

The increasing availability of raw data from various sources (such as the Internet of Things (IoT), social networks, and sensors) forces researchers and practitioners to seek innovative approaches to their analysis. Using an unlabeled dataset reduces labeling costs and allows the model to detect hidden patterns that traditional strategies may miss.
Below, our experts will deliver various methods and practices that allow you to make the most of unlabeled data in machine learning (ML) and discuss what modern technologies should be used to process it.
Why use unlabeled data?
It is important to understand data volumes are growing exponentially. Every day, we create huge amounts of information, which often remain unlabeled despite their considerable volume. By exploring the potential of machine learning unlabeled data, we can find valuable solutions and significantly reduce processing costs.
Unlabelled data can be found in many sources: social networks, user feedback, IoT sensors, medical records, videos, and images. It is assessed that up to 90% of all data in existence today is unlabeled. This vast amount of information contains many useful patterns and relationships that can become the basis for new innovations. Using unlabeled data allows us to detect these patterns without the need for significant labeling efforts.
For instance, in the field of health care, the analysis of unlabeled medical records can help discover new ways to treat or diagnose diseases. In business, data collected from customer feedback can provide helpful information about consumer behavior that allows you to optimize products and services according to their needs. By studying this data, we can open new markets, improve the efficiency of processes, and even predict future trends.
Benefits of using unlabeled data
As businesses seek innovative ways to utilize data, unlabeled datasets have emerged as a practicable solution. This approach reduces costs and enhances adaptability and model performance in dynamic environments.

Cost efficiency
Conditions for the quality of data labeling may require significant efforts on the part of experts specializing in a certain area. For example, in the case of images and videos, their accurate labeling requires considerable time and money, especially when it comes to large amounts of information. Implementing machine learning using unlabeled data can decrease these costs because there is no need to create separate labels for each data item.
Quick adaptation
Using unlabelled data also allows businesses and organizations to adapt more quickly to changing conditions. In times of rapid technological change, quickly responding to new challenges is a critical competitive advantage. With technologies such as untrained learning and transfer learning, companies can analyze and use unlabeled data to train models without the need for large amounts of manual labeling.
