industry often confuses speed with efficiency. Data labeling efficiency is not the number of images processed per day.
It is:
Quality × Volume/ Total Cost
And here a delicate balance arises.
- Manual increases Quality.
- AI-assisted increases Volume.
The question is: factor is more important for a specific project?
Domain Sensitivity: Why Context Matters
In autonomous driving, the acceptable error margin for a bounding box can be 2–3 pixels. In medical diagnostics, an error in tumor segmentation can change the clinical decision. In retail CV, an error in recognizing a product on a shelf most often has only an economic effect. Therefore, the choice between AI-assisted data labeling and manual labeling cannot be universal.
The Operational Reality
Companies providing data annotation services have long moved from ideological debates to hybrid configurations. But the problem lies elsewhere: most customers do not conduct a preliminary data audit.
The decision is often made based on the principle: “Our competitors use AI, so we need it too.” This is a strategic mistake.
Emerging Insight: The Role of Baseline Model Maturity
If a project does not have a mature baseline model, AI-assisted labeling does not speed up the process. First, high-quality ground truth data must be created manually. Only after sufficient accuracy has been achieved (usually 85–90% baseline) does automation begin to have an effect. It is at this stage that the debate between manual and automated labeling becomes relevant.
A Critical Observation
The following is often observed in engineering practice:
- In the early stages of a project, manual labeling is perceived as slow and expensive.
- Six months after the model’s release, it becomes clear that an error in the initial labeling cost the company multiple retraining sessions, release delays, and additional expenses.
Thus, the cost of data labeling cannot be considered outside the model’s life cycle.
Manual-Only Annotation: The Gold Standard for Precision
In an industry where the debate between manual and automated labeling often boils down to a question of cost optimization, manual labeling remains the foundation of the entire model training system. Despite the development of AI-assisted data labeling, it is manual data annotation that continues to perform a critical function: creating the most accurate and controllable database possible.
This is not a romanticization of manual labor. It is operational reality. No serious ML team builds a pipeline without a stage where a human starts from scratch.
How It Works: Annotators Start with a Blank Screen
In the Manual-Only model, annotators receive raw data. There is no model pre-labeling. There are no preliminary frameworks. No algorithmic hypothesis.
Every bounding box, every segmentation polygon, every entity in the text is created manually.
The process usually includes:
- Initial labeling by a specialist.
- Second level of verification.
- Audit of complex cases.
- Inter-annotator agreement control.
- Final validation to form ground truth data.
This architecture slows down the process but ensures maximum annotation accuracy. It is important to emphasize that accuracy here is achieved not only through human vision. It is achieved through a procedure — a strict quality control protocol.
Best for: Edge Cases

The manual approach is especially critical when working with edge cases — situations that the model has not encountered before.
An example from computer vision:
a person in a dinosaur costume.
For the algorithm, this could be:
- a person;
- an animal;
- an undefined object.
For the annotator, this is a specific scenario that needs to be interpreted according to the instructions.
In autonomous driving projects, such cases may include:
- partially hidden pedestrians;
- non-standard road markings;
- objects in extreme lighting conditions.
If these cases are not correctly marked manually, the model will not learn to recognize them. AI cannot correctly mark what it has not yet been taught. And here, manual data annotation becomes not an alternative, but a necessity.
Best for: Gold Sets (Ground Truth)
Creating ground truth data is one of the most underrated stages of a project.
Ground sets are used:
- to validate models;
- to evaluate precision/recall;
- to calibrate hyperparameters;
- for A/B testing of model versions.
If this dataset contains noise, the entire evaluation system becomes distorted.
Therefore, most mature ML teams create evaluation datasets exclusively by hand, without using AI-assisted labeling. Cost-cutting is unacceptable here. A 1% error in ground truth can lead to systematic retraining or misinterpretation of metrics.
Why Precision Still Matters
Discussions about data labeling efficiency often focus on volume.
But for a number of industries, accuracy is more important than speed:
- medical imaging;
- insurance cases;
- legal tech;
- industrial quality control.
In these areas, the cost of an error significantly exceeds the cost of data labeling.
If a model misses a defect in manufacturing or incorrectly segments a tumor, the consequences are not measured in dollars per image.
Pros of Manual-Only Annotation
- maximum annotation accuracy.
- controllable process.
