We still don’t fully understand how powerful artificial intelligence really is. It’s like looking at an ocean and only seeing its surface. AI now runs the world’s most advanced systems – self-driving cars, medical diagnostics, and even fraud detection. And each of these AI models always begins with data.
In the early days of AI, data was simple. Back in the 1990s, researchers trained models using the MNIST dataset – it’s about 60,000 handwritten numbers that taught computers to recognize images. Today, we’re literally swimming in information. This year alone, the world is generating a staggering amount of data – around 181 zettabytes. But all that data means nothing if you don’t give it meaning with proper annotation. Now, think again about this amount – that’s where traditional manual methods fall short, as they’re simply too slow, costly, and inconsistent to keep up.
What is the solution? New data annotation trends. These include synthetic data that solves data shortages and privacy issues, real-time data processing, and human-in-the-loop systems. We’ll also explore ideas like RLHF in chatbots, multimodal annotation, and decentralized networks . Learn more about recent data annotation industry trends.
Real-Time Data Annotation for Dynamic Environments
AI moves from labs to the real world, and models can’t rely only on static datasets – they need to learn and adapt instantly. Traditional, pre-labeled data is no longer enough. Real-time data annotation can be compared to a live sports commentary team. Live data from sensors, video feeds, or financial transactions is processed instantly. This continuous process generates a constant flow of newly annotated data, and the AI model can learn and adapt to new scenarios without pause.
Where Is Real-Time Annotation Used?
Tesla and Waymo use real-time annotation to train self-driving cars. Mapping systems also use live data – they constantly analyze real-time data to detect road changes, accidents, or construction, and update routes automatically.
Real-time annotation is also used for content moderation on social media platforms. When live videos or chats stream in, AI tools scan and label toxic or harmful content before most people even see it.
In healthcare, it’s saving lives. AI-assisted radiology systems label medical scans when they’re captured and enable doctors to detect issues right away. Financial institutions use it too – AI monitors transactions in real time and flags suspicious patterns before they turn into fraud.
Key Challenges and Solutions
It’s not easy to build real-time annotation pipelines. Major hurdles are:
Speed. Data must be labeled almost instantly, within milliseconds, actually.
Changing data. The patterns in incoming data keep shifting, so models need to adapt constantly and still remain accurate.
Speed and quality must be well balanced, as in many areas, safety depends on correct labeling. Teams use tools like Apache Kafka or AWS Kinesis to process data in real time and flag uncertainties for human review. You can also use Labelbox and Scale AI to create real-time dashboards to track accuracy and catch mistakes.
Synthetic Data for Rare or Sensitive Scenarios
Real data is great, but not in all situations. Privacy laws often tie your hands, and rare events are hard to capture in reality. However, we can generate synthetic data which mimics true-to-life patterns without the risks. It’s like a Hollywood set – you create convincingly lifelike, but entirely fabricated situations that can equally happen in real life.
Synthetic data doesn’t come from real people, so there are no privacy issues. You don’t expose anyone’s personal details, yet you effectively train your AI model without the cost, risk, or time delays.
Real-World Applications of Synthetic Data
It’s one of the best data annotation trends for healthcare. Tools like Synthea can create fake patient records that look and behave like real ones. They include details such as age, symptoms, and diseases, helping train AI to spot rare conditions – like uncommon cancers – without using anyone’s private medical data. Researchers at Mayo Clinic already use synthetic records to test AI on a wider range of cases and save more lives.
Synthetic data also plays a big role in autonomous driving. NVIDIA’s DRIVE Sim builds realistic virtual worlds with extreme weather or accidents – blizzards, pileups, or sudden obstacles – that are too dangerous or rare to capture in real life.
Workflow and Validation
How does the process of synthetic data annotation look? First, advanced generative models (GANs and diffusion models) create realistic data that mimics real-world patterns. Because the data is generated, the key information is already built in. This means labeling can be done automatically or with minimal human effort.
The key step is validation, as the data must be carefully checked. Synthetic data can look real but still miss small, important details. AI trained on it may perform well in tests but fail in real-world situations. That’s why it’s important to validate carefully and combine synthetic with real data whenever possible.
RLHF in Conversational AI
Have you ever wondered why ChatGPT feels so human-like? It’s thanks to Reinforcement Learning from Human Feedback (RLHF). The RLHF data annotation process has several stages. First, the AI is trained on huge amounts of text to learn basic language patterns. Then, it’s fine-tuned with better, more focused examples. After that, people review the AI’s answers and rank which ones are best. The system learns from these rankings to give safer and more useful replies.
