

In today’s world, the volume of text information is growing at an incredible rate. Every day, millions of documents are created — from news and financial reports to social media posts. Imagine having to read them all manually — it’s impossible. This is where natural language processing applications come in handy, allowing text to be processed automatically and important information to be extracted from it. One of the key tools in this area is named entity recognition (NER).
NER helps machines “understand” text by identifying names of people, organizations, geographical objects, dates, and other entities. This differs from simple keyword extraction: if a conventional system finds the word “Apple,” NER will determine whether it refers to the company or the fruit. This level of understanding opens up many opportunities for business, science, and the development of AI training data.
Imagine an analyst at a bank who has to track news about dozens of companies and their stock prices. Without named entity recognition in machine learning, this would be extremely difficult. With named entity recognition in NLP, systems can automatically find and classify the necessary elements, saving hours of work and reducing the human factor.
What is Named Entity Recognition?
Before delving into the technical details, it is important to understand the essence of named entity recognition (NER). Essentially, NER is the process of automatically recognizing and classifying “named entities” in text. Entities refer to words or phrases that denote specific objects in the real world: people, companies, places, dates, etc.
Example:
Let’s take the sentence: “Tesla unveiled a new electric car model in Berlin on March 10, 2023.”
Using NER, we can identify the following entities:
- Organization: Tesla
- Location: Berlin
- Date: March 10, 2023
Note that NER differs from a simple keyword extraction system (entity extraction). If only an algorithm for finding frequent words were used, it could identify “Tesla” and “Berlin,” but it would not be able to classify them or understand the context. This is why named entity recognition in AI is considered a more intelligent tool.
Common Entity Categories
To understand how named entity recognition works, it is important to know what entities it can identify. The main categories include people, organizations, locations, dates, and other important elements of text. These categories help transform plain text into structured information that is ready for analysis and use in natural language processing applications.
Within named entity recognition in machine learning, several standard categories are usually distinguished:
- Person: Names of real people, such as “Elon Musk”.
- Organization: Companies, institutions, groups — “Google,” “UN”.
- Location: Cities, countries, geographical objects — Paris, Everest.
- Date: Specific dates and periods — July 14, 1789.
- Miscellaneous: Names of products, currencies, events that do not fall into the first categories.
It is important to understand that NER does not simply find words, but links them to context. For example, the word “Apple” can refer to both the fruit and the company. This is where named entity recognition annotation comes into play — manual or semi-automatic text annotation for model training.
Difference Between NER and General Keyword Extraction
Although at first glance named entity recognition and conventional keyword extraction may seem similar, they are in fact fundamentally different approaches to text processing. Keyword extraction focuses on identifying words and phrases that occur most frequently in a document or carry significant semantic meaning. This method is useful for quickly determining the subject matter of a text, but it does not provide information about the type of entities and their role in the context.
For example, in the text “Microsoft unveiled a new version of Windows in San Francisco,” keyword extraction can highlight the words “Microsoft,” “Windows,” and “San Francisco.” That’s where its capabilities end: the method does not understand that “Microsoft” is an organization, “Windows” is a product, and “San Francisco” is a geographical location. This is where named entity recognition comes into play, which not only extracts key elements of the text, but also classifies them into categories such as Person, Organization, Location, Date, and others.
