

Historians will likely divide artificial intelligence into the Era of Identity and the Era of Intent. Before dynamic tools like keypoint tracking emerged, static methods trapped the computer vision industry in the past. We spent billions teaching machines to name objects in a vacuum, perfecting crude bounding boxes around pedestrians and vehicles. This “Identity AI” identified objects with 99% accuracy but remained fundamentally blind to their physical interactions over time.
In 2026, we have reached the limit of what static sight can achieve. The industry is currently undergoing a “Motion Revolution,” a tectonic shift that renders traditional image analysis obsolete for next-generation applications. Why? Because a bounding box is a lie.
It is a mathematical abstraction that strips away the most vital component of intelligence: kinetic context. A box treats a human being as a rigid, unyielding rectangle. It ignores the bend of a knee, the tension of a shoulder, and the subtle shift in a person’s center of gravity. For the CTOs and research leads building autonomous surgeons, elite athletic trainers, or predictive security systems, a bounding box isn’t just insufficient — it is a dangerous oversimplification.
This crisis of context has paved the way for keypoint tracking to emerge as the undisputed “Gold Standard” for video data.
To define it in its most essential form, keypoint tracking is the process of identifying and mapping specific anatomical or mechanical landmarks — spatial “anchors” — across every millisecond of a video stream. It is the transition from seeing a “blob” to seeing a “system.” In the world of Motion AI, keypoints are the language of truth. While a bounding box might provide an AI with basic sight, keypoints provide it with something far more profound: a sense of anatomy, biology, and the fundamental laws of physics.
Here’s the core argument: Sight is no longer enough. To build an AI that can function safely and effectively in a dynamic environment, we must move beyond the rectangle. We must map the skeleton. We must track the joints. We must understand the torque and the tension that define human behavior. Through keypoint tracking in AI, we are finally moving past the era of digital scrapbooking and into the era of true physical intelligence.
This shift represents a philosophical upgrade, not just a technical one. By utilizing keypoint tracking in annotation, we equip models to interpret unseen physical forces. We teach them that a hand reaching for a pocket signals specific human intent, forming the bedrock of action recognition. As we scale video keypoint tracking to petabyte levels, companies relying on static 2015 methods will become functionally illiterate in a moving world.
This guide explains why this methodology is the only viable path forward for high-stakes machine learning on video data. We will explore the mathematical superiority of keypoints, the evolution of human pose estimation, and the brutal operational realities of maintaining temporal consistency amid real-world noise. For the visionary investor or tech lead, the choice is no longer between “cheap” and “precise.” The choice is between building an AI that records the past or an AI that can finally reason through the present.
Why Keypoint Tracking is the “Gold Standard”
In data science, the signal-to-noise ratio determines value. For decades, the bounding box was the industry’s “good enough” compromise. It was a low-resolution signal that told us an object existed. But in the era of Motion AI, “presence” is a commodity. “Dynamics” is the premium asset. The transition to keypoints is not just a trend; it is a fundamental shift toward capturing higher data density per frame.
The Brutal Math of Data Density: Rectangles vs. Meshes
Let’s look at the numbers. A bounding box provides exactly four points of data: top-left and bottom-right coordinates. This is a 1D representation of a 3D reality. It tells you the perimeter of an object, but it tells you absolutely nothing about the state of the entity inside that perimeter. It is a hollow shell.

When you implement keypoint tracking in annotation, the information value doesn’t just increase — it scales exponentially. Consider a facial analysis model. A bounding box identifies a “head.” But a 68-point facial mesh, mapped via video keypoint tracking, captures the micro-geometry of human expression. It provides:
- Semantic Landmarks. The exact positioning of the ocular regions, the nasolabial folds, and the vermilion border of the lips.
- Volumetric awareness. A sense of how the face rotates in 3D space, which is impossible with a flat rectangle.
- Sub-surface cues. The ability to detect muscle tension that signals a shift from “neutral” to “aggressive” or “distressed.”
For action recognition, this density is the difference between a model that guesses and a model that knows. If your computer vision datasets are built on boxes, you throw away 90% of the usable signal in every frame.
Precision Beyond Presence: Angles, Velocity, and Acceleration
The “Gold Standard” status of keypoints is anchored in their relationship to the laws of physics. A bounding box is unstable. As an object moves, the box’s edges “jitter” and resize in response to changes in lighting or perspective. This makes it impossible to calculate true physical metrics.