Unlike normal labeling, this feedback compares answers and helps the AI understand what “good” looks like. This feedback-driven behavior is closely connected to how AI systems adapt in real time at the interface level, which is why adaptive user interfaces are becoming a critical layer for delivering conversational AI that feels responsive, contextual, and human-like.
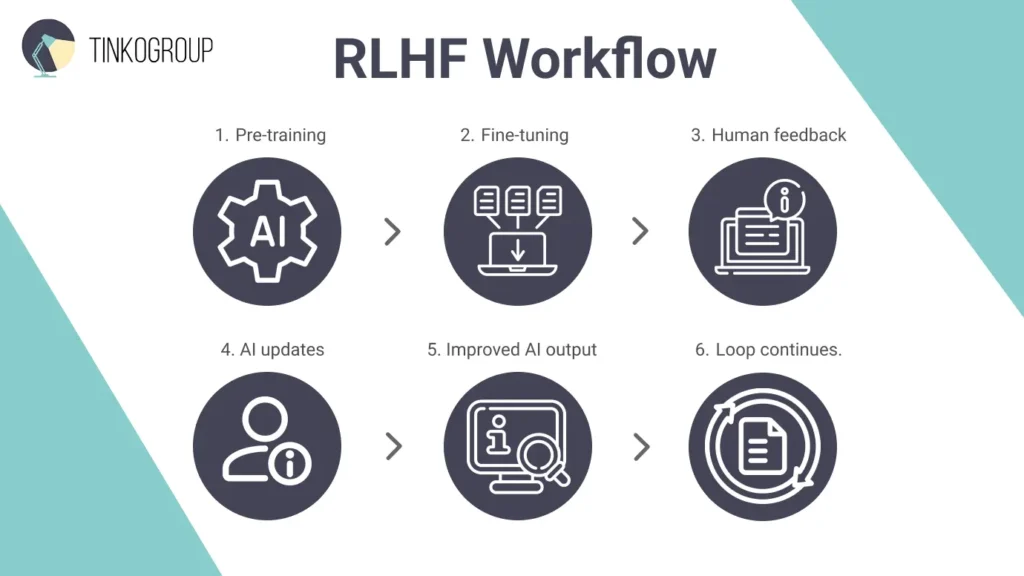
Where Can You Use RLHF?
RLHF annotation workflows are common in most chatbots and assistants we use today. OpenAI’s ChatGPT uses it to give clearer answers, better summaries, and more natural conversations. Google applies RLHF in customer support bots, which improve user satisfaction by around 40%. Anthropic’s Claude uses it to handle sensitive topics safely and refuse harmful requests. RLHF also works in healthcare assistants that answer patient questions and learning apps like Duolingo that adapt lessons to each user.
Difficulties of Implementing RLHF
Using RLHF isn’t easy. It needs lots of high-quality human feedback, which can be slow and expensive to collect. Training also requires heavy computing power and is hard to scale. If feedback is inconsistent or biased, AI can pick up bad habits. Sometimes it can even “overfit” to human preferences and produce hallucinations or misleading responses. Teams must use diverse groups of reviewers, regular audits, and strong human oversight to keep models safe and reliable.
LLMs for Automated Pre-Annotation
LLM pre-annotation is one of the most important data annotation trends. LLMs understand text almost like humans do. When you talk to Siri or Alexa, you’re interacting with an LLM. These systems can quickly sort reviews by sentiment, summarize data, spot patterns, or fix inconsistencies. Many of these tasks are classic examples of text classification, where models automatically assign categories such as sentiment, topic, or intent to large volumes of unstructured text. And the biggest plus is their fantastic processing speed. Now, people don’t have to spend hours on labeling – LLMs can do it in seconds with much better accuracy. It reduces the time and cost of human work by 90% in the initial annotation stages.
How Are LLMs Used in Pre-Annotation?
Many teams LLMs as annotation helpers. Usually, LLMs do the pre-annotation stage. It instantly goes through big amounts of text and adds tags automatically, for example, marks a comment as “positive,” “negative,” or “neutral,” or tags a post as “sports,” “tech,” or “politics.” Then, human annotators check and correct these labels. This saves hours of work and keeps data more consistent. The approach is used in many areas – LLMs are sorting emails or moderating chats. They are especially effective for routine labels, allowing people to pay more attention to tricky cases.
