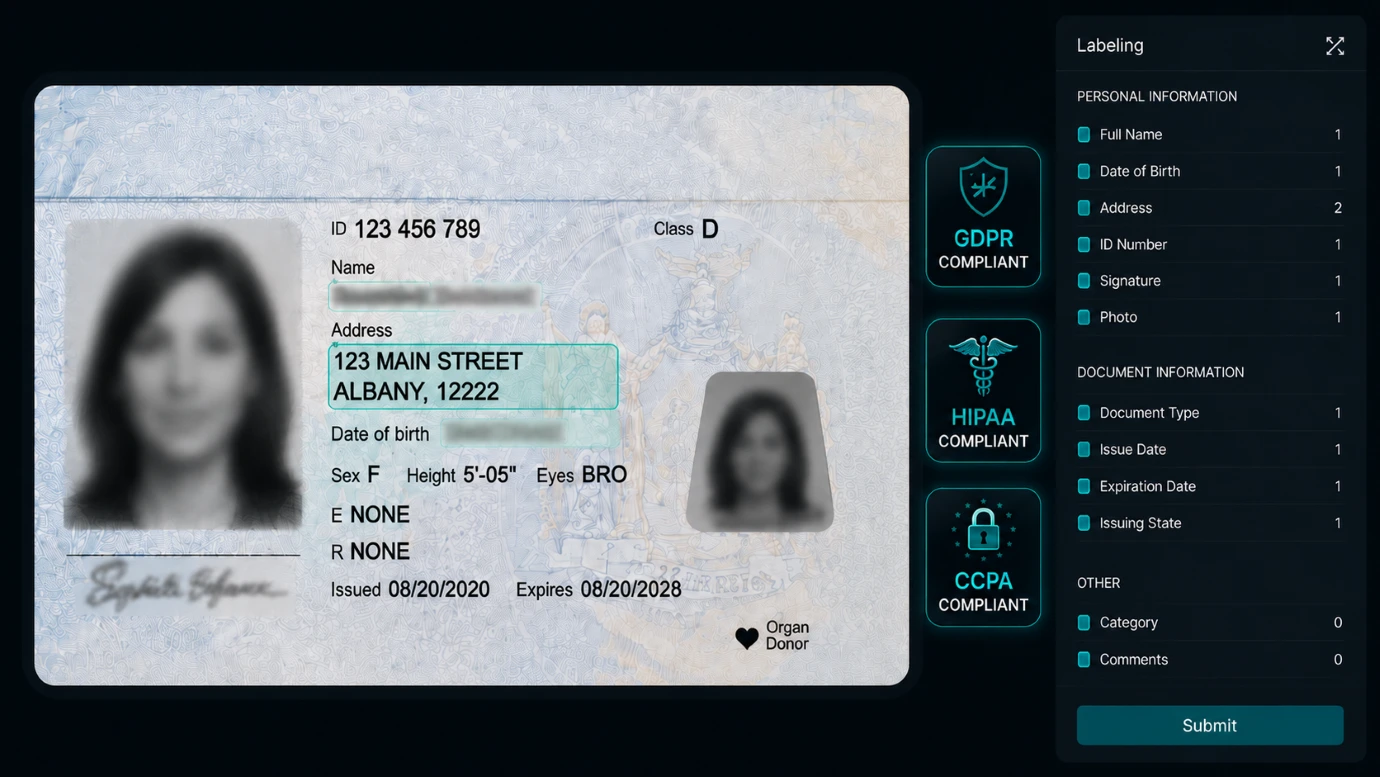

AI data security begins long before a model goes live. At the annotation stage, raw human data — faces captured in public spaces, medical scans tied to patient histories, home addresses, and financial transactions — passes through multiple hands, devices, and environments. The more capable the model, the more sensitive the data it requires. And the consequences of exposure at this stage can be devastating. Unfortunately, this issue is not just a theoretical concern.
Modern companies heavily invest in model performance and computing power, but they often underestimate one critical thing – data annotation security. This stage hands raw, unfiltered information to human annotators for labeling – and significantly increases AI data security risks. Each dataset passes through multiple hands, devices, and environments, which creates numerous opportunities for a breach.