However, precision data annotation using keypoints provides fixed anatomical or mechanical anchors. Because a keypoint is pinned to a specific joint — like the distal phalanx of a finger or the axis of a robotic hinge — the AI can finally perform real-world calculus:
- Angular displacement. Measuring the exact 120-degree bend of a knee during a gait cycle to detect a limp.
- Linear velocity. Calculating exactly how fast a hand is moving toward a control panel in an industrial safety context.
- Rotational acceleration. Tracking the torque of a mechanical arm to predict gear failure before it manifests as a total breakdown.
This is the power of keypoint tracking in video annotation. We are no longer just labeling pixels; we are digitizing the physical forces that govern the world.
Radical Versatility: From Bio-Mechanics to Industrial Hydraulics
One of the most visionary aspects of this methodology is its ability to serve as a universal language for machine learning for video. In the past, companies used different annotation techniques for different subjects. Key points break those silos down.
Engineers can apply the same keypoint tracking in AI that analyzes an athlete’s posture to monitor livestock health or prevent human-robot warehouse collisions. By standardizing on keypoints, tech leads build unified pipelines for video annotation services that scale across any industry. Because systems can track any joint—whether in a human, an animal, or a hydraulic press—this approach remains the only way to build a truly comprehensive world model.
Human Pose Estimation (HPE): The Core of Motion AI
The industry has moved beyond the “toy” phase. We are no longer just putting dots on a screen for a research paper. We are building the nervous system for digital health, elite athletics, and human-computer interaction. To do this, we rely on a rigorous hierarchy of standards that define exactly how we digitize a body.
The Pillars of the Industry: COCO, MPII, and OpenPose
Every high-performance model starts with a foundation of computer vision datasets. These are the “rulebooks” that tell the AI where a human being begins and ends.
- The COCO (Common Objects in Context) Standard. This is the most widely used benchmark in the world. COCO defines a 17-keypoint skeleton that covers the major joints — shoulders, elbows, wrists, hips, knees, and ankles — as well as facial landmarks such as the eyes and ears. It is the “universal language” of keypoint tracking in AI.
- The MPII human pose dataset. While COCO is broad, MPII is deep. It consists of around 25,000 images containing over 40,000 people with annotated body joints. It stood out as one of the first datasets to focus on “real-world” activities, moving the tech out of the lab and into the streets.
- The OpenPose revolution. If COCO and MPII were the maps, OpenPose was the first real engine. It was the first multi-person, real-time 2D detection system. It pioneered the use of Part Affinity Fields (PAFs) to associate body parts with specific individuals. For the first time, an AI could look at a crowd and see ten distinct skeletons, not just a jumble of dots.
However, as professionals in video annotation services, we can tell you that even these standards have a shelf life. They are 2D solutions for a 3D world.
The Great Leap: From 2D Pixels to 3D Skeletal Tracking
The most visionary shift happening right now is the transition from “screen coordinates” to “world coordinates.” In a 2D system, if a person turns sideways, the AI often gets confused because one arm “disappears” behind the torso. This is the “Occlusion Trap.”
Modern 3D skeletal tracking solves this by using “Depth Estimation” and “Multi-view Geometry.” We are no longer just asking “Where is the wrist on the screen?” We are asking, “Where is the wrist in 3D space relative to the spine?” This transition allows for:
- Volumetric accuracy. Understanding the true rotation of the hip or shoulder is critical for medical diagnostics.
- Perspective immunity. The ability to track a person as they move toward or away from the camera, not just across it.
- Physics-engine integration. Feeding 3D skeletons directly into game engines like Unreal or Unity for instant markerless motion capture.
This is where machine learning for video becomes truly “intelligent.” It starts to understand the volume of the human form, not just the pixels on the glass.
High-Impact Use Cases: Beyond the Lab
When we apply this high-level keypoint tracking for annotation in real industries, the ROI is tangible. We aren’t just making pretty pictures; we are solving human problems.
- Elite sports performance. Coaches in the NBA and MLB now use video keypoint tracking to analyze a player’s “shot mechanics” or “pitching form.” By comparing a player’s 3D skeleton against a library of “Perfect Form” data, they can identify subtle deviations that lead to fatigue or injury.
- Next-gen physical therapy. Imagine a patient recovering from a knee replacement. Instead of driving to a clinic twice a week, they perform their exercises on a standard tablet. The AI uses HPE to measure its range of motion in real time, providing instant feedback. “Your knee is three degrees off — adjust your stance.”
