

There’s an old adage in the AI world: “How smart the AI is depends on how much human work went into it.” Teams rush to deploy AI models and are obsessed over accuracy rates, turnaround times, and pricing when choosing a vendor. But they often ignore one important question: Who is doing this work, and where are they located?
That oversight can be costly. AI systems are increasingly making high-stakes decisions in medicine, FinTech, legal discovery, and autonomous driving. The people who train these models have a profound influence on how the systems behave. Yet clients rarely consider where these annotators are based.
Annotator location transparency isn’t a simple nice-to-have. It’s a critical requirement that affects regulatory compliance, data quality, ethical AI practices, and overall model performance. When you know who is labeling your data – and where – you know what to expect.
The Black Box Behind the Labels
When you buy data annotation services, you receive a completed dataset, labeled to specification and delivered on schedule. But in most cases, you have no idea of who produced that work. Many teams see data annotation as a kind of “black box.” They upload raw data to a cloud platform, wait for it to be processed, and then download a labeled dataset.
But in reality, a bigger portion of this work is still done by human annotators. Real people review images, interpret text, and tag data so machine learning systems can learn from it. These workers are hidden behind platforms and dashboards, and you cannot see how much they do. This creates the illusion that the process is fully automated. In truth, thousands of hours of human work often sit behind the labeled datasets that modern AI systems use.
In many cases, providers don’t specify who is doing the work and describe their workforce as a “global crowd” or an “elastic cloud.” But when the workforce remains invisible, you lose important context about how your data is being prepared. And that lack of transparency creates real risks.
If a model starts making errors, for example, it may misidentify safety hazards in computer vision tasks or misinterpret language in NLP systems, you will not be able to determine why. Without a transparent AI supply chain, it’s almost impossible to identify and fix the underlying issue. Moving beyond the “black box” means understanding the role of humans in the process.
Why Location Matters – The Core Arguments
The data annotation outsourcing market is expected to grow by more than 10% each year through 2034. Key delivery hubs include India (a leading center for large-scale image and video labeling), the Philippines, Eastern Europe, as well as emerging markets across Africa and Latin America. Unfortunately, not all annotators can label all data effectively, regardless of training. Location often determines whether an annotator has the lived experience necessary to understand your data correctly. And here’s where it gets especially risky.
Cultural Bias in Data Annotation
An annotator in Manila may speak fluent English, but will they catch the cultural subtext of a marketing video for teenagers in the rural US? An annotator in Cairo may read Arabic script, but can they interpret the dialect-specific idioms in a customer service transcript from Morocco? Probably not. Data annotation workforcestyle matters most for:
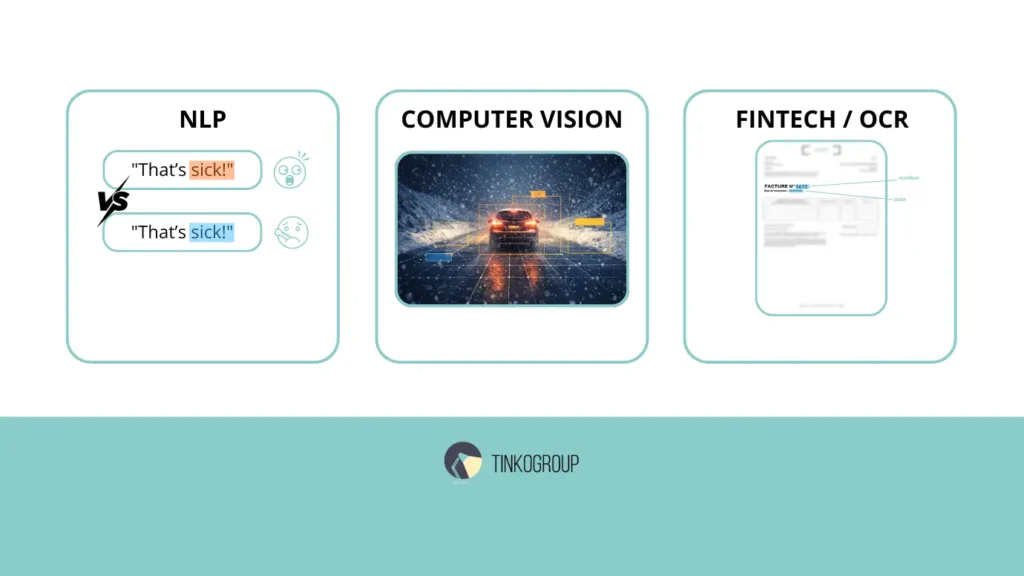
- Natural Language Processing. Let’s take sarcasm, idioms, and sentiment that are geographically tethered. A phrase that means excitement in London may signal aggression or confusion in Singapore. If you are building a customer service bot for a North American retail market, but your annotators are located in Asia, the emotional coloring of the data will be off. You may end up with a model that feels robotic or even offensive to your end-users.