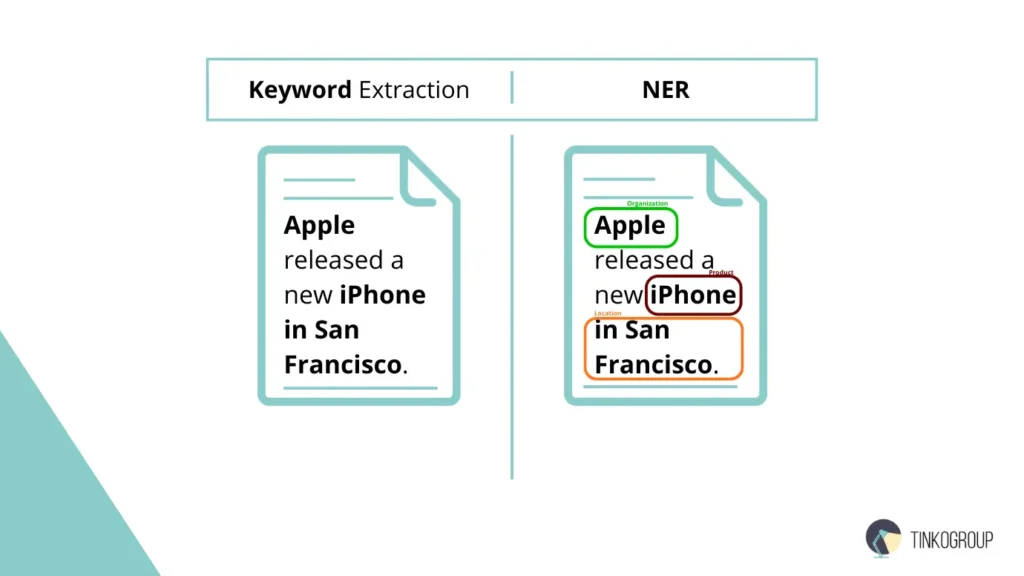
NER adds context and structure to the extracted information. For example, after NER processing, the same phrase is converted into structured data: Organization — Microsoft, Product — Windows, Location — San Francisco. Such information becomes suitable for analytics, knowledge graph construction, media monitoring, AI training data preparation, and other natural language processing applications.
An important aspect that distinguishes NER from simple keyword extraction is its ability to work with ambiguity and context. If a word has different meanings, NER takes into account the surrounding words, the grammatical structure of the sentence, and even previous sentences to correctly classify the entity. In contrast, keyword extraction selects a word based only on frequency or statistical significance, without analyzing its semantic role.
NER is also important for integration with other NLP techniques. It is used as the foundation for sentiment analysis, topic modeling, and text classification, allowing systems to analyze not just words, but meaningful elements of text and their relationships. In business, this translates into the ability to automatically track mentions of companies, products, or key events. In medicine, it can be used to identify diseases, medications, and procedures. In the legal field, it can be used to identify parties to contracts, amounts, and deadlines.
Thus, the difference between NER and general keyword extraction lies not only in accuracy, but also in the level of text comprehension. Keyword extraction answers the question “what is the text about,” while named entity recognition answers the question “who, what, and where is mentioned in the text,” turning words into structured entities ready for analysis and use in any named entity recognition services or natural language processing applications.
NER vs Other NLP Techniques
Now that we understand what named entity recognition is, it is important to consider how NER differs from other NLP techniques and why it is sometimes indispensable. Beginners often confuse NER with sentiment analysis or text classification, but these methods solve completely different problems.
NER vs Text Classification
Text classification is used to assign a category to an entire document. For example, a news article can be classified as “finance,” “politics,” or “technology.” This method is useful for sorting documents, but it does not provide information about specific entities mentioned in the text.
Example: “Microsoft has opened a new office in Berlin to expand its cloud services.”
- Text classification: Business/Technology
- NER: Organization — Microsoft, Location — Berlin
In other words, if an analyst wants to compile a list of all the companies mentioned in thousands of documents, text classification is powerless. This is where named entity recognition in machine learning comes in handy, as it can identify entities and classify them.
Another nuance: NER can work at the level of individual sentences or even phrases, while classification looks at the entire text. This allows data to be integrated with knowledge graphs or other analytics systems.
NER vs Sentiment Analysis
Sentiment analysis evaluates the emotional tone of a text: positive, negative, or neutral. This is useful, for example, for monitoring reviews or social media.
Example: “I am disappointed with Apple’s new product update.”
- Sentiment analysis: Negative
- NER: Organization — Apple
As you can see, NER performs a different task here: it highlights the Apple company, not the author’s opinion. These methods often work in tandem: first, NER highlights entities, and then sentiment analysis helps to understand how they are discussed in the text.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

NER vs Topic Modeling
Topic modeling is a method that identifies hidden topics in large text arrays. It is useful if you need to understand what thousands of documents are about, but it does not provide specific information about people, organizations, or places.
Example: A news corpus may reveal topics such as “artificial intelligence,” “electric cars,” and “robotics.” NER allows you to understand which specific companies or people are mentioned: Tesla, Elon Musk, Berlin.