- minimization of systematic bias.
- best option for creating a reference dataset.
The manual approach also allows for more accurate analysis of inter-annotator disagreement and improvement of instructions.
Cons: Slow, Expensive — and Operationally Heavy
The disadvantages are obvious.
- high cost of data labeling;
- limited scalability;
- long time-to-market;
- dependence on human resources.
The average time for manual labeling of a complex image can be 5–10 times higher than the verification time for AI data labeling.
With a volume of 500,000 images, this translates into months of work.
The Critical Tension
And yet, despite the development of automated data labeling, manual labeling is not disappearing. Moreover, it often becomes a mandatory phase before the implementation of a human-in-the-loop system. The paradox is that automation is impossible without initial manual labor. A model cannot perform AI-assisted data labeling if it does not have a high-quality training corpus created manually. That is why the Manual-Only approach remains not an outdated practice, but the foundation of the entire data annotation services ecosystem.
What is AI-Assisted Data Labeling?
If the Manual-Only model starts with a blank screen, AI-assisted data labeling starts with a hypothesis. The algorithm is the first to “look” at the data and suggest labeling. The human comes second.

This is a fundamental difference in the logic of the process.
Instead of creating annotations from scratch, Model pre-labeling is used, after which the verification mode is activated.
This is where the architecture that engineers call model-in-the-loop comes in — a special case of the broader concept of Human-in-the-loop.
How It Works: Model-in-the-Loop Workflow
The operational process looks like this:
- The model automatically labels incoming data.
- The annotator opens the already labeled object.
- They either click “Approve” or make corrections — “Fix.”
- The corrections are saved and can be used to retrain the model.
In an ideal configuration, the system is built as a closed loop: AI → Human verification → Correction → Retraining → Improved AI labeling.
It is this cycle that allows you to gradually increase data labeling efficiency without losing control over quality.
Why AI-Assisted Data Labeling works faster
Key savings are achieved by reducing the time spent per data unit.
While manual data annotation takes 60–90 seconds per image, the AI approach can take 10–20 seconds, provided that the model already demonstrates high baseline accuracy.
In large-scale projects, this has a multiplier effect. For arrays of 100,000–1,000,000 images, the difference can amount to months of work. This is why AI data labeling is often referred to as a driver of scaling.
Best for: Standard, High-Frequency Objects
The AI approach is particularly effective where:
- objects are repetitive;
- visual patterns are stable;
- the classic computer model has already reached maturity.
Examples:
- cars;
- pedestrians;
- road signs;
- standard consumer goods;
- basic NER entities in text.
In such scenarios, automated data labeling can provide 85–95% preliminary accuracy. And with this baseline level, the economic model begins to favor automation.
Pros: Speed and Cost Efficiency
The main advantage is speed.
A mature AI-assisted model can be:
- 5–10 times faster;
- significantly cheaper per unit;
- easier to scale;
- more predictable in terms of SLA.
From an operational management perspective, this means:
- accelerated time-to-market;
- the ability to iterate quickly.
- reduced workload for data annotation services teams.
With large datasets, the difference in the cost of data labeling becomes strategically significant.
Cons: The Automation Bias Problem
However, the AI approach has a systemic vulnerability — the so-called automation bias. When annotators see an already marked object, they are psychologically inclined to trust the algorithm. Instead of active verification, passive confirmation begins. This reduces annotation accuracy precisely in those cases where attention is required. In practice, this manifests itself as follows:
- complex objects are confirmed without detailed analysis;
- minor errors are ignored;
- partially hidden objects remain uncorrected.
The paradox is that in some scenarios, AI-assisted labeling can worsen quality compared to full manual labeling — especially if the model’s baseline accuracy is below 80–85%.
When AI-Assisted becomes ineffective
If the model is wrong in 25–30% of cases, the annotator has to:
- delete incorrect bounding boxes;
- redraw polygons;
- correct classes.
In such a situation, the verification time approaches the time of manual labeling. The economic advantage disappears. Moreover, infrastructure costs for AI support are added. And then the debate about manual vs automated labeling becomes not theoretical, but financial.