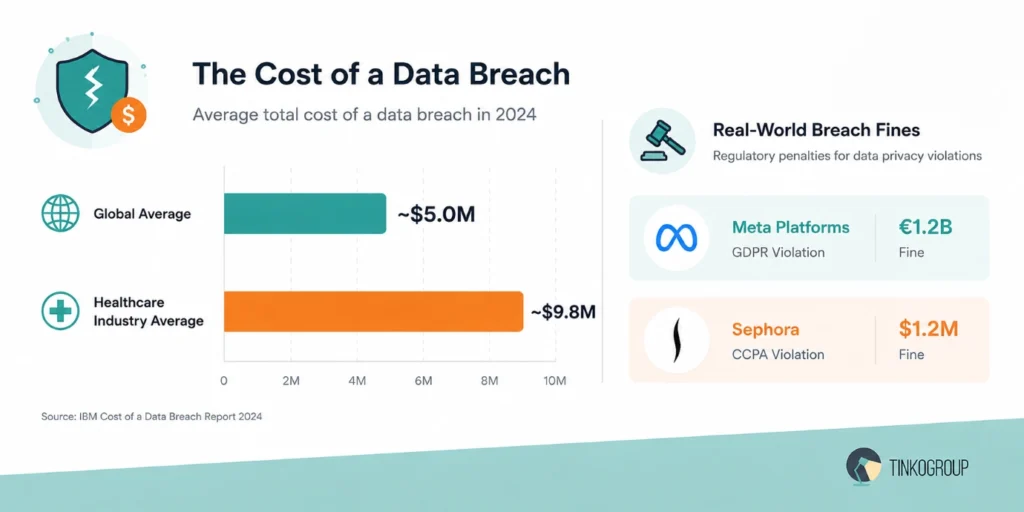
The cost of this oversight can be high. According to industry reports, the global average cost of a data breach is nearly $5 million, and the loss in healthcare is even higher. A single leak in the labeling process can trigger regulatory investigations and lawsuits and even force companies to reject entire models if they trained them on compromised data.
Robust AI data security is no longer just optional paperwork. Today, it is the firewall that protects your business and your customers. In this article, we unpack the regulatory minefield, compare annotation models, explore core policies and technical safeguards, and explain why expert teams make the difference for AI and data security.
Understanding the Rules Behind AI Data Security
If you are developing AI that uses personal data, you must know and adhere to international regulations. These laws are not optional. It is a requirement for data privacy in machine learning. The same rule applies to outsourced data labeling – your vendor needs to demonstrate operational compliance with the specific statutes governing your data.
Here is a breakdown of the “alphabet soup” that defines AI data security:

GDPR – the Right to Be Forgotten
GDPR (General Data Protection Regulation) remains the standard for global privacy. Any organization must follow GDPR compliance in AI for sensitive data protection. One of its unique requirements is the “right to be forgotten.” It means that when someone requests deletion of their personal data, companies must remove data from the entire lifecycle – not just delete it from storage but also from training pipelines and annotated datasets. GDPR also enforces two other critical principles:
- Data minimization. AI teams must prove they are only collecting the specific data necessary for the model’s function.
- Biometric protections. There are restrictions on processing sensitive categories like facial recognition data or fingerprints.
Fines are real. In 2023, Meta paid €1.2 billion for unlawful data transfers. It shows how a single oversight in the labeling process can be catastrophic.
CCPA – Consumer Privacy
In the US, the California Consumer Privacy Act (CCPA), together with the CPRA, sets a standard for data protection. These laws give people the right to access their data, delete it, and forbid the sale or sharing of it.
AI developers face real risks when they hire third-party labeling platforms. It’s actually data sharing when you send datasets to external vendors. Companies can face serious fines or even lawsuits if there are no clear access controls, tracking systems, and solid contracts in place. All annotation workflows must be fully traceable and allow data to be quickly removed from all systems when required.
For example, Sephora was fined $1.2 million under the California Consumer Privacy Act (CCPA) for not properly informing users that their data was shared with third parties. The company also failed to give customers a clear option to opt out of this data sharing. As a result, regulators took action and issued a penalty.
