

In recent years, automating user interactions has become a necessity for companies of all sizes. However, as experts’ experience shows, the development of chatbots and automated customer support systems often faces the same fundamental problem: human language is incredibly diverse, and simple rules and templates do not always work. This is where the concept of intent annotation comes to the fore.
Intent annotation is the process of tagging texts with specific user goals or intentions. At first glance, it seems obvious: just match the user’s request with the appropriate category, and the chatbot will be able to respond correctly. But in practice, as experts note, the task is much more complicated. People formulate their requests in different ways, using slang, abbreviations, typos, ambiguous expressions, and mixing several goals in one statement. Without carefully marked data, any system quickly reveals its limitations.
A real-life example: a large internet provider tried to automate customer support using a rule-based chatbot. Initially, the developers created a set of rules for standard requests such as “my internet is not working” or “why haven’t I received my bill.” After a few weeks, it turned out that almost half of the requests that contained the slightest deviation from the wording of the rules remained unprocessed. Customers started calling support, and the chatbot turned into a useless “stream of default responses.” Experts came to the conclusion that without systematic intent annotation, any attempts to build a smart chatbot are doomed to partial success.
Accurate intent annotation is a kind of bridge between human language and machine task execution. It not only helps classify user intent, but also creates a basis for training machine learning models that are capable of distinguishing nuances in meaning, understanding context, and adapting to new formulations. Moreover, high-quality annotation forms the basis for building the correct intent taxonomy, simplifies the integration of Named Entity Recognition, and provides the ability to scale the chatbot as the volume of requests grows.
As noted by old-school experts who remember the days before neural networks and generative models, it was precisely the careful manual work with data that made the difference between a “purely technical” and a “truly intelligent” chatbot. Unlike modern systems, which can create the appearance of understanding through template patterns, real solutions have always been based on human-in-the-loop, careful verification, discussion of ambiguous cases, and detailed documentation of annotation rules.
The Mechanics: Understanding Intent in NLP
When it comes to building smart chatbots, one of the key tasks is understanding how the system interprets user queries. Natural Language Processing (NLP) is the foundation of any intelligent system that works with text, but understanding how models “see” language is extremely important for correct intent annotation.
NLU Basics
NLU data preparation is the first stage of any natural language processing system. Experts note that an NLP model never “understands” text the way a human does. It analyzes words, their order, context, and statistical patterns. Simply put, the model learns to recognize patterns that most often correspond to specific intentions.
In real life, as old-school specialists recall, the data preparation process was much more complicated than simply collecting text and labeling it. For example, when working with customer support logs, you may encounter hundreds of variations of the same request: “The Internet is not working,” “No network,” “The signal is gone,” “Why was Wi-Fi turned off?” — all these utterances reflect the same goal, or intent: report_outage.
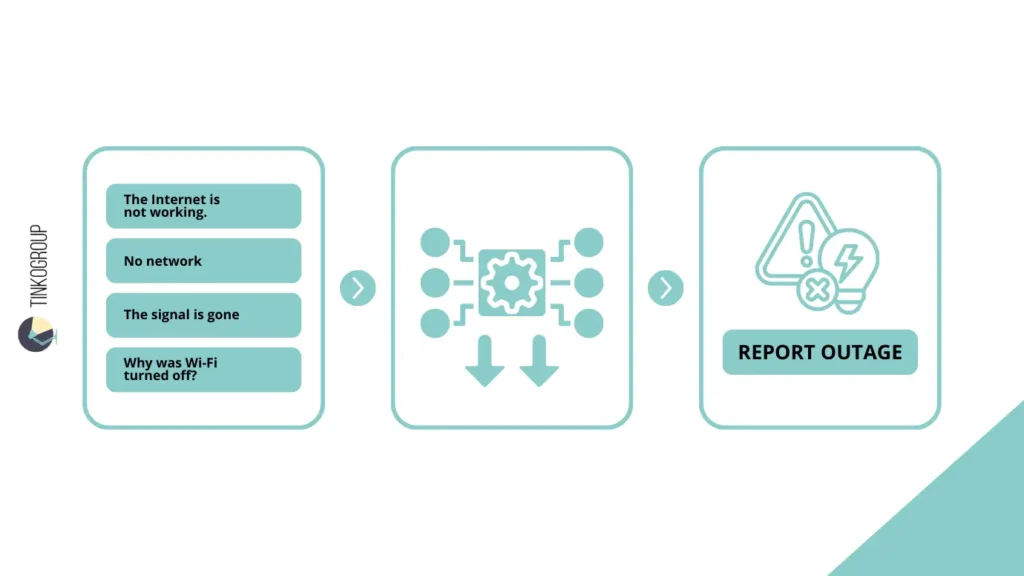
It is important to remember that without accurate annotation, models will learn from noisy data. Even small errors in annotation can cause the system to misclassify queries, and the user will receive an incorrect response. Experts at the time often encountered this when the first machine models showed an accuracy of 60-70%, and after correct manual annotation — above 90%.