Enhanced learning
Moreover, the use of unlabeled data allows for the expansion of the capabilities of model training. They can learn from a variety of data, which allows for creating more flexible models that can adapt to unstable environments. This is significant for tasks where accuracy and speed are critical, such as financial markets or natural language processing (NLP).
Methods to use unlabeled data in machine learning
Unlabelled data in machine learning offers many options for building robust models. Because data labeling resources are often limited, researchers and practitioners are turning to various techniques that efficiently use raw information. Let’s analyze several tactics that help maximize the potential of unlabeled data. These approaches align closely with current data annotation trends, where hybrid strategies combining unlabeled data, automation, and selective human input are reshaping how AI models are trained at scale.
1. Semi-supervised learning
This learning integrates elements of supervised and unsupervised learning, making it ideal for working with large amounts of unlabeled data alongside a small number of labels. This technique allows models to be trained on available labels while using unlabeled data to improve accuracy.
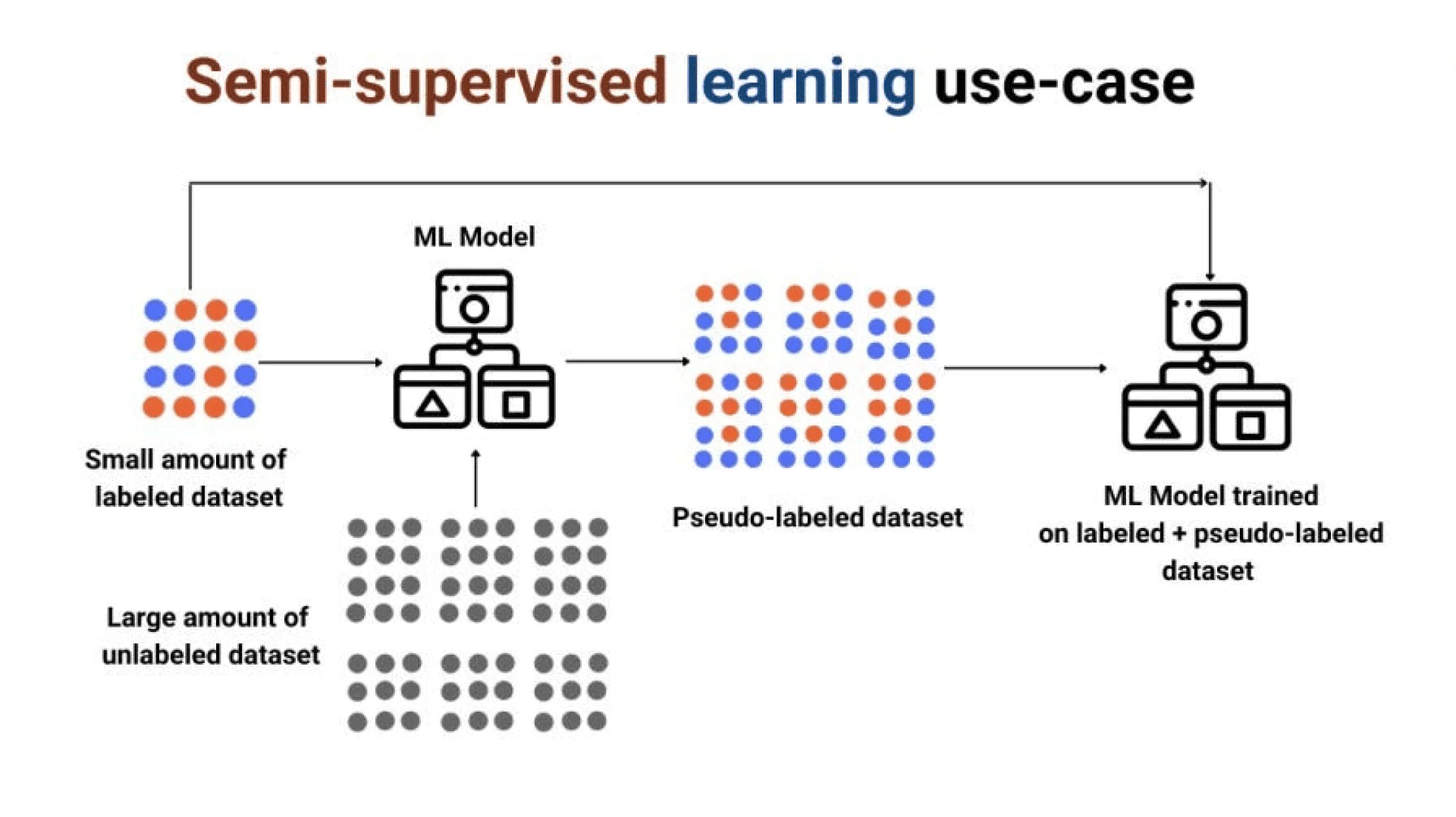
For instance, in classification tasks, a model is first trained on a small amount of labeled data and then uses unlabeled data for further refinement. This allows the model to detect patterns and structures that may be missed if training is based only on labeled data.
This approach is often used in areas such as image and natural language processing, where large amounts of data may be available, but labeling them is an expensive and time-consuming process. Semi-supervised learning helps reduce labeling costs while maintaining high-quality models.
2. Unsupervised learning
Unsupervised learning is one of the most common techniques for using unlabeled datasets. In this case, models are trained on raw information without labels. The primary purpose is to determine structures and patterns in the data. Popular algorithms of this method include clustering and associative analysis.

For example, clustering allows you to group similar data together, which can be helpful for market segmentation or user behavior analysis. Unsupervised learning is a powerful tool, especially in cases where labels are difficult or impossible to obtain, and can form the basis for further partially or fully labeled learning.
3. Self-supervised learning
Self-supervised learning is a relatively new method involving using unlabeled data to create labels during learning. In this case, the model first performs predictive tasks, creating new labels based on its predictions. This procedure allows the model to learn from its mistakes, leading to continuous improvement.