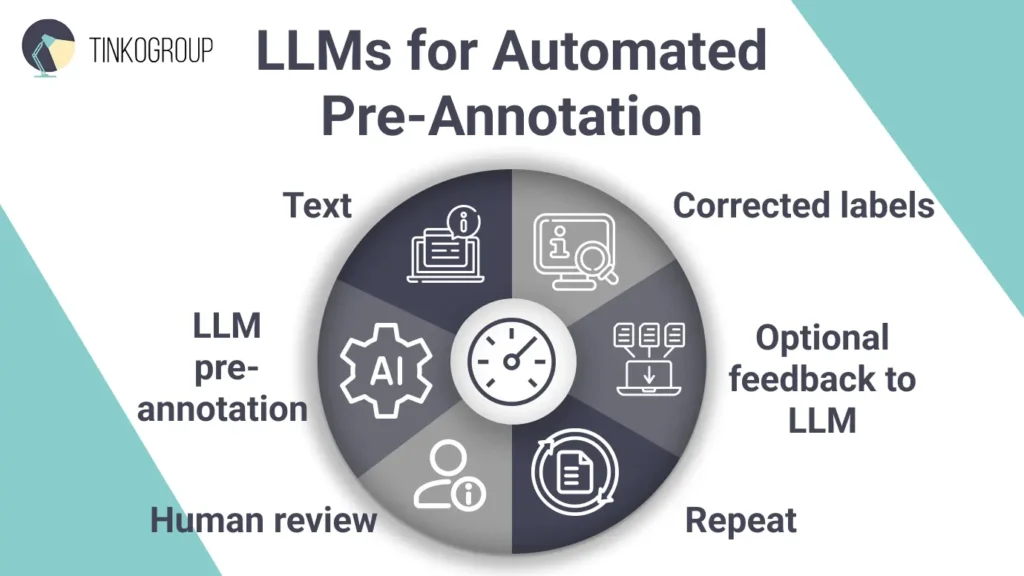
Benefits and Risks of LLMs in Pre-Annotation
LLMs save time and money as they can pre-label data much faster than humans. They apply the same rules consistently, which means fewer mistakes and more uniform labels. They also spot patterns that humans may miss and make large datasets easier to manage.
However, there are also downsides. LLMs can make mistakes or inherit biases from their training data. If unchecked, these errors can spread across the dataset. This is especially critical for computer vision tasks, where even small annotation mistakes can significantly impact detection model training accuracy. They may also struggle rare cases or narrow topics. That’s why human review is still important, especially for sensitive or high-stakes projects. Another thing to consider is the cost. For small datasets (under 10,000 items), using LLMs to pre-label data can actually be more expensive than having humans do it directly, because of setup, prompts, checking, and fixing mistakes.
Cross-Modal and Multimodal Annotation
How can AI understand the world like humans do? It must learn to deal with different types of information simultaneously. AI does it via cross-modal and multimodal annotation.
When AI is annotating a video, it labels multiple data types together – text, images, audio, and video. For example, AI can link a person’s gesture (visual), tone of voice (audio), and subtitles (text) to better understand the scene. It’s multimodal annotation.
Cross-modal annotation is a bit different. In this case, AI doesn’t label everything together; it transfers labels from one type of data to another. For instance, labels from an image can help annotate a related audio clip or video.
Where Are These Data Annotation Trends used?
Multimodal and cross-modal annotation are useful in many fields. Video captioning combines visuals and audio to create accurate, accessible text – you can see it in YouTube’s auto-subtitles. Audio-visual scene understanding is part of smart home devices.
Multimodal search engines mix text and images to give better search results for shopping or learning.
Sometimes, this approach to annotation is the only solution to label things correctly. Think about Internet memes, which are the hardest to interpret for AI. They mix pictures, text, and sometimes music or trends. To understand them or spot harmful content, you need to see all parts together. That’s why multimodal annotation is the best, for example, for content moderation.
Tools and Advances
New AI models are making multimodal annotation easier. CLIP links images with text, and Whisper handles speech, and both can suggest labels automatically. Transfer learning uses labels from one type of data to label another and reduces manual work. Many modern tools can work with images, video, audio, and text at the same time – CVAT, Label Studio, Encord, and Roboflow. These platforms make labeling faster, more consistent, and closer to how humans understand the world. Automated tools help a lot, but annotators must always control the accuracy.