HIPAA – Medical Data Protection
HIPAA (Health Insurance Portability and Accountability Act) is the strictest standard for medical AI. Projects that use medical records, images, or patient data must follow strict rules for Protected Health Information (PHI). HIPAA-compliant annotation vendors need to sign Business Associate Agreements, but paperwork is only the first step.
True compliance also means using encrypted systems, keeping access logs, and working in secure environments. If even one medical image leaks during labeling, it can trigger investigations, penalties, and costs millions.
One important detail many companies overlook is the difference between having a certificate and actually following the rules in daily work. A vendor may have an ISO certificate, but that doesn’t automatically mean their processes are secure. Real compliance is the readiness to show their workflows and pass an audit at any time.
Crowdsourcing vs. Managed Teams – What Are the Risks?
When you begin a data annotation project, you need to decide who will work with your data. There are two options – crowdsourcing or managed teams. Both options appear similar on the surface, but their security risks are actually quite different.
Crowdsourcing: Speed Without Control

Crowdsourcing platforms make labeling faster and more affordable by distributing tasks among anonymous workers worldwide. This approach works well for low-risk projects, for example, tagging public images or sorting generic content. However, it can quickly become a serious risk when handling sensitive data.
The core vulnerability is loss of visibility and control. Annotators are usually people you do not know, working from their own laptops, home networks, and often public Wi-Fi. You cannot be sure their devices are secure, and you cannot stop them from screen recording or copying data. It is also difficult to know exactly who is accessing your information. Occasionally, several people may use the same account or device.
Legal risks are the worst. Data can end up in countries with weak privacy protections – it’s a GDPR or CCPA violation. And if a breach happens, you will not be able to hold an anonymous annotator responsible.
In 2023, the investigation revealed that contractors working on AI data labeling for OpenAI accessed sensitive data through remote systems and secure connections. Even though access was controlled, the report highlighted that contractors worked in distributed environments and exposed sensitive data to human annotators during the labeling process.
In 2025, another case occurred. Scale AI, a large data-labeling company working with hundreds of thousands of contractors, accidentally exposed sensitive client information through publicly accessible Google Docs. Some documents tied to projects for companies like Meta and Google were left open in a way that allowed anyone with a link to view or even edit them.
Contractors also reported seeing private details about other workers, including email addresses and performance notes, in these shared files. This incident raised serious concerns about how teams manage crowdsourced annotation and how easily sensitive information can leak when teams fail to enforce strict access controls.
Managed Teams – AI Data Security
Managed annotation teams work differently. Such a team can be part of your company or a hired vendor. These teams operate in a secure and controlled setting.
Verified annotators sign a strict Non-Disclosure Agreement (NDA) before accessing any data. They work on secure systems, in controlled offices, or through protected remote setups. Each person only sees the data needed for their task, and the system tracks and monitors all activity.
This setup ensures full accountability. You can see who worked on your data, when they accessed it, and what they did. If any issues arise, you can trace back every step.
Crowdsourcing is less expensive at first, but the risks usually outweigh the savings. For projects with personal, medical, or proprietary data, only managed teams can guarantee data security and privacy.
Core Pillars of AI Data Handling Policies
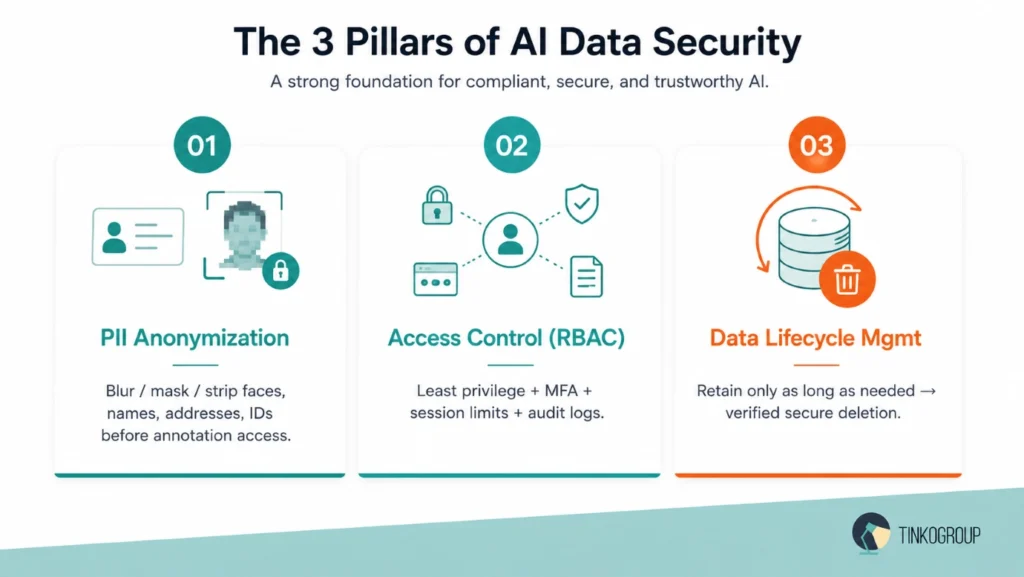
There is no tool or policy you can use to protect your data. You need to build a secure data labeling system based on three pillars – PII anonymization, access control, and data lifecycle management.