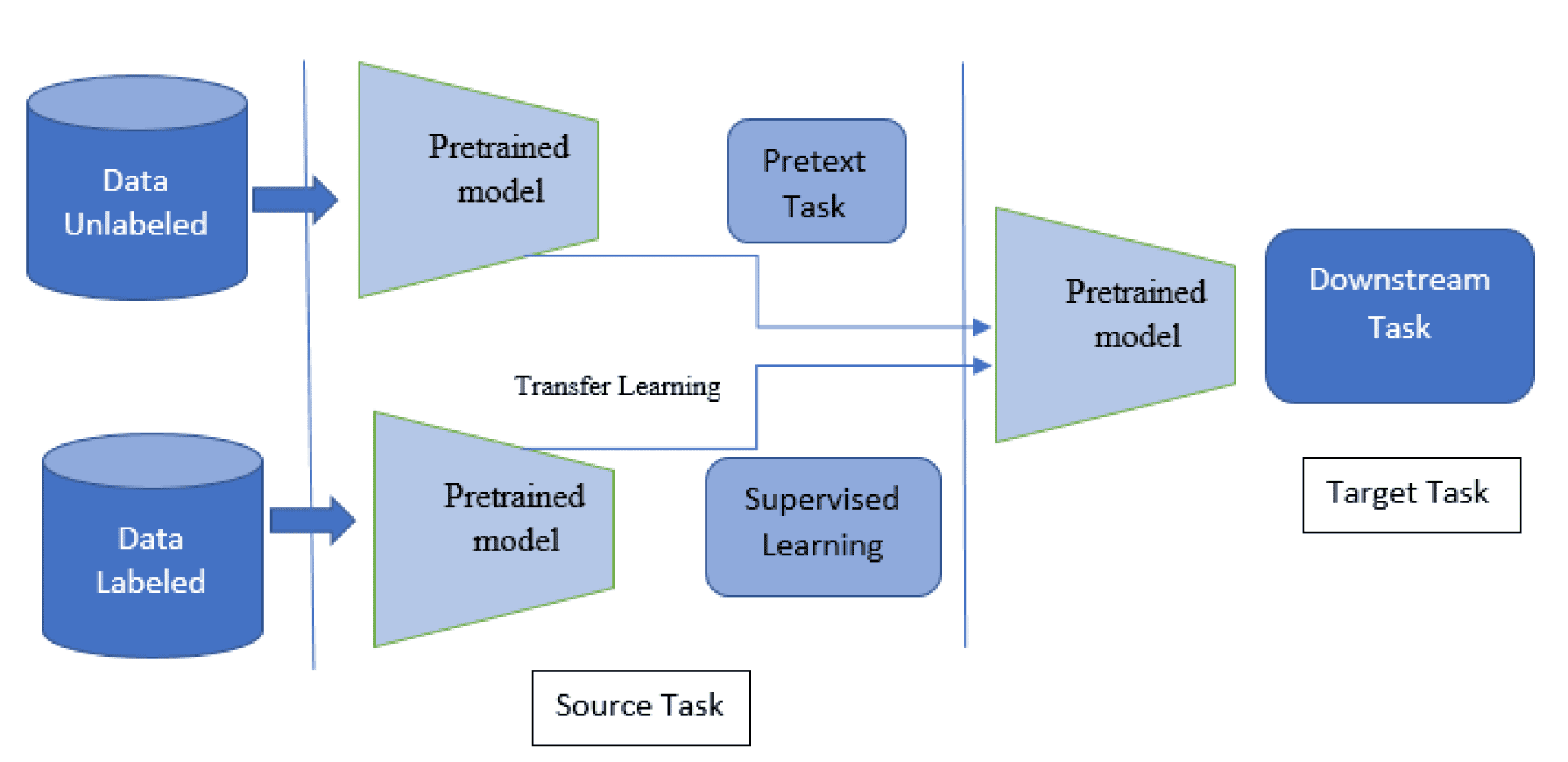
Self-supervised learning is beneficial in the context of natural language processing and computer vision. For example, a model can learn from image data, generate signatures, or detect objects. This method helps the model better understand data structures and improves its accuracy over time without significant labeling costs.
4. Active learning
This learning is a strategy that allows the model to determine which unlabelled data should be labeled independently. During training, the model can select the most uncertain samples and request labeling for them. This allows you to focus your efforts on those data that have the greatest impact on improving the model’s accuracy.