The Structural Insight
AI-assisted data labeling is not a replacement for humans. It is a tool for acceleration in mature models and repetitive patterns. Without high-quality ground truth data created manually, automation is impossible. Without quality control, human-in-the-loop becomes an illusion of efficiency. That is why in mature projects, the AI approach is used not as an alternative to manual labeling, but as a second phase after the creation of a reference corpus.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Comparing the ROI (Return on Investment)
Comparing the ROI of manual and AI-supported labeling cannot be reduced to an hourly rate. The question is not how much an annotator costs per hour, but how much a correct training signal for the model costs.
In a fully manual labeling model, the costs are transparent: the higher the hourly rate, the higher the total budget. However, the high price is offset by stable accuracy, especially in complex and rare scenarios. Errors are detected at the annotation stage, not in production. This reduces the risk of costly retraining and metric degradation.
In AI-assisted data labeling, the cost per unit is usually lower. Thanks to preliminary automatic labeling, one specialist can process a significantly larger amount of data. For large arrays, this results in multiple acceleration and a more predictable budget. This is where automation wins in terms of speed and scale.
However, savings are only possible if the model has a sufficiently high baseline accuracy. If the error rate is significant, the time spent on corrections begins to approach that of manual labeling, and the advantage diminishes. Furthermore, infrastructure costs, model support, and possible retraining must be taken into account.
In terms of quality, the manual approach often wins out when dealing with complex data: non-standard objects, rare classes, ambiguous scenarios. AI support demonstrates better results on typical, repetitive objects where the model is already trained and stable.
As a result, the key indicator is not speed or price per unit, but data labeling efficiency as a ratio of accuracy, volume, and total cost. Where maximum accuracy is critical, manual remains more justified. Where volume and speed are more important than absolute precision, AI-assisted provides the best ROI.
The Winner: Human-in-the-Loop (HITL)
While early market development centered on the debate between manual and automated labeling, today’s industry is gradually moving away from this binary logic. Practice has shown that extremes only work in narrow scenarios. In real-world projects, hybrid approaches prevail.
The Human-in-the-loop model has become the de facto standard for mature ML teams that seek to simultaneously control annotation accuracy and increase data labeling efficiency. This is not a compromise for the sake of compromise. It is a structural evolution of the process.
In a hybrid configuration, AI does not replace humans, but redistributes the workload. The machine performs the mechanical, scalable part of the work. Humans remain the bearers of critical thinking and final control.
The workflow is as follows.
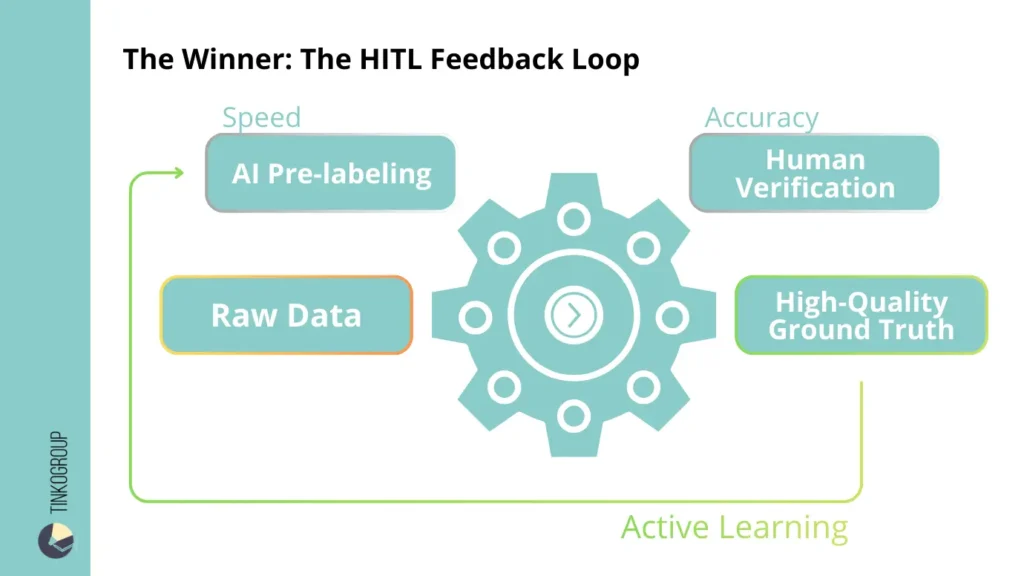
First, the model performs model pre-labeling — it automatically labels data, creates bounding boxes, segmentation masks, or text entities. This is the stage where AI-assisted data labeling provides the maximum speed increase.