This approach is especially important for natural language processing applications, where data needs to be structured so that it can be used in analytics or to build AI training data for machine learning.
When and Why You Need NER Specifically
NER becomes necessary in cases where you need to structure information at the entity level, rather than simply understanding the general meaning of the text.
Examples of use:
- Automatic monitoring of news and media: tracking mentions of companies, politicians, or countries (named entity recognition in AI).
- Chatbots and customer service: recognizing names, addresses, and account numbers for correct processing of requests (named entity recognition services).
- Analytics and market research: extracting companies, products, currencies, and key events from financial reports or press releases (entity extraction).
- Preparing AI training data: creating annotated datasets for training machine learning models (named entity recognition annotation).
It is important to understand that NER does not replace other NLP techniques, but complements them. For example, the combination of NER + sentiment analysis allows you to not only understand who is mentioned in the text, but also how they are talked about. This provides much more valuable insights than each method separately.
Small comparison table (expanded):
| NLP Technique | Main focus | Example | Practical application |
| NER | Identification and classification of entities | Tesla (Organization), Berlin (Location) | Analitic automatization, entity extraction, preparation for the AI training data |
| Text Classification | Text category | “Finance News” | Document organization, content filtering |
| Sentiment Analysis | Emotions in the text | “Positive opinion about Samsung” | Monitoring feedback, analyzing customer sentiment |
| Topic Modeling | Main topics | “AI, electric vehicles, robotics” | Reviewing large amounts of text, identifying trends |
Use Cases & Industries
Now that we have figured out what named entity recognition is and how it differs from other NLP techniques, it becomes clear that these technologies can be applied in virtually any field where large amounts of text information are processed. NER allows you to convert “raw” text into structured data that can be analyzed, visualized, and used for decision-making.

Business & Finance
The financial sector works with huge flows of information: news, company reports, press releases, social networks, and analytical publications. The use of named entity recognition in NLP allows for the automation of this data analysis.
Example: An investment analyst receives hundreds of news items every day. Traditional manual analysis is impossible — there is too much information. With the help of NER, the system can:
- automatically identify companies (organization);
- recognize stock exchange tickers (e.g., NASDAQ: AAPL, NYSE: TSLA);
- identify currencies (entity extraction);
- identify key events and dates (date).
Moreover, named entity recognition in machine learning allows data to be linked to knowledge bases and historical data, enabling analysts to track the dynamics of mentions and make predictions based on AI training data.
A real-life example: in the news story “Apple increased its revenue by 15% in euros for the second quarter of 2025,” NER highlights Apple (Organization), EUR (Currency), and the date, turning the news story into a structured data set for further analysis.
Healthcare
Medicine is one of the most demanding fields in terms of text processing accuracy. Electronic medical records, doctors’ reports, scientific publications, and clinical trial data contain complex terms.
With named entity recognition in AI, you can:
- automatically recognize diseases (disease);
- identify drugs and their dosages (drug);
- extract personal patient data (person, location) for anonymization.
Example: patient record: “The patient has been prescribed metformin for type 2 diabetes, follow-up examination in three months.”
NER highlights:
- metformin → Drug
- type 2 diabetes → Disease
- follow-up examination → Date
This allows not only to create knowledge bases and AI training data, but also to support decision support systems in medicine. Ensuring high dataset quality is crucial for medical AI to avoid life-critical errors. For example, algorithms can automatically match symptoms with known diseases, speeding up diagnosis.
In addition, named entity recognition services are used to monitor scientific literature and clinical studies, helping researchers find relevant data without having to read thousands of articles manually.
Customer Service & Chatbots
In customer service, the speed and accuracy of request processing directly affect customer satisfaction. Modern chatbots and support systems rely on NER for:
- recognizing customer names (person);
- addresses and geolocations (location);
- account numbers, orders, identifiers (entity extraction).
Example: customer message: “Hello, my name is Alexey Ivanov, account number 987654, I want to change my delivery address to 12 Down Street.”