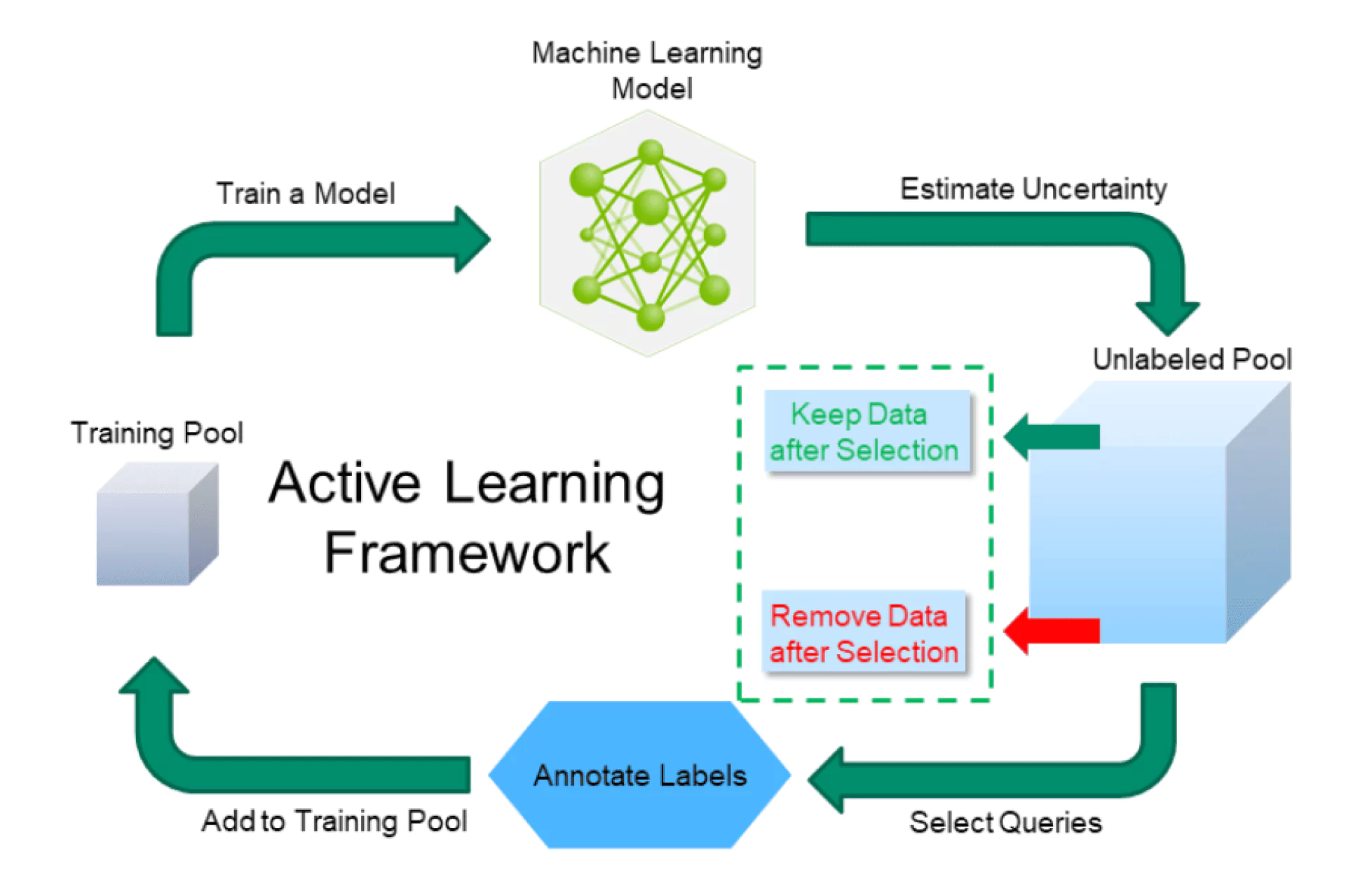
This approach is efficient in situations where labeling is an expensive or time-consuming process. Instead of labeling the entire data set, active learning reduces the number of samples needing labeling while maintaining the high quality of the models. In the field of medical research or financial analysis, where data quality is critical, active learning can significantly streamline the model-building process.
Challenges of working with unlabeled data
In particular, difficulties may arise in collecting, processing, analyzing, and integrating this data into the model. Let’s check some fundamental issues that can occur when working with unlabeled data.
Lack of context
When data is unlabeled, it becomes difficult to understand its meaning and how to use it in specific situations. This can lead to misinterpretation of information, as the models may not have clear instructions about what patterns they should detect.
For example, in the case of unlabeled images, the algorithm can detect features with no real meaning without the relevant context. As a result, a model can produce useless or misleading results if they have not been trained on the correct data.
Instability of models
Training on an example of unlabeled data in machine learning often leads to unstable models. Because the data can be diverse in its content, models can be trained on patterns without a real connection to the task. This can lead to a situation where the model does a good job on some data but has poor accuracy on others.
This instability is particularly critical in applied industries such as healthcare or financial analysis, where the accuracy of decisions can have serious consequences. Thus, it is essential to provide additional verification and validation methods to avoid false conclusions. In many teams, these problems later appear as clear signs that model training needs improvement, even though data volumes and tooling may initially seem sufficient.
Complexity of data processing
Handling unlabeled data is another challenge. Often, this data contains noise, inaccuracies, or anomalies that can distort the results. Compared to labeled data, which can be cleaned and prepared, unlabeled data requires more attention to preprocessing.
Additional time must be spent cleaning, normalizing, and transforming the data to prepare it for training. This process can be time-consuming and requires deep knowledge of data processing, which may not be available to many companies or organizations.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Lack of quality control
With labeled data, there is usually a clear quality check. Usually, the tags undergo a verification process, which helps ensure the data is highly accurate. However, in the case of unlabeled data, there is no such verification mechanism, which may lead to the use of poor-quality information.