- Gesture-based control. We are moving toward a “touchless” world. Whether it’s a surgeon in a sterile OR or a worker in a heavy industrial plant, HPE allows them to control complex interfaces with a wave of a hand. This requires absolute temporal consistency; if the tracking lags for even a tenth of a second, the system is unusable.
Keypoint Tracking in Critical Industries
The “Motion Revolution” is not a uniform wave; it is a series of deep-tech vertical disruptions. By utilizing keypoint tracking in AI, industries that once relied on human intuition are now pivoting to algorithmic certainty. We are moving from a reactive world to a predictive one.
Healthcare: The Digital Biomarker Revolution
The most profound application of this technology is arguably in clinical neurology. For decades, diagnosing disorders like Parkinson’s disease, Multiple Sclerosis (MS), or Huntington’s relied on a doctor watching a patient walk down a hallway — a purely subjective observation.

Today, biometric movement analysis via keypoints has turned the “human gait” into a digital biomarker. By tracking keypoint data from a patient’s walk, AI can detect “micro-stumbles” or subtle asymmetries in stride length that are invisible to the naked eye.
- Early diagnosis. These systems can identify neurological decay up to five years before physical symptoms become life-altering.
- Remote monitoring. Standard cameras can track patients in their own homes, ensuring the system monitors medication efficacy 24/7 without the “white coat syndrome” that skews hospital-based tests.
- Rehabilitation. Post-stroke recovery programs now use 3D skeletal tracking to ensure that every repetitive motion in physical therapy is anatomically correct, preventing secondary injuries.
Autonomous Systems: From Presence to Prediction
In the world of self-driving cars and delivery robots, “seeing” a pedestrian is a solved problem. The real challenge — the one that keeps insurance companies and CTOs up at night — is predicting what that pedestrian will do in the next 1.5 seconds.
A bounding box cannot tell you if a child is about to chase a ball into the street. But keypoint tracking in video annotation can. By analyzing the “head tilt” and the orientation of the leading foot, the AI performs a real-time intent analysis.

- Gaze Detection. If the face keypoints indicate the pedestrian is looking at their phone, the car increases its safety buffer.
- Postural Lean. A shift in the center of gravity toward the road triggers an immediate deceleration, even if the person hasn’t moved a foot yet.
- Limb Velocity. The rapid upward motion of a hand (a wave or a signal to stop) is recognized instantly as a command, not just “visual noise.”
This level of machine learning for video is what will finally move autonomous driving from “Level 2” to “Level 5.”
Entertainment: The Democratization of Motion Capture
We are witnessing the death of the “ping-pong ball” suit. For thirty years, high-end Motion Capture (MoCap) was the exclusive domain of Hollywood giants like ILM or Weta. You needed an infrared camera array and a million-dollar budget.
Markerless motion capture, powered by high-density keypoint datasets, has changed the game.
- Gaming. Independent developers can now record professional-grade character animations in a garage using three standard GoPros and a video annotation services provider like Tinkogroup.
- The metaverse. For digital twins and virtual avatars to feel “human,” they must mimic the user’s subtle, nonverbal cues. Keypoint tracking allows for real-time mapping of facial expressions and body language into virtual spaces with zero latency.
- Content creation. Social media filters and AR applications are evolving from simple “face masks” to full-body digital costumes that respect the wearer’s skeletal physics.
Security: Behavioral Biometrics and Intent Recognition
The future of security is not “Who are you?” (Identity), but “What are you doing?” (Behavior). Traditional CCTV is a passive witness to crimes that have already happened. Action recognition powered by keypoints turns these cameras into proactive observers.
By utilizing keypoint tracking in annotation, security AI can identify the “pre-incident” signatures of a fight, a theft, or a slip-and-fall.
- Retail loss prevention. The system ignores a shopper picking up a box but flags the specific “concealment” motion — a rapid downward hand movement toward a bag — triggering an alert to floor staff.
- Violence detection. In public transport hubs, the AI recognizes the “aggressive stance” (wide base, clenched fists, rapid forward lean) before the first punch is thrown.
- Authorized access. In high-security zones, “gait biometrics” teams use gait biometrics as a secondary authentication factor. Even if an intruder has a stolen ID badge, the system recognizes that their skeletal walk cycle does not match the authorized user’s.