Intent vs. Utterance
The difference between utterance and intent is fundamental to any work with chatbots. Utterance is a specific statement made by a user, text that they wrote or spoke. For example: “My internet isn’t working.”
Intent is the goal pursued by the user, the meaning of the statement, what the system’s response should lead to. In this example, the intent would be:
report_outage
As observations by practicing specialists show, the same goal can be expressed by dozens of different utterances. Without systematic intent annotation, even advanced machine learning models get lost in the variety of formulations.
The Role of Machine Learning Models
Machine learning models learn from labeled data, linking specific utterances to corresponding intents. Experience shows that even the simplest models require a large amount of high-quality data to correctly recognize intents.
Real-world case: An internet provider collected tens of thousands of logs of communications with support. Initial attempts at training without accurate annotation showed that the chatbot often confused report_outage with check_account_status. After experts manually annotated the data and refined the intent taxonomy, recognition accuracy increased from 68% to 92%.
It is noteworthy that the old schools of NLP always emphasized the need for human-in-the-loop. Even the most advanced models of the time could not correctly interpret slang, typos, and contextual nuances without human involvement. Therefore, effective intent recognition mechanics always combine a statistical model with careful annotation and verification.
Intent vs. Entity Recognition
When it comes to building smart chatbots, it is important to clearly understand the difference between intent and entities. As practitioners note, many beginners confuse these concepts, thinking that it is enough to simply classify queries. In reality, intent annotation and entity extraction perform different but complementary tasks.
Intent reflects the user’s goal. It is what they want to do or find out. For example, the query “I want to book a flight to Paris” has the intent book_flight.
On the other hand, an entity is a detail necessary to complete the task. In our example, the entity is Paris, the destination city. Experts emphasize that without entity extraction, a chatbot will not be able to process a query correctly, even if the intent is recognized correctly.
Named Entity Recognition (NER)
The Named Entity Recognition (NER) method is used for automatic detail extraction. It allows the model to identify key elements in the text: names, dates, places, amounts, and other objects that help fulfill the user’s intent.
Real-life case: a major airline implemented a chatbot for booking tickets. In the first versions, the bot correctly recognized the intent book_flight, but did not identify the destination cities. As a result, the bot repeatedly asked the user about the departure and arrival locations, creating inconvenience. After implementing NER, the system automatically identified cities, dates, and ticket classes, which significantly reduced the number of unnecessary clarifying questions and increased user satisfaction.
Why Both Annotations Are Needed at the Same Time
Experience shows that for most real-life scenarios, it is necessary to mark up intents and entities at the same time. Here is an example from an online store: a user writes, “I want to return an order and check my balance.” There are two intents here: return_order and check_balance. At the same time, there may be entities: order number, purchase date.
If you try to annotate only the intent, the system will not understand which specific order the request refers to. If you annotate only entities, it will not be clear what exactly the user wants to do. Joint annotation ensures accurate intent recognition and allows the chatbot to respond correctly even to complex multi-component requests.
As old-school experts note, it was this approach — a combination of intent annotation and NER — that formed the basis of reliable systems before the advent of modern generative models. It allowed the creation of chatbots that did not simply “respond to words” but truly “understood” the user’s tasks, albeit at the level of predefined patterns.