NER automatically highlights:
- John Smith → Person
- 987654 → Account Number
- 12 Down Street → Location
The system instantly understands that the customer’s data needs to be updated, without the involvement of an operator. This not only speeds up the work, but also reduces the risk of errors during manual processing of information.
In addition, named entity recognition annotation helps create annotated datasets for training models to correctly recognize even non-standard or abbreviated forms of names and addresses, which are typical for social networks and messengers.
News & Media Monitoring
Journalism and PR actively use NER to monitor mentions of events, people, and countries in huge volumes of text.
Example: an analytics company processes thousands of articles about international elections. Using named entity recognition in NLP, it identifies:
- Participants (Person)
- Locations (Location)
- Events (Event)
This makes it possible to quickly compile reports on who is mentioned and where, track mentions of brands, politicians, or companies in the media, and identify trends and crisis signals.
A real-life example: in the article “French President meets with EU leader in Paris to discuss climate initiatives,” NER identifies:
- French President → Person
- EU leader → Person
- Paris → Location
- Climate initiatives → Event
This makes news monitoring fast, accurate, and ready for analysis.
Legal & Compliance
The legal field requires maximum accuracy when working with contracts and regulatory documents. NER helps to:
- identify the parties to the agreement (Organization, Person);
- start and end dates of contracts (Date);
- important conditions and terms (entity extraction).
Example: contract: “Company X undertakes to pay Company Y $1 million by December 31, 2025.”
NER identifies:
- Company X → Organization
- Company Y → Organization
- $1 million → Currency
- December 31, 2025 → Date
The use of named entity recognition services and named entity recognition annotation allows lawyers to automate the analysis of hundreds of contracts, speeding up verification and reducing the risk of errors. This is especially important for corporate reporting, auditing, and regulatory compliance.
Challenges in Named Entity Recognition
Although named entity recognition is a powerful tool that allows unstructured text to be converted into structured data, in practice, the implementation of this technology faces a number of serious challenges. Each task in NER is unique: some models work with legal contracts, others analyze medical articles or social networks. Understanding these problems is important for creating truly effective named entity recognition systems in NLP that deliver accurate results and can be used in real-world applications.
The difficulties are related not only to the technical implementation of algorithms, but also to the very nature of language. Often, these challenges lead to common data labeling mistakes that significantly hurt model performance. People use words ambiguously, often change their style of speech depending on the situation, abbreviate words, and use slang. This creates an additional burden for systems that must correctly recognize entities and classify them. In this section, we will take a detailed look at the most complex aspects of NER, including word ambiguity, multilingual data, domain-specific features, and problems with “dirty” text.
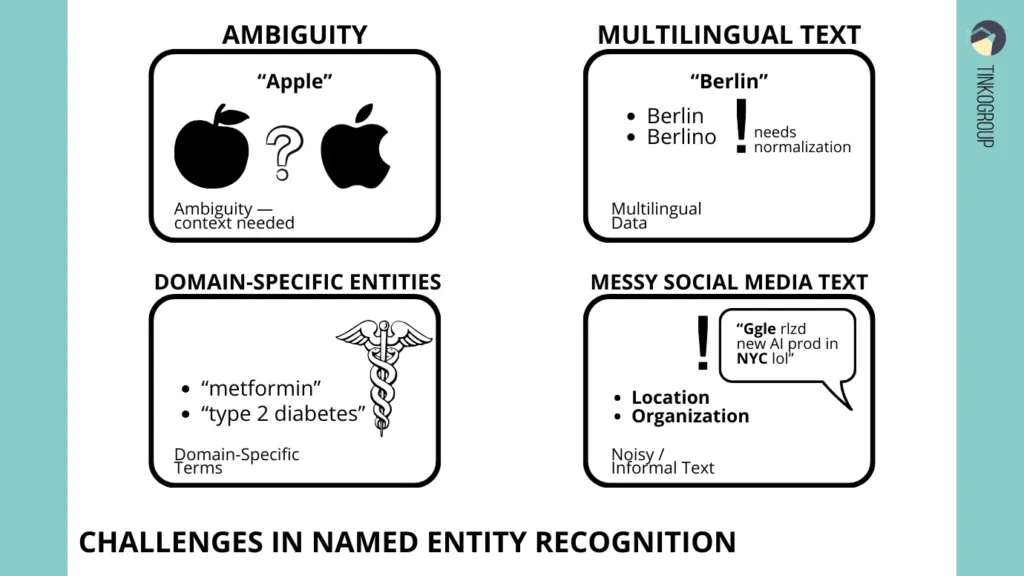
Ambiguity
One of the most obvious but also complex problems is word ambiguity. Let’s recall the example with “Apple.” For humans, the context usually suggests what is being referred to, but NER must analyze the sentence and surrounding text to correctly classify the entity. If the phrase “Apple introduced the new iPhone” appears in a document, the model must understand that it refers to the company, not the fruit. Errors in recognizing such words can lead to incorrect data in analytical reports, which is critical, for example, for financial analysts or lawyers who use entity extraction to build structured databases.