The Technical Challenge: Stability and Temporal Flow
The move from static image labeling to Motion AI introduces a chaotic variable: the arrow of time. In a single frame, a keypoint might look perfect. But when you play that video at 60 frames per second, those points often dance like static on an old television. This is not just an aesthetic issue; it is a mathematical failure that renders the data useless for physics-based reasoning.
The “Jitter” Problem and the Quest for Sub-Pixel Smoothness
The most pervasive enemy of high-quality keypoint tracking in AI is “temporal jitter.” This occurs when a tracking point — say, a wrist joint — oscillates rapidly between adjacent pixels from frame to frame.
- The cause. Jitter is rarely caused by the object itself; it is the result of sensor noise, motion blur, or the neural network’s uncertainty in low-contrast regions.
- The consequence. If you are calculating velocity or acceleration, jitter is a catastrophe. A 2-pixel jump in 1/60th of a second translates into a massive, hallucinated “spike” in speed that breaks action recognition models.
- The solution. Achieving “sub-pixel smoothness” requires a combination of advanced filtering — such as Kalman filters or One Euro filters — and temporal consistency constraints during the precision data annotation phase. At Tinkogroup, we don’t just label frames in isolation; we use bidirectional flow analysis to ensure that every point follows a biologically plausible trajectory. If the point moves in a way that would require a human muscle to exert 50 Gs of force, the system flags it as noise.
Re-identification (Re-ID) After Total Occlusion
In the real world, things disappear. A pedestrian walks behind a bus; a medical instrument obscures a surgeon’s hand; a “scrum” under the hoop buries a basketball player. This is “total occlusion,” where 90% of video keypoint tracking systems fail.
When an object reappears, the AI must perform a “Re-identification” (Re-ID). It has to ask: “Is this the same skeleton I saw three seconds ago, or is this a new entity?”
- The persistence of identity. To solve this, we rely on “Spatio-Temporal Embeddings.” We don’t just track the dots; we track the “style” of the movement — the limb lengths, the gait rhythm, and the postural signature.
- The hand-off. This is the most difficult part of data labeling for AI. If the annotator (or the pre-labeling AI) assigns a new ID to the same person after they emerge from behind a tree, the “narrative” of the data is broken. Maintaining a consistent ID throughout a 24-hour feed is the benchmark of a truly professional video annotation services provider.
The Computational “Iron Triangle”: Balancing Accuracy, Resolution, and Speed
Every CTO faces a brutal trade-off. You want 4K resolution for maximum precision, 60 fps for temporal smoothness, and real-time performance on an edge device. In the current hardware landscape, you can usually only pick two.
- The resolution tax. High-density keypoint tracking in video annotation at 4K requires massive VRAM. Most models downsample to 1080p or lower, but this loses the sub-pixel detail needed for clinical gait analysis.
- The Latency Trap. Complex architectures such as Transformers and Graph Convolutional Networks (GCNs) are effective for 3D skeletal tracking but are computationally expensive. In autonomous driving, a 100ms delay in “intent recognition” could be the difference between a successful stop and a collision.
- The optimization strategy. To balance these costs, we are seeing a shift toward “Asymmetric Pipelines.” This involves using a lightweight model for real-time “rough” tracking and a heavy, high-precision model for offline “deep” analysis. For those managing computer vision datasets, the goal is to optimize the data structure so that inference engines don’t have to waste cycles on redundant spatial information.
The Human Element in the Gold Standard

The deeper you go into AI development, the more you realize that the more “autonomous” we want our systems to be, the more “human” our training data must become. While tools promising “fully automated” video annotation services flood the market, any veteran Research Lead knows that automation is merely a productivity multiplier, not a substitute for ground truth. In the high-stakes domain of Motion AI, a machine’s logic is only as good as its last training cycle.
Why Automated Tools Still Fail at “Edge Cases”
AI models thrive on average. They excel at identifying a person walking down a brightly lit sidewalk in high-contrast clothing. But the real world is made of “Edge Cases” — the statistical outliers that cause automated systems to collapse.
- The baggy clothing trap. To an AI, a person in a heavy winter parka or a flowing dress is an anatomical nightmare. The model cannot “see” the elbow or knee through the fabric, so it has to guess. This results in keypoint-tracking video data in which joints are placed 6 inches from the actual body.
- Extreme angles and foreshortening. When a camera is positioned directly overhead or at a sharp low angle, the human form is distorted. Traditional human pose estimation models often fail to reconcile these perspectives, leading to skeletal “collapses” where limbs appear to grow out of the head.