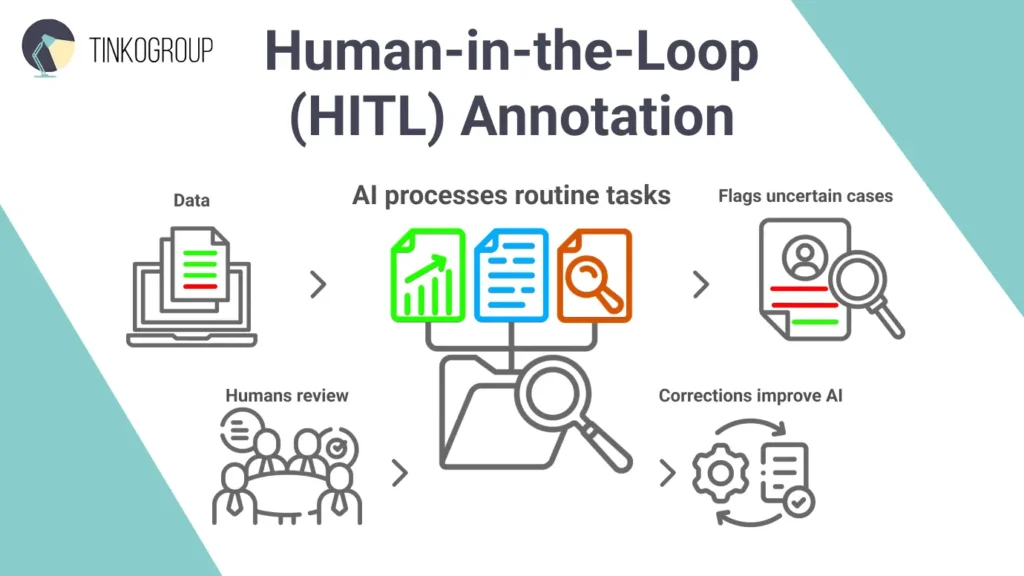
Human-in-the-Loop for Edge Cases
AI gets smarter every day, and data annotation trends allow us to automate practically everything. And here is the paradox – the role of humans is growing too. AI performs ideally when solving routine tasks. However, its confidence is usually 95%, and it’s not enough in many situations. AI gets puzzled when it faces new, unusual things, let’s say a cat in a costume or an animal-shaped cloud. Humans can intervene and bring their knowledge when such an uncertainty happens. People are familiar with exceptions, nuances, and ethical norms. Healthcare, finance, and law are those high-risk areas where AI may still struggle. Humans are needed as expert reviewers.
Practical Cases of HITL Annotation
Why is human-in-the-loop annotation critical? Imagine AI reading a chest X-ray. It flags a suspicious shadow, which can be early-stage lung cancer, pneumonia, or a sign from the patient’s previous surgery. The model’s confidence score is about 73%, and it’s too low for automatic diagnosis. A radiologist can analyze patient history, symptoms, and even catch subtle anomalies on the scan.
The same happens when AI pre-screens contracts for risky clauses. Only a lawyer can fully understand the context and local regulations to tell whether a clause is really problematic. Lawyers review flagged items and separate false alarms from real issues.
In both cases, AI does a big job, but it’s still humans who help avoid critical mistakes.
How Does the HITL Approach Work?
Human-in-the-loop (HITL) mixes AI speed with human knowledge. AI handles the routine data, then flags tricky or uncertain cases for people to review. The rule is to keep the balance. Too many flags and reviewers get overwhelmed; not enough flags and issues slip through. Easy cases go to junior reviewers, harder ones go to experts. Teams watch metrics like how often humans disagree with AI, how fast reviews happen, and cost versus quality. Human corrections feed back into the AI, helping it learn and improve. AI does the heavy lifting, and humans focus on control.
Convergence of Synthetic Data and Real-Time Annotation
Sometimes, you simply don’t have enough real-world examples. You no longer have to wait for real data. You can use synthetic data streaming and create and label your own data instantly. It allows the system to fill gaps in knowledge as they happen and avoid delays. Think of it like just-in-time manufacturing, but for AI training. AI sees something new, generates examples of it, and improves immediately. When you combine synthetic data with real-time annotation, you let AI systems adapt on the fly. They instantly learn how to handle unusual situations without the need to rely only on real-world data.
Where Can You Use Synthetic Data Streaming?