Ambiguity manifests itself not only in company names, but also in the names of people, places, or events. Sometimes a single word can refer to different categories depending on the context, and it is this contextual understanding that makes the task difficult. To solve this problem, contextual models and advanced named entity recognition models trained on large datasets are used to help the machine distinguish the meaning of words and associate them with the correct categories.
Multilingual Data
Modern texts often appear in different languages, and the same entity can have different spellings. For example, the capital of Germany can be referred to as “Berlin” in English, “Берлин” in Russian, or “Berlino” in Italian. This is a real challenge for a system that performs named entity recognition in AI. The model must correctly recognize these variations, combine them, and identify them as a single entity.
Multilingualism is particularly important in global business and international analytics. Companies that monitor news in several countries face the fact that the same organizations, people, or events may be mentioned in different languages. If a NER system does not take such features into account, the data will be fragmented, which reduces the value of natural language processing applications and complicates the work of analysts.
Domain-Specific Entities
The complexity increases even more when it comes to specific fields such as medicine or finance. Medical texts contain rare diseases, complex chemical names of drugs, abbreviations, and terms that are rarely found in ordinary corpora. Similarly, financial texts contain unique instruments, tickers, currency codes, and legal terms.
To accurately recognize such entities, named entity recognition models trained on specialized labeled data are required. Here, the participation of experts in named entity recognition annotation is critical so that models can learn to identify and classify these specific terms. Preparing such datasets for AI training data requires time and resources, but without it, the accuracy of the system remains low.
Spelling Errors, Abbreviations, Informal Text
An equally serious problem is working with texts that contain typos, abbreviations, slang, or emojis. Social networks, forums, and chats create “dirty” text that is difficult to process using standard methods. For example, in the message “Google released a new AI product in NYC,” the system must correctly recognize “Google” as a company and “NYC” as New York, despite the abbreviation.
Such data requires flexible models and the ability to perform contextual analysis. That is why named entity recognition services often use a combination of rules and deep learning to extract entities even in non-standard or abbreviated forms of text. As a result, such systems allow valuable information to be extracted from data streams that were previously considered too chaotic for automatic processing.
Future of NER
Named Entity Recognition is advancing at a rapid pace. Modern systems are no longer just a set of rules and templates: they learn to understand context, recognize complex entities, and work with texts of any length. The future of NER is linked to the integration of advanced artificial intelligence algorithms, large language models, and intelligent knowledge bases, which makes it possible to create systems capable of working in real time and with high accuracy.
Today, there are several key trends shaping the development of NER and its role in natural language processing applications. They concern how models are trained, how they adapt to specific domains, how they cope with minimal labeled data, and how they integrate with external knowledge sources for a deeper understanding of text.
Pretrained Large Language Models
One of the most significant achievements in recent years has been the use of pretrained large language models, such as BERT and GPT, for entity recognition. These models are trained on huge text corpora and are able to understand the context of words, which is critical for accurate entity extraction. For example, a GPT-based model can distinguish between “Apple” as a company and “apple” as a fruit based on the context of the sentence.
The use of such models significantly speeds up the development of named entity recognition models, as the system already has a basic understanding of language. Further training on specialized data—whether in finance, medicine, or law—improves recognition accuracy and makes the models applicable to real-world tasks, including the preparation of AI training data and integration into named entity recognition services.