- The Low-light ceiling. In nighttime surveillance or dimly lit industrial plants, sensor noise competes with the subject. An automated tool will often mistake a shadow for a limb, poisoning the computer vision datasets with non-biological “ghost” movements.
Tinkogroup’s Hybrid Approach: AI Speed, Human Truth
At Tinkogroup, we have spent years perfecting a “Human-in-the-loop” (HITL) pipeline that acknowledges the strengths of both parties. We don’t ignore automation; we harness it.
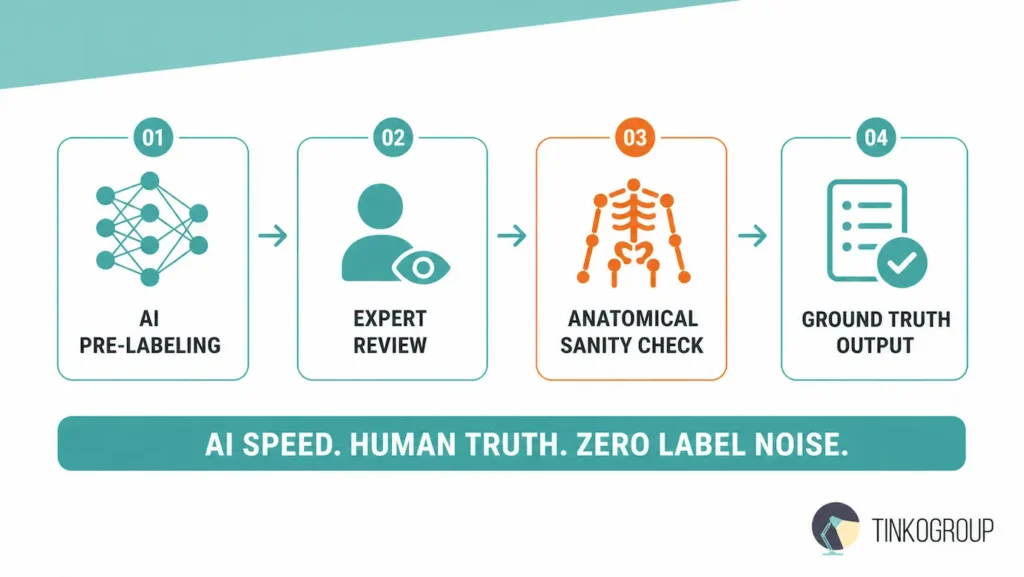
- AI Pre-labeling. We use proprietary, high-density models to perform a “first pass” of keypoint tracking in AI. This handles 80% of the heavy lifting, identifying clear joints and establishing the initial temporal flow.
- Expert verification. Every single frame is then reviewed by a human subject matter expert. These aren’t just “clickers”; these trained professionals understand the nuances of precision data annotation.
- The “Anatomical sanity check.” This is our secret weapon. A machine might place a neck joint at a 90-degree backward angle because it fits the pixel pattern. A human knows that it is a biological impossibility. Our experts apply an “Anatomical Sanity Check” to every sequence, ensuring that the 3D skeletal tracking respects the limits of human ligaments, bone structure, and torque.
Eliminating “Label Noise” in Complex Action Sequences
In my thirty years of moderating content, I’ve learned that “Label Noise” is the silent killer of innovation. If your data labeling for AI contains even a 5% error rate in joint placement, your model will develop “bad habits” that are nearly impossible to train out later.
By employing human experts who specialize in keypoint tracking in annotation, we eliminate this noise at the source. Whether it’s a surgeon’s hands during a complex procedure or a professional athlete’s “hidden” foot during a turn, our humans find what the AI misses. Our process ensures we maintain temporal consistency during total occlusions — something purely automated tools cannot do with 100% reliability. We provide the “ground truth” that allows your AI to actually learn, rather than just mimic.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

The Future: Beyond Points to Surfaces
Motion intelligence is rapidly evolving toward total volumetric understanding, replacing past skeletal abstractions with high-fidelity surface mapping. While today’s “Gold Standard” relies on discrete joints, the next five years’ “Visionary Standard” transitions from sparse points to dense, continuous meshes. Technologies like DensePose exemplify this shift, moving beyond simply identifying limb locations to mapping the entire human body surface against a 3D model.
Unlike traditional skeletal tracking, which treats an arm as a line between two points, surface-based tracking treats the human form as a complex, deformable geometry. This enables a level of precision in data annotation that was previously impossible, as it captures subtle muscle movements, skin folds, and weight shifts across the entire body.