Designing Your Intent Taxonomy
Before you start annotating data, it is crucial to think through your intent taxonomy — the structure of all possible user intents that the chatbot should recognize. As experts note, mistakes at this stage are difficult to correct later on and can “break” the entire system.
How to Define Classes Effectively
Experience shows that defining intent classes requires attention and understanding of real-life usage scenarios. Simple classifications such as “technical support” or “finance” often prove to be too broad. In practice, experts advise first collecting data from user communication logs, observing which goals occur most often, and only then forming categories.
Real-life case: a large retailer created a chatbot for customer support. Initially, they divided intents into three broad categories: Order, Return, Questions. After a month, it became clear that the bot couldn’t handle specific requests because there were many sub-goals hidden within these broad categories. After revising the intent taxonomy and adding subcategories such as Order_return, Money_return, and Return_status, intent recognition accuracy increased from 75% to 93%.
Granularity: The Balance Between Too Broad and Too Specific
Class granularity is one of the most difficult issues. Too broad categories simplify labeling but complicate model training and lead to inaccurate responses. Too detailed categories make labeling laborious and increase the risk of errors, especially when working with large amounts of data.
Experts at the time advised looking for a “happy medium.” For example, instead of creating a separate intent for each payment method, you can combine them into a Payment category, adding entities for the payment method. This approach allows models to learn faster and reduces the number of missed intents.
Hierarchy: Grouping Intents
Creating an intent hierarchy makes it easier to scale and maintain a chatbot. Older specialists often used a structure like this:
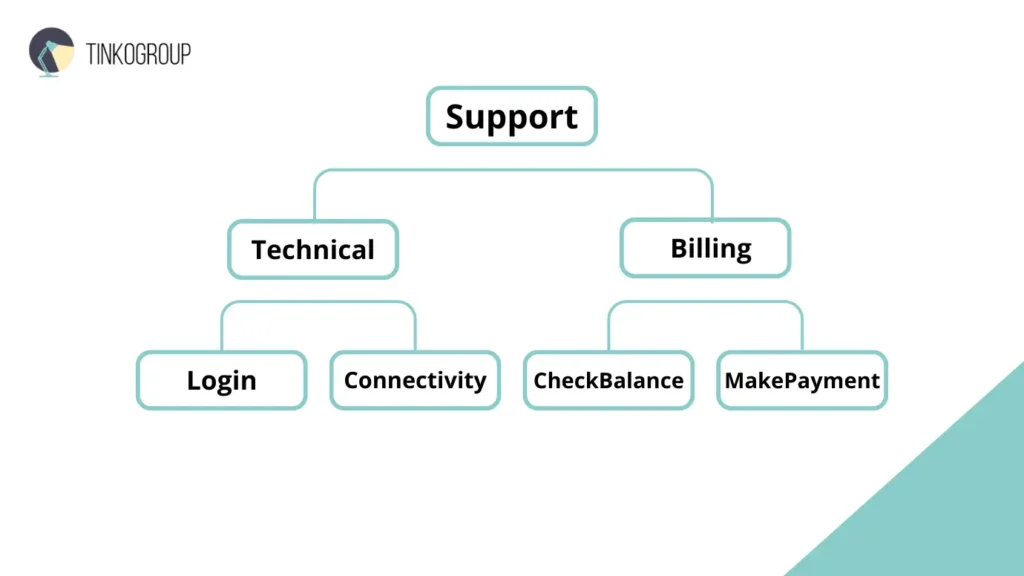
This organization allows you to clearly separate tasks at both the annotation stage and during model training, reduce overlap between classes, and easily add new intents when expanding functionality.
A real-life example from the banking sector: a chatbot with a hierarchical intent taxonomy was able to correctly distinguish between requests such as “Check balance” and “Transfer money,” even if the user formulated the requests in an unusual way. Without such a structure, the bot began to confuse intents and gave incorrect answers, reducing customer confidence.
Experts at the time emphasized that a well-thought-out intent taxonomy is not just a structure, but the foundation for high-quality intent annotation, intent recognition, and machine learning models. The effectiveness of the entire chatbot and the level of user satisfaction depend on how correctly the taxonomy is constructed.