- Computer Vision. Autonomous driving is a primary example. Annotators need to understand many different real-world environments. But they can only label things correctly if they are familiar with them. For example, someone who has never experienced winter conditions may struggle to identify black ice on a road or tell the difference between a snowbank and a solid barrier. Road signs are also different from country to country. A sign in Germany can look completely different from a similar sign in the US.
- Specialized Domains. For FinTech and Document Processing (OCR), annotator location transparency influences accuracy. Different regions have unique tax symbols, date formats (DD/MM/YYYY vs. MM/DD/YYYY), and currency placements. An annotator unfamiliar with the specific administrative layout of a French “facture” or a Japanese “receipt: will inevitably introduce inaccuracies into the dataset.
The cost of this mismatch is invisible, but measurable. Models trained on data labeled by out-of-context workers develop blind spots. They perform well on benchmark tests but fail unpredictably in real-world deployment.
Data Sovereignty & Compliance
The “global crowd” model sounds flexible, but it introduces risks that many organizations would never accept if they could see them. When work is distributed to thousands of anonymous individuals across dozens of countries, you lose the ability to enforce basic security protocols. You cannot:
- Verify that devices are secure and free from malware
- Ensure that screens are not being photographed or recorded
- Confirm that the data is deleted after the annotation is complete
- Prevent annotators from sharing data with unauthorized third parties
- Audit who had access to which pieces of sensitive information
These risks are not theoretical. Modern regulations have made data handling much stricter. These are GDPR, CCPA, HIPAA, and the EU AI Act.
- EU-origin data often requires EU-based annotators or equivalent safeguards.
- Health data may demand onshore or highly audited locations.
- Role-based access controls and encryption help, but the physical jurisdiction of the annotators still matters for data sovereignty in AI.
If you don’t know where your annotators are located, you can’t be sure your data hasn’t been accessed from another country where different rules apply. And that could put you at risk of breaking the law.
Security Risks
Location transparency is also physical security. Many “black box” platforms rely on unmanaged crowdsourcing to save costs. In this model, location is a moving target. An annotator may be working from a public cafe on an insecure Wi-Fi network, or even in a shared living space where your sensitive data becomes visible to unauthorized eyes.
When a provider offers location transparency in AI, it’s a Managed Team model. This means the annotators are working in secure, vetted facilities with:
- Environments where smartphones and recording devices are prohibited.
- Secure infrastructure with encrypted VPNs and SOC2-compliant hardware.
- Physical oversight where professional managers can check how your data is handled.
In the “cloud” model, you never know if the work is being sub-outsourced to a third party or performed in a high-risk environment. In 2026, as industrial espionage and data scraping become more sophisticated, the physical security of your data annotators is a front-line defense for your intellectual property.
The Hidden Costs of “Cheap” Crowdsourcing
The temptation to choose the lowest per-task price is understandable. Actually, anonymous crowdsourcing platforms look like a bargain. However, it can become the most expensive investment a company can make. The true cost of data is not the price of the label, but the total cost of ownership (TCO) across the entire model development process.
The main hidden cost is rework. If you use crowdsourcing, you can face a really high rejection rate – up to 30%. Fixing these mistakes is the most expensive part of any AI project, as teams need to debug, re-label, and re-train. According to 2026 industry benchmarks, 26% of AI project failures are now due to low data quality. The “1x-10x-100x” rule works here – you can catch a label error early at 1x cost, or fix it later at a cost of 100x.
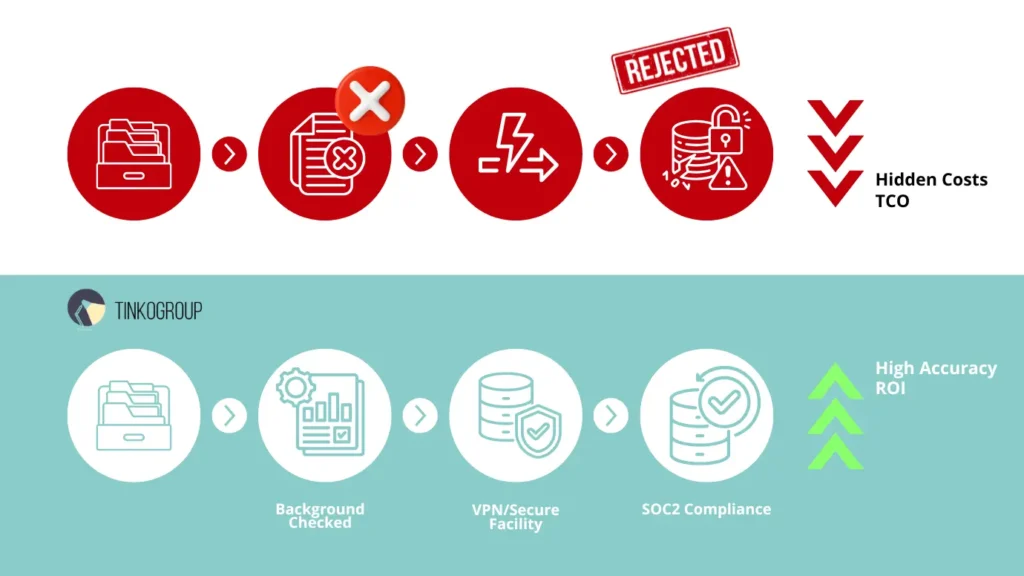
Poor data creates another problem – model drift. If your labels come from unverified workers, your model may perform well in testing but fail in the real world. Over time, accuracy drops, and results become less reliable. This seriously affects trust. In healthcare, autonomous driving and other high-risk industries, it can lead to legal and safety issues.