PII Anonymization – The First Line of Defense
Personal information must never reach an annotator in its raw form. That’s the foundational rule of AI data security. Annotation teams must apply PII anonymization before granting any annotator access to a dataset.
- Preprocessing must strip or obscure personally identifiable information, such as faces, license plates, names, and contact details.
- Teams must blur or mask sensitive areas in images and video datasets.
- Automated tools must scan and remove names, emails, phone numbers, and other identifiers from text data.
Anonymization extends beyond the obvious cases. Background faces, reflections, or indirect identifiers – such as job titles combined with locations – can still expose individual identities. This is why annotation teams must treat PII anonymization as an ongoing process, running regular checks and updating rules as datasets evolve.
This discipline cuts exposure significantly. Even when a dataset is compromised, investigators cannot trace the information back to specific individuals.
Access Control – Limited Exposure
Not everyone on a project needs full access to all data. Actually, they should not have it.
Role-based access control (RBAC) makes sure each person only sees the data needed for their specific task. For example, an annotator labeling traffic signs does not need access to full video footage or GPS coordinates. A reviewer may need to check labels but not download raw files. This principle is called the “least privilege” approach. It greatly lowers the chances of accidental or intentional data exposure. It also limits the damage if an account is compromised.
Strong access control also requires secure logins, multi-factor authentication, session limits, and detailed audit logs. You must be able to track every action, be it viewing, editing, or exporting. It allows teams to quickly spot unusual behavior.
Grant access only when needed and revoke it once tasks are complete. Old or inactive accounts are a common security risk, but teams can prevent them.
Data Lifecycle Management – Control from Start to Finish
Data security does not end when annotation is finished. Often, the biggest risk comes from data that is no longer in use but is still stored somewhere.
A clear data lifecycle policy explains how long teams keep data, where they store it, and how they delete it. The objective is straightforward – data should exist only as long as teams need it. This means teams must limit storage time and avoid duplicating data. Teams must account for all backups and exports. Once a project is complete, teams must securely remove sensitive data from all systems.
And it’s important to verify this deletion. It’s not enough to simply remove data if someone can still recover it. Professional workflows often include confirmed deletion processes or certificates to demonstrate that teams have fully erased the data.