The Process of Intent Annotation
Experience shows that it is the process of intent annotation that determines how intelligent and useful a chatbot will be. Even the most advanced machine learning model is useless without high-quality annotated data. Old-school experts who worked with the first NLP systems noted that annotation takes more time than developing the model itself. But without this work, no system will be able to correctly recognize intent, especially if the user does not write according to a template.
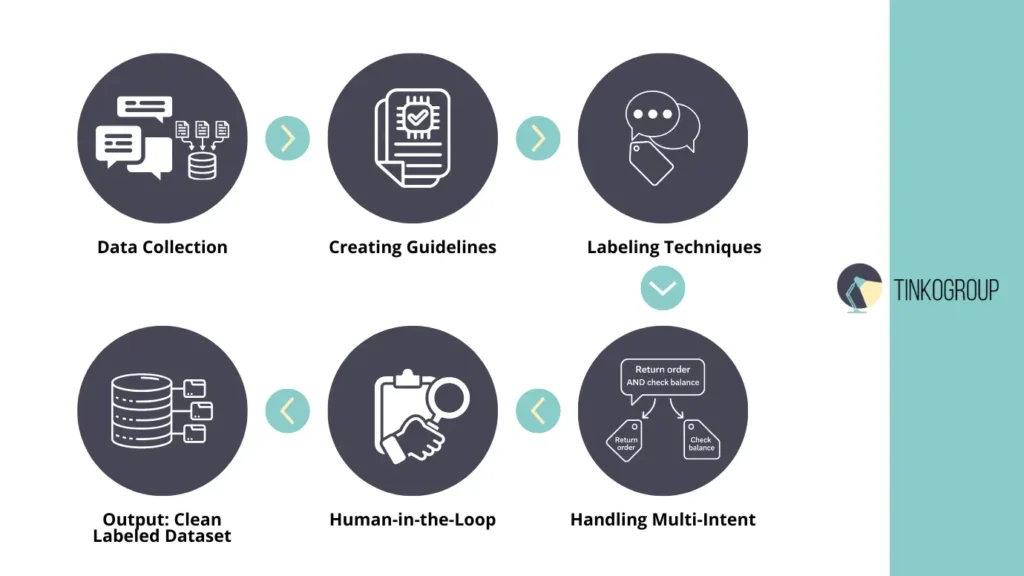
Data Collection
The first step is to collect chatbot training data. There are various sources:
- Logs of real conversations with customers are the most valuable resource. They show how users formulate requests in practice, including errors, slang, and ambiguous phrases.
- Synthetic data is generated specifically for training. It is useful for rare intents or situations that are rarely found in real logs.
Real case: one company that develops chatbots for online stores initially collected only logs from the website. However, it turned out that rare queries, such as “I want to return a gift to a friend,” were too infrequent. After adding synthetic data, the bot learned to correctly process even unusual phrases without losing accuracy for basic intents.
The Labeling Workflow
At the core of any successful intent annotation project lies a carefully designed labeling workflow. Practitioners with long-term experience in NLP projects consistently point out that annotation quality is rarely determined by tools alone. Much more often, it depends on whether the workflow anticipates ambiguity, human error, and the evolving nature of language. A weak workflow produces fragmented datasets, while a mature one gradually stabilizes intent recognition and reduces noise in training data.
In practice, annotation is not a one-time action but a continuous, iterative process. Data is labeled, reviewed, challenged, corrected, and sometimes relabeled entirely. Teams that underestimate this cyclical nature often face a sharp drop in model performance once the chatbot is deployed in real user environments.
Creating Guidelines
Creating annotation guidelines is a mandatory first step, not an optional formality. Without clearly documented rules, different annotators inevitably interpret the same utterance in different ways. For example, the phrase “I need a refund” may be labeled as return_order by one annotator and as refund_request by another if the distinction is not explicitly defined.
Experienced teams treat guidelines as living documents. They usually include precise definitions of each intent, examples of typical utterances, edge cases, and explicit instructions on how to handle overlaps between similar classes. Over time, these documents grow as new patterns emerge from real user data.