Transparent teams are different. They have a clear process, quality control standards and give regular feedback. Plus, they are fast. When you partner with such a vendor, you get better data, build more accurate models, and avoid costly fixes later. Human-in-the-loop transparency means a strong AI model, not a technical problem.
A good example of outsourced data labeling risks is Google’s reCAPTCHA tool, which was designed to stop bots. It is very similar to data labeling tasks used in machine learning, but here humans solve image puzzles. In some versions of the system, millions of users have identified objects in images to prove they’re human, and that interaction has been used to improve recognition systems over time. It’s estimated that users spend billions of hours on these puzzles and created labeled data for training AI systems.
But it was done without clear quality controls or compensation. And here is the problem. The questions can vary widely and users don’t get consistent instructions or feedback, so the labels are often noisy. It illustrates a hidden cost of cheap, anonymous crowdsourced data. This data needs to be validated, cleaned, and corrected before it can be used reliably in real models.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

The Ethics of AI Supply Chain
AI becomes central to business and society, and the ethical AI data is more important than ever. For years, the data labeling industry relied on “digital sweatshops” in locations where workers faced low pay, poor conditions, and no psychological support.
The first step to fixing this is location transparency in AI. When providers openly show where their annotators work from, it lets companies audit their supply chain and ensure ethical practices. In 2026, top companies follow Responsible AI frameworks, for example the OECD Due Diligence Guidance, which require fair labor conditions for everyone.
When you work with a transparent partner, you support these ethical pillars:
- Fair pay. Annotators receive a decent wage for their local living.
- Safe, professional conditions. Fragmented gig platforms are replaced by managed teams with proper oversight, ergonomic setups, and mental health support.
- Human rights compliance. Transparent AI is against labor exploitation in regions with weak protections.
A vendor who can document all of this is not only the ethical choice, but they are the commercially safer choice.
Annotator location transparency is the starting point. You cannot audit what you cannot see. The very first thing before you use data annotation services is knowing where your annotators are located. It immediately explains everything else – it verifies labor conditions, confirms jurisdictional compliance, guarantees psychological support is in place, and allows you to stand behind your AI supply chain when you are asked – and sooner or later you will be asked.
Tinkogroup’s Approach – Transparency by Design
We don’t hide our workforce behind a dashboard. Every project begins with a careful recruiting process. We identify and hire annotators who match the specific location, language, and domain expertise your data requires. Need native French speakers with financial documents or those familiar with North American driving environments? Specialists who understand Southeast Asian e-commerce contexts? We build the right team for your data, not a random crowd.
Our annotators work in well-organized, secure environments with documented quality controls and fair labor practices – you can audit these conditions at any time. You always know who sees your data, where they are, and what standards govern their work.
Before you talk pricing, ask a vendor where their annotators actually are. It’s a simple question, but the answer tells you almost everything you need to know about how seriously they take quality, compliance, and the people behind your data. Ready to work with a team you can actually see? Explore Tinkogroup’s Data Annotation Services and find out what transparent annotation looks like in practice.
How does geographic location affect data quality in NLP and Computer Vision?
In NLP, local context is vital for understanding dialects, sarcasm, and cultural nuances. In Computer Vision, annotators must be familiar with specific environments (e.g., winter conditions or regional road signs) to identify objects correctly and avoid training models with inherent blind spots.
How does location transparency affect the Total Cost of Ownership (TCO) of an AI project?
Transparency reduces TCO by eliminating “hidden costs” like high rejection rates and model rework. Managed, transparent teams ensure high-quality labels from the start, preventing costly errors and model drift. Following the 1x-10x-100x rule, catching a labeling mistake early through a transparent process is 100 times cheaper than fixing a failed model after deployment.
How does annotator location transparency enhance data security?
It allows clients to verify that their data is being processed in secure, SOC2-compliant facilities rather than on unmanaged devices or public networks. Location transparency ensures that physical security protocols, such as “no-phone” zones and encrypted VPNs, are strictly enforced by professional on-site management.