Domain-Adapted NER Systems
The next area is the adaptation of NER systems to specific domains. Universal models are good for general text, but medical, legal, or financial documents require special configuration. Domain-adapted NER systems are trained on labeled data specific to a particular field, which allows them to recognize terms and entities that are not found in general corpora.
Example: a medical system trained on clinical notes can accurately identify diseases, drugs, and procedures, while a financial system can identify tickers, currencies, and contracts. Such adapted models make named entity recognition in machine learning a more accurate and reliable tool for analyzing professional texts, which is critical for creating high-quality natural language processing applications.
Zero-Shot & Few-Shot Entity Recognition
Traditional NER training requires large labeled datasets, which can be expensive and labor-intensive. However, modern zero-shot and few-shot entity recognition approaches allow the system to recognize entities even with a minimal number of examples or without any at all.
For example, if you need to highlight a new category of entities that was not previously in the training data, a GPT- or BERT-based system can use context and instructions to correctly classify the new entity. This opens up opportunities for the rapid implementation of named entity recognition services in new projects and areas, reducing the time required to prepare AI training data and making NER a flexible tool for business and research.
Integration with Knowledge Graphs
One of the most promising trends is the integration of NER with knowledge graphs, which link entities to each other and to additional information. This approach allows not only recognizing entities in text, but also understanding their relationships, context, and role in a specific situation.
For example, mentions of the company “Tesla” and the city “Berlin” in the news can be linked to information about Tesla factories, news about deliveries, and events in Germany. This turns simple entity extraction into a powerful tool for analytics, forecasting, and decision-making. Integration with knowledge graphs is especially important for corporate systems, financial analytics, and media monitoring, where deep semantic text processing is required.
Conclusion
Named Entity Recognition plays a fundamental role in today’s world of natural language processing applications. As we have seen, it is not just a word extraction technology, but a complex system that helps computers understand text at the level of entities: people, organizations, places, dates, and many other categories. NER allows business, medicine, journalism, law, and many other industries to extract valuable information from vast amounts of data, turning unstructured text into structured and easily analyzable data sets.
The application of named entity recognition in AI, named entity recognition in machine learning, and specialized named entity recognition models opens up opportunities for automating news monitoring, financial report analytics, medical document processing, and building intelligent decision support systems. Even in conditions of ambiguity, multilingual data, domain-specific terms, and “dirty” text, modern approaches, including pretrained large language models, domain-adapted systems, zero-shot and few-shot methods, allow for high accuracy and reliability of recognition.
Today, NER is the basis for creating complex NLP techniques and named entity recognition services that integrate with knowledge graphs and allow you to see the relationships between entities, analyze context, and make decisions based on structured information. Without this technology, many modern natural language processing applications would be impossible.
If you want to implement cutting-edge solutions in your company and take advantage of NER for text analysis, business process automation, or AI training data preparation, the Tinkogroup team is ready to help. Our specialists develop customized named entity recognition services, train models on specialized data, and integrate them into existing business systems so that you can get the most out of text analysis.
Use NER as the foundation of your data strategy — from media and customer query monitoring to complex analytics and forecasting. With Tinkogroup, you can implement named entity recognition in NLP as effectively as possible, turning large amounts of text information into real business value.
What is the main difference between Keyword Extraction and NER?
While keyword extraction identifies important words based on frequency or significance, NER goes further by classifying those words into specific categories like Person, Organization, or Location. NER understands the semantic role of a word within its context, whereas keyword extraction simply highlights that the word exists in the text.
Can NER handle words with multiple meanings (ambiguity)?
Yes, modern NER systems use contextual analysis to distinguish meanings. For example, a system can determine if “Apple” refers to the technology company or the fruit by analyzing surrounding words and sentence structure. Advanced models like BERT and GPT have significantly improved accuracy in resolving such ambiguities.
How do Large Language Models (LLMs) improve NER performance?
Traditional NER relied on rigid rules, but LLMs like GPT or BERT understand deep language patterns and context. This allows them to perform zero-shot learning, meaning they can recognize new types of entities (like specific legal terms or new product names) without requiring massive amounts of manually labeled training data. This makes NER faster to deploy and much more flexible for complex business tasks.