Experts emphasize the importance of openly discussing subjectivity during guideline creation. Even minor disagreements between annotators are valuable signals. They reveal ambiguous wording, hidden assumptions, or gaps in the intent taxonomy. By resolving these disagreements early and documenting the decisions, teams significantly improve inter-annotator agreement and long-term dataset consistency.
Text Labeling Techniques
To ensure completeness and robustness of training data, mature projects rely on several complementary text labeling techniques rather than a single approach.
Utterance labeling focuses on tagging individual user messages in isolation. This method is fast and works well for straightforward, single-intent queries, but it often fails when meaning depends on prior context.
Intent tagging goes a step further by explicitly assigning a user goal to each utterance. In more advanced setups, a single utterance may receive multiple intent tags, along with priority or sequencing information. This approach reflects real user behavior more accurately, especially in task-oriented chatbots.
Dialogue annotation is used when intent cannot be reliably understood without context. In multi-turn conversations, the same phrase can have entirely different meanings depending on what was said before. Dialogue-level labeling captures these dependencies and allows models to learn intent transitions over time.
A real-world banking example illustrates this clearly. A chatbot processed conversations such as: “Hello, I want to transfer money. But first, check my balance.” When annotation was limited to individual utterances, the model frequently misclassified the user’s primary intent. After dialogue annotation was introduced, the system learned to interpret intent sequences and correctly handled both actions in the appropriate order.
This experience reinforced a key lesson shared by many experts: skipping dialogue annotation may save time early on, but it almost always leads to costly corrections later, when the chatbot encounters real conversational complexity in production.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Handling Multi-Intent Utterances
Multi-task requests are common. For example: “Hello, I want to return my order and check my balance.”
This phrase contains several intents: return_order and check_balance. Experts at the time advised tagging each intent separately, adding information about entities and the order of actions so that the bot could respond correctly to each element of the request.
Human-in-the-Loop
Even the most accurate model cannot replace a human at the annotation stage. human-in-the-loop is necessary to recognize slang, typos, local language features, and ambiguous constructions.
Real case: a large telecom company found that requests with the phrase “no signal” sometimes referred to Internet problems, and sometimes to television service. Only human involvement made it possible to accurately annotate such utterances and avoid intent classification errors that could have led to a loss of customer trust.
Experts note that at the intent annotation stage, it is important to combine automated tools and human control. This approach ensures high accuracy, reduces the number of errors, and forms a reliable basis for training machine learning models.
Common Challenges in Intent Recognition
Experience shows that even with a carefully thought-out intent taxonomy and accurate data markup, the intent recognition process faces a number of fundamental problems. Old-school experts often emphasized that understanding these difficulties in advance allows you to build more reliable and adaptive chatbots.

Ambiguity
One of the main problems is the ambiguity of queries. A simple phrase like “I want to cancel” can have several meanings at once: cancel an order, cancel a subscription, opt out of notifications.
Real-life case: a large online store implemented a chatbot for customer support. In the first few weeks, the system regularly confused the intent cancel_order and cancel_subscription. Only after detailed analysis and the addition of contextual interpretation rules, as well as clarification of annotations through human-in-the-loop, did the bot begin to correctly distinguish between similar phrases.
Out-of-Scope (OOS)
Not all user requests are related to the chatbot’s functions. Out-of-Scope (OOS) requests are common — for example, jokes, complaints about competitors’ delivery, or questions unrelated to the product.
Experts recommend creating a separate OOS class so that models can correctly identify irrelevant utterances. Without this, the bot tries to classify everything in a row, which leads to strange and unacceptable responses.
A real-life example: in a project for a telecom company, users wrote “Why are you so expensive?” and “My cat ate the router.” Initially, the system tried to assign these messages to existing intents, which led to absurd responses. The introduction of the OOS class solved the problem and reduced the number of complaints about misunderstandings.
Class Imbalance
Another common problem is class imbalance. In large chatbots, some intents occur tens of thousands of times (e.g., check_balance), while others occur only a few times (report_lost_card).
If the imbalance is not taken into account, the model will ignore rare intents or classify them incorrectly. Experience shows that it is necessary to either add synthetic data for rare intents or use class weighting methods when training the model.