This transition forms the fundamental bridge that allows keypoint tracking to evolve into full 3D digital twins. By combining high-resolution keypoints with surface mesh tracking, we move beyond merely “tracking a person” and begin digitizing their physical essence into a virtual space. For industries like aerospace or high-end manufacturing, this means a digital counterpart can perfectly mirror a worker’s movements to test ergonomic safety or operational efficiency before anyone touches a physical tool.
In the realm of Motion AI, this represents the ultimate synthesis of anatomy and data. We are moving toward a future where AI doesn’t just see a skeleton; it understands the volume, surface tension, and the subject’s complete 3D presence.
Furthermore, integrating 3D skeletal tracking with dense surface modeling will finally unlock the potential of “Reasoning AI.” When a model can see a 3D digital twin rather than just a collection of dots, it can perform much more sophisticated action recognition based on physical interaction. It can understand how a person’s body interacts with clothing, tools, or other people with a degree of nuance that a sparse keypoint model would miss.
This is the ‘high-definition’ future of machine learning for video. As we move beyond points to surfaces, the role of keypoint tracking in AI becomes the indispensable skeleton upon which engineers build these detailed meshes. Without the rock-solid foundation of accurate joint tracking, the surface mesh would collapse into a jumble of polygons. Therefore, mastering keypoint data is not just a current necessity; it is the prerequisite for the entire future of 3D human modeling and digital twin technology.
This progression toward surfaces also fundamentally changes the requirements for computer vision datasets. We are moving from a world where we label “points” to a world where we must validate “volumes.” This increases the complexity of keypoint tracking in video annotation by an order of magnitude, as the temporal flow must stay consistent across thousands of vertices, not just a handful of joints. Ensuring temporal consistency across a full-body mesh is the next great technical hurdle for the industry.
However, for those who successfully navigate this shift, the reward is an AI that truly operates within three dimensions of the real world, capable of reasoning through the complex physical interactions that define our lives.
Conclusion
To win the AI race, you must stop treating video data as a collection of static frames and start treating it as a physical system. The transition from crude bounding boxes to the “Gold Standard” of keypoint tracking is the single most important technical pivot for any company serious about Motion AI. If your model cannot understand anatomy, torque, and intent, it will never survive the transition from the laboratory to the real world.
Investing in high-quality keypoint data today is not just a technical choice; it is a strategic insurance policy. High-density precision data annotation ensures your models rest on a foundation of biological truth rather than algorithmic noise. As we move toward a future of 3D digital twins and 3D skeletal tracking, the precision of your current computer vision datasets will be the deciding factor in your model’s ability to reason, predict, and perform in high-stakes environments like healthcare, autonomous driving, and security.
The “Motion Revolution” is here, and it is unforgiving to those who settle for “good enough” data. Mastery of the temporal axis through temporal consistency and anatomical accuracy is the only way to achieve true action recognition at scale.
Partner with Tinkogroup for industry-leading annotation services. Let us handle the complexity of keypoint tracking in AI, so you can focus on building the intelligence that defines the next decade.
What makes keypoint tracking more effective than traditional bounding boxes?
Unlike bounding boxes, which only detect the outer perimeter of an object, keypoint tracking maps precise anatomical or mechanical landmarks such as joints, limbs, and facial features. This allows AI systems to analyze movement dynamics, posture, intent, velocity, and biomechanical behavior with far greater accuracy. As a result, keypoint tracking enables advanced applications like action recognition, predictive safety systems, and real-time motion analysis.
Which industries benefit the most from keypoint tracking technology?
Keypoint tracking is transforming industries that rely on motion understanding and behavioral analysis. In healthcare, it supports gait analysis and rehabilitation monitoring. In autonomous driving, it helps predict pedestrian intent and improve safety systems. Sports organizations use it for performance optimization and injury prevention, while security systems rely on it for behavioral biometrics and threat detection. Entertainment and gaming also benefit through markerless motion capture and realistic avatar animation.
Why is human validation still necessary in keypoint tracking workflows?
Although AI-powered annotation tools can automate large portions of the process, they still struggle with complex edge cases such as occlusions, low-light environments, unusual camera angles, or loose clothing. Human experts ensure anatomical accuracy, temporal consistency, and correct re-identification across video sequences. Human-in-the-loop validation helps eliminate label noise and guarantees the high-quality training data required for reliable Motion AI systems.