This can be especially necessary when data accuracy is vital, such as in medical research or financial analysis. Incorrect data can lead to serious consequences, including financial loss or even a threat to life.
Selection of optimal learning method
Choosing a suitable method for training on an unlabeled dataset is also a challenge. There are many different approaches—from semi-supervised to unsupervised learning—and choosing one can affect the results. The wrong choice can lead to insufficient model performance or its incompatibility with specific tasks.
Best practices for employing unlabeled data
Using unlabeled data in machine learning can be a powerful tool for improving models and optimizing processes. However, to be successful in this area, it is essential to follow certain best practices. Below, we focused on critical guidelines to help you make the most of unlabeled data.

1. Understanding data
Before starting work with unlabeled data, conducting a deep analysis of it is necessary. Understanding the structure, type and volume of data is a critical step. It is recommended to perform a preliminary study that includes examining the data distribution and detecting anomalies and noise. This analysis will allow you to understand which machine-learning techniques may be most effective for your particular data set.
Employing statistical tools to describe the data can give you insight into which patterns are present in the data and which are not. This allows you to form more reasonable hypotheses for further training.
2. Pre-processing of data
High-quality data pre-processing is the key to successful work with unlabeled data. It includes cleaning, normalization, dimensionality reduction, and noise removal. The costs of this stage are often justified, as the quality of the input data directly affects the model’s results.
Different data visualization methods, such as scatter plots or histograms, are recommended to assess how the data can influence learning. This will allow you to identify potential problems at an early stage.
3. Using validation methods
When working with an unlabelled data example, it is essential to implement validation systems to help estimate the model’s performance. One approach is to split the data into training and test sets, which allows you to test how well the model handles new data.
Another strategy is to use cross-validation, which allows you to test the model on different subsets of the data, providing a more reliable estimate of its performance. This helps avoid overtraining when a model performs well on training data but fails to generalize on new data.
4. Cooperating with experts
Bringing in experts in your field can significantly enhance the quality of your work with unlabeled data. They can help identify important characteristics of the data, as well as provide knowledge that can be useful in choosing training methods.
Experts can also provide valuable suggestions on interpreting simulation results and help formulate questions to be answered. Cooperation with experts can reduce the risk of errors and improve the quality of decisions made.
5. Improving continuously
The modern world of data is dynamic, so it is crucial to improve models constantly. Use new, unlabeled data to update and refine your models as data and context change.
Always keep an eye out for new technologies and techniques in machine learning that can improve your results. Regularly evaluating and improving your approach will allow you to remain competitive in the market.
Tools and frameworks for using unlabeled data
When working with unlabeled data, various tools and frameworks can help facilitate various tasks. Below is a list of some popular tools and frameworks:
- Unsupervised learning frameworks: scikit-learn, TensorFlow, PyTorch
- Semi-supervised learning libraries: LabelProp, MixMatch, FixMatch
- Data preprocessing tools: Pandas, NLTK/spacy
- Data annotation and management tools: Labelbox, Snorkel
- Visualization tools: Matplotlib/Seaborn, Plotly
At Tinkogroup, we used the Labelbox tool for the labeling project, which included a series of image annotation tasks.
We focused on precisely identifying and labeling various objects within images. These objects comprised buildings, trees, cars, poles, containers, roofs, and empty lots. The task required careful attention to detail to ensure accurate labeling of each object, supporting various applications such as machine learning and computer vision models. This comprehensive approach aimed to enhance the quality of the annotated data and improve the effectiveness of subsequent analyses and applications.
Conclusion
Unlabeled data delivers new possibilities for machine learning, changing how we approach analysis and modeling. Various methods allow us to obtain valuable information from large volumes of raw data. This reduces the cost associated with markup and facilitates the creation of more adaptive and accurate models that can learn from unpredictable situations.
Join us in exploring the outstanding potential of unlabeled data in machine learning. Together, we can discover innovation in your projects. Contact us to create solutions that will transform the market!
FAQ
What is the difference between labeled and unlabeled data?
Labeled data has annotations or categories that describe the data points. Unlabeled data lacks annotations, where algorithms identify patterns or structures without prior guidance. The key difference is that labeled data is structured and informative, while unlabeled data is raw and unprocessed.
What is unlabeled data in machine learning?
Unlabeled data refers to data without accompanying labels or annotations, including various formats like images or text. Unlabeled data can also be used in semi-supervised learning to improve the performance of machine learning models by combining it with labeled data.