Real-life case: one bank encountered a problem when users rarely requested “Close account.” Initially, the model simply ignored these requests. After adding additional examples and manually checking rare intents through human-in-the-loop, recognition accuracy increased from 50% to 90%, significantly improving the user experience.
Industry Use Cases
Expert experience shows that intent annotation and accurate intent recognition are used in a variety of industries. Veteran specialists who worked with the first large chatbots noted that the real value of such systems is only apparent in specific scenarios where understanding the user directly affects business efficiency.
Customer Support
In customer support services, ticket routing automation is one of the most obvious use cases. Previously, all requests were processed manually, which required a huge number of employees.
Here’s an example from a big telecom provider: when they rolled out a chatbot with accurate intent annotation, the system could automatically figure out the intent of a request — like report_outage, billing_issue, technical_support — and send tickets to the right people. Before the bot was implemented, the average request processing time was 24 hours; after, it was less than 2 hours, and the number of missed or misclassified tickets was reduced by almost half.
Banking
Financial services are particularly sensitive to the accuracy of intent recognition. Users often write briefly and concisely, but with different wording.
Real case: a bank implemented a chatbot to process account requests. At first, the system confused check_balance and transfer_money requests because phrases such as “How much money do I have?” and “Transfer to my card” appeared in the logs. After detailed intent annotation and context-aware model training, the bot began to correctly distinguish between these intents, which reduced the number of errors in financial transactions and increased customer confidence.
E-Commerce
The e-commerce industry is another area where high-quality annotation is critical. Users ask questions about orders, returns, and delivery, and often mix several intents in a single message.
Example: in an online store, the bot received messages such as “Where is my order and can I return the item?” — two intents at the same time: track_order and return_policy. Without accurate annotation and entity extraction, the system either ignored part of the request or responded incorrectly. After implementing human-in-the-loop and multi-intent annotation, the bot began to correctly process such complex requests, increasing customer satisfaction and reducing the load on operators.
Old-school experts emphasize that it is the combination of high-quality intent annotation, entity extraction through Named entity recognition, and thorough data verification that ensures the successful application of chatbots in real business scenarios. Without this, any technical solution remains merely a beautiful demonstration of capabilities rather than an effective tool.
Conclusion
The experience of practitioners who worked with chatbots long before the advent of modern generative models clearly demonstrates one simple truth: a chatbot is only as intelligent as the quality of its data. Neither complex architectures nor trendy algorithms can compensate for poorly labeled, inconsistent, or superficial training sets.
Intent annotation remains the foundation of any intent recognition system. It is what connects living, imperfect human language with the formal logic of machine execution. When intents are defined incorrectly, taxonomy is constructed chaotically, and annotation is performed without human involvement, the chatbot begins to “guess” rather than understand. And users sense this almost immediately.
Experts note that the most successful projects in the field of conversational AI always began not with the choice of a model, but with painstaking work on chatbot training data annotating intent, a well-thought-out intent taxonomy, and constant human involvement in the annotation process. This approach ensures stable intent recognition, reduces the number of errors, and allows the system to scale without losing quality.
In an era where automation has become the norm, it is attention to detail, depth of analysis, and respect for human language that distinguish truly intelligent chatbots from superficial solutions.
If your team needs a professional approach to intent annotation, data preparation, and building stable NLP systems, it makes sense to rely on the experience of specialists for whom annotation quality is not a formality but the basis of the result.
You can learn more about data annotation and training set preparation services on the Tinkogroup page.
Why is human-in-the-loop essential for Intent Annotation?
While AI can automate much of the process, human experts are necessary to interpret slang, sarcasm, and complex context that models often miss. This manual verification ensures the high accuracy required for professional business solutions.
How many intents should my chatbot have?
It depends on your business needs, but a well-designed taxonomy usually starts with broad categories and breaks down into specific sub-intents. Finding the right balance prevents the model from becoming too simple or overly complex.
Can Intent Annotation improve an existing chatbot?
Absolutely. By analyzing your current conversation logs and re-annotating the data, you can identify where the bot is failing and refine its recognition capabilities to significantly reduce error rates.