Physical & Technical Security Measures
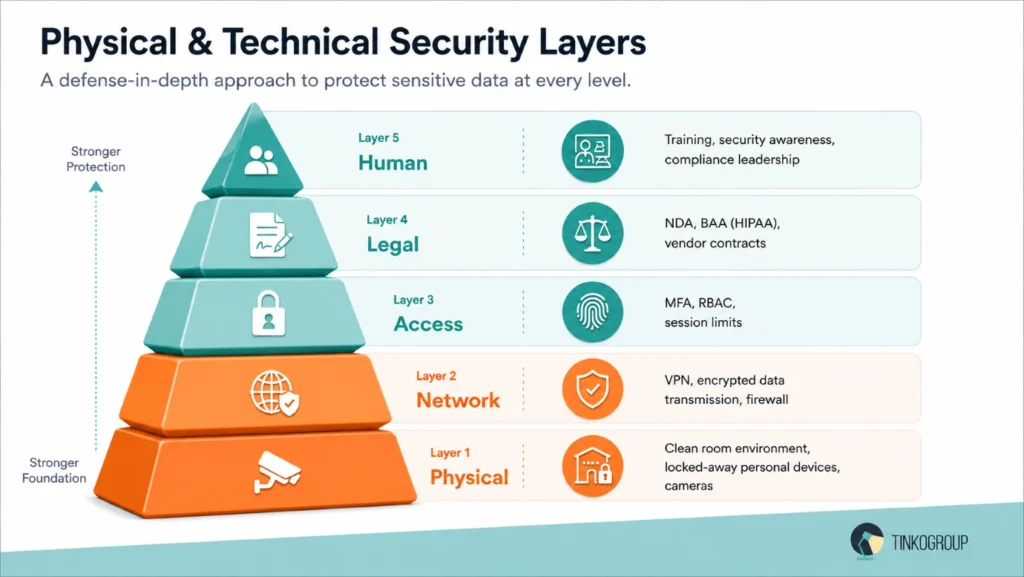
AI data security is not restricted to software and the AI data security policy. It also depends on the physical and technical spaces where annotation takes place. Even the best systems can fail if someone handles data in an unsafe workspace or sends it without the right protections. This is why strong security needs both digital and real-world measures.
Clean Room Environments for Sensitive Projects
Standard office security is insufficient for the most sensitive annotation work, such as government data, confidential medical records, and financial information. Annotation environments must have a high level of physical control.
The facility prohibits personal electronic devices. Teams should lock smartphones, tablets, smartwatches, and personal laptops in secure storage before annotators enter the work environment. They must also disable laptop webcams, block external storage connections, and monitor unusual activity.
This level of security may seem excessive for typical annotation projects, but it’s a standard for super-sensitive projects. Always think about the cost of a breach. If it exceeds the cost of implementing cleanroom protocols, the investment makes sense.
VPN and Encryption – The Baseline
For annotation teams working in managed but non-clean-room environments – which describes the vast majority of professional annotation operations – VPN and encryption form the technical baseline. Teams must encrypt all data transmission in transit between annotation platforms and annotator workstations using current cryptographic standards. Teams also must encrypt data at rest – stored on annotation servers, backup systems, or project management platforms – and properly manage the encryption keys.
Virtual private networks (VPNs) serve a dual purpose in network security. They encrypt network traffic to prevent interception, and they restrict access to annotation platforms to authorized network addresses. It means that if someone steals an annotator’s credentials, they cannot access the platform from an unrecognized device or location without also compromising the VPN credentials.
Organizations must enforce Multi-factor authentication (MFA) on all accounts with access to sensitive data, including annotator accounts. It may make logging in slightly less convenient, but it provides much stronger protection against stolen credentials, one of the most common causes of data breaches.
NDAs – The Legal Foundation of Trust
Non-disclosure agreements are the legal backbone of annotation security. Every individual who will have access to sensitive client data, from project managers to quality reviewers to annotation team leads, must sign an NDA before beginning work. These agreements must specify what information is confidential, what annotators may and may not do with the data, and the legal consequences of any violation.
A well-drafted NDA accomplishes several things simultaneously. It creates legal accountability for individuals who may treat data casually. It establishes a shared understanding of security obligations that signing reinforces. And in the event of a breach, it provides the legal basis for pursuing damages against responsible parties.
NDAs are also important for vendor-to-client relationships. Your annotation service provider’s NDA with you should explicitly cover data confidentiality, specify how data will be handled and destroyed, and include provisions for breach notification.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

The Human Factor – Expert-Led Compliance
Technology plays a critical role in AI data security, but it is not enough on its own. Even the most advanced tools depend on how teams use them. Most breaches trace back not to missing tools but to people who misconfigure or misuse them. This is why the human factor, especially expert leadership, is essential for true compliance.
Why Tools Alone Are Not Enough
Security tools follow rules, but only within the boundaries teams configure. Let’s take GDPR, CCPA, and HIPAA – these are complex regulations, and teams often interpret them incorrectly. Without the right expertise, it’s easy to make costly mistakes.