Next, the team of annotators gets involved. Their task is not to create labels from scratch, but to check, correct, and reject inaccurate hypotheses. This is where quality control comes into play. Human verification reduces the risk of systematic errors and prevents the spread of bias.
After corrections are made, the data is returned to the model for retraining. This stage of active learning allows you to gradually reduce the error rate and increase the efficiency of automation. In this way, the system becomes self-reinforcing: each corrected error improves future labeling cycles.
It is important to emphasize that in a mature AI data labeling pipeline, people do not disappear from the process. They change roles. Instead of mass manual labeling, intelligent control and analytical verification appear.
It is this approach that allows you to simultaneously manage the cost of data labeling and maintain a high level of quality. Without human validation, automation can scale up errors. Without automation, the manual process becomes economically inefficient at large volumes.
Many data annotation service providers are transitioning to this model. In particular, Tinkogroup builds processes around a hybrid model: AI performs voluminous preliminary work, a team of annotators performs verification and complex manual re-labeling, and corrections are integrated into the active learning cycle.
This approach allows for a balance between speed, cost, and accuracy — without extremes and without the illusion of complete automation.
When to Choose Which? (Checklist)
The decision between manual labeling and AI-assisted data labeling should not be made intuitively or based on trends. It should be based on the maturity of the model, the nature of the data, and the acceptable cost of error. Below is a practical guide for making this decision.
Choose Manual if:
- The project is starting from scratch and there is no high-quality ground truth data.
- The base model has not yet been trained or demonstrates low accuracy.
- The data is sensitive: medicine, finance, legal tech, industrial safety.
- The required annotation accuracy is close to 99.9% and the cost of error is critical.
- The dataset contains a large number of edge cases or rare classes.
- A reference validation set needs to be created for further model evaluation.
In these scenarios, manual data annotation provides maximum control. Although the cost of data labeling will be higher, the risk of downstream errors is reduced.
Choose AI-Assisted if:
- You have large amounts of data (100,000+ images or documents).
- The model already demonstrates stable baseline accuracy.
- Objects are standardized and frequently repeated.
- You need to quickly iterate and test hypotheses.
- High data labeling efficiency with a controlled level of quality is important.
In such conditions, AI-assisted labeling allows you to scale the process without a linear increase in budget. With a correctly structured human-in-the-loop pipeline, automation increases speed without compromising quality.
Conclusion
The choice between manual labeling and AI-assisted data labeling should not be based on trends or superficial cost savings. The key factor is not the technology, but the complexity of the data, the maturity of the model, and the acceptable cost of error.
If the project is in its early stages and requires the creation of flawless ground truth data, accuracy becomes the priority. If the model is already trained and the volume of data is growing exponentially, automation helps to increase data labeling efficiency and speed up iterations.
In reality, most mature ML projects end up with a hybrid configuration: manual expertise forms the foundation, and AI scales the process. The question is not what is “better,” but what is rational at a particular stage of the model’s life cycle.
Whether you need 100% manual precision or the speed of AI-assisted data labeling, Tinkogroup provides professional teams and structured processes for both scenarios. You can learn more about our approaches and collaboration formats on the data labeling services page.
What is the main difference between manual and AI-assisted data labeling?
Manual labeling involves annotators creating every tag, bounding box, or mask from scratch on a “blank screen.” In contrast, AI-assisted data labeling uses a pre-trained model to generate initial hypotheses (pre-labels), which human annotators then verify or correct. While manual labeling is the gold standard for precision, AI-assisted methods focus on scaling and speed.
When should I choose manual annotation over AI-assisted?
You should prioritize manual annotation if you are in the early stages of a project (creating a “Gold Set” or Ground Truth), working with highly sensitive data (medical, legal), or dealing with complex “edge cases” that automated models cannot yet recognize. Precision is the priority here.
What is Human-in-the-Loop (HITL) and why is it considered the best strategy?
Human-in-the-Loop (HITL) is a hybrid model that combines the speed of AI with human critical thinking. It creates a feedback loop: AI pre-labels data, humans verify it, and the corrected data is fed back to retrain the model. This approach balances cost-efficiency with high-level accuracy, making it the most scalable solution for mature ML projects.