A well-known example is the 2023 Samsung case. Employees accidentally leaked sensitive internal data to external AI tools. The problem wasn’t the technology. It was a lack of clear guidance and awareness. Employees didn’t fully understand the risks.
The same kind of issue can happen during data annotation. Someone can download files to a personal device, share access incorrectly, or misconfigure permissions. These small mistakes can quickly turn into serious security incidents if there is no proper control.
Building Secure Workflows from the Start
Expert leadership makes the difference at exactly this point. Compliance specialists or data protection officers set up secure workflows right from the start.
They don’t wait for the problems to happen. These experts know how to prevent them from the beginning. For example, in a healthcare AI project, teams make sure they anonymize sensitive patient data before sending it to annotators. They also decide who can access the data and record every action.
Many healthcare AI companies use this approach. When handling medical images, they often apply strict preprocessing and limit access rights from the start. These choices are not made by tools; they are made by people who understand the risks and the rules.
Training and Awareness Matter
Even with strong systems in place, people still need to know how to use them correctly. That’s why training is an important part of AI data security. Annotators and other team members should understand how to handle sensitive data and what risks to watch for. Regular training prevents common mistakes, like using unsecured networks or weak passwords.
For example, many companies run security training programs and even simulate phishing attacks to test employees. This enables teams to recognize threats in real situations and respond correctly. Over time, employees become more careful and confident in handling data.
Staying Ready for Audits
Another key role of expert-led teams is being prepared for audits and checks. Many regulations require companies to prove how they manage data – not simply say they are compliant. Without proper preparation, this can be stressful and risky. But when experts design the processes from the start, everything is already in place: access logs, workflows, and security measures.
For example, companies working under HIPAA must be able to show how they protect medical data at any time. Teams with strong compliance leadership can do this quickly and without issues, avoiding fines or delays.
Conclusion
Security is a culture, not a checklist. Organizations that treat it as such do more than avoid breaches; they build lasting trust with clients and regulators. Rules and regulations are becoming stricter, and the risks of crowdsourced annotation are often bigger than people think. Good security practices include anonymizing personal data, access control, data management throughout its lifecycle, strong encryption, and NDAs. These are all important, but they only work well when experienced people set them up and manage them properly.
Tools and policies alone are not enough for AI data security. Real security comes from people. Everyone working with data needs to understand why it matters and take responsibility for protecting it. Leaders also need to follow these rules and set a strong example.
Companies that build this kind of culture do more than avoid problems. They build trust with clients and regulators, which becomes a real advantage over time. In contrast, companies that treat security as a formality or see agreements like NDAs as paperwork take serious risks. This can lead to legal issues and damage their reputation, especially now that data breaches are widely reported and regulations are strict.
Any project that uses personal data carries some risk. Working with a trusted partner who takes security seriously helps reduce that risk and ensures teams handle data in a safe and responsible way.
Are you working on an AI project? Avoid data risks by working with trusted experts. Contact Tinkogroup for secure, NDA-protected data services.
What is the biggest AI data security risk during annotation?
The biggest risk is exposing sensitive information to unauthorized people during the labeling process. Annotation often involves raw datasets containing personal, financial, medical, or proprietary data. Without strict access controls, anonymization, and secure environments, unauthorized people can copy, leak, or misuse this information. Crowdsourced annotation models are especially risky because companies have limited visibility into who accesses the data and how it is handled.
How can companies protect sensitive data during AI annotation?
Companies can reduce AI data security risks by combining technical, legal, and operational safeguards. Best practices include anonymizing personally identifiable information (PII), applying role-based access control (RBAC), using encrypted systems and VPNs, enforcing multi-factor authentication (MFA), and requiring NDAs for all team members. Many organizations also work with managed annotation teams instead of open crowdsourcing platforms to maintain stronger control and accountability.
Why is compliance important in AI data annotation?
Compliance with regulations such as GDPR, CCPA, and HIPAA is essential because annotation workflows often involve sensitive personal data. Failure to follow these regulations can lead to heavy fines, legal action, reputational damage, and loss of customer trust. Strong compliance practices also help companies build secure AI systems that are reliable, audit-ready, and trusted by enterprise clients.