Synthetic data streaming has many practical uses. On factory floors, robots can spot unusual problems, like damaged parts or misplaced items. They instantly generate similar situations and find a solution before the next run. This modeling is also good in emergencies. For instance, when wildfires are spreading unpredictably, teams can create “what-if” scenarios on the spot. It allows them to plan evacuation routes and decide how to act. City traffic systems benefit, too. Sudden disruptions, like street festivals or burst water pipes, can be simulated immediately. Cars are rerouted in real time with no time losses and unfortunate consequences.
Human-in-the-Loop Automation 2.0
Traditional human-in-the-loop systems follow strict rules. You can ask AI to flag anything below 75% confidence or send all scans with certain markers to humans. These rules work, but they may fail when data changes or unusual cases happen. However, annotators can train meta-models which know when to ask for human help. How does it happen? The system tracks every review made by humans and soon, it learns to recognize what’s safe and what’s tricky. Humans don’t purely train AI but also teach it to ask for a review. The system learns to spot tricky cases on its own and only asks for human input when it really matters. This makes AI smarter and saves humans time.
Where Is HITL Automation Used?
HITL automation is already actively used for medical data review. PathAI, a pathology platform, uses meta-models to decide which tissue samples need human attention. Routine biopsies are analyzed by AI, and tricky cases go straight to specialist pathologists. The system has learned that certain tissue types, even when AI is confident, still need human review because people notice subtle details AI can miss.
Emergency rooms are testing similar systems. They use past cases to figure out which patients need a doctor right away and which can be safely seen by a nurse practitioner. It prioritizes care in medical institutions.
The Benefits of This Approach
Human-in-the-loop (HITL) systems take AI to the next level. They free experts from repetitive tasks, allowing them to deal with more knowledge-heavy work. These systems quickly adapt to changing situations and stay effective in dynamic environments. Human input adds 15–30% more effort upfront, but it reduces errors, rework, and long-term costs. Overall, HITL balances automation with human judgment and seriously improves AI performance.
Foundation Models in Annotation Tooling
Annotation platforms are also changing. In the past, they were like spreadsheets – you opened an image, drew boxes, typed labels, and repeated the process over and over. Now, foundation models are built right into the workflow. AI works together with annotators and learns from each decision. This means humans don’t start from scratch every time. The main job – labeling data – stays the same, but the process is faster, smarter, and easier. It’s like upgrading from a typewriter to a smartphone. A good example is Roboflow, a top platform which uses Meta’s Segment Anything Model (SAM) and Grounding-DINO to speed up image labeling. What used to be slow, manual work is now a quick, interactive process
Features of Foundation Models
Foundation models are changing how data is labeled. Smart pre-labeling lets AI do the first round of tagging- it’s like GPT-4o spots emotion in text or SAM outlines objects in videos. Context-aware suggestions take it further. The system notices patterns as you work and starts suggesting similar labels automatically. Adaptive feedback loops help the AI learn quickly from your edits. Tools like Encord and Roboflow improve with every correction, cutting down errors and saving time. The more people use them, the smarter and faster the labeling becomes.
How Do Foundation Models Change Data Annotation?
Foundation models are changing the role of human annotators. People don’t need to label everything by hand. Now, they act as supervisors who check AI-generated labels, spot tricky edge cases, and correct subtle errors the AI misses. It creates a smooth workflow where humans and AI work side by side. Annotators guide and refine the AI’s output, improving both accuracy and speed. Some platforms report up to 70% faster annotation with fewer mistakes. The result is more consistent, high-quality data labeling.
Bias, Explainability, and Governance
The rapid development of annotation tools brings new headaches – issues with bias, transparency, and control. AI simplifies labeling, but it can also make hidden problems worse. If people accept AI suggestions without thinking, small biases can grow over time, and the model will even reinforce these. One way teams reduce these risks early is by starting with prepared AI datasets, where data distributions, labeling logic, and known limitations are documented before models are trained at scale.
A 2024 UNESCO study showed how bias can sneak into AI systems. Researchers found that large language models link women to words like “home” and “family” four times more often than men. At the same time, male names were often connected to “business,” “career,” and “executive” roles. This shows how AI can repeat old stereotypes from the data it’s trained on, even without anyone meaning to.
Explainability in Annotation
Another problem is that AI tools often suggest labels without showing how they reached that choice. It makes labeling faster, but also riskier. Annotators might accept the AI’s black-box suggestion only because it looks confident, not because it’s right. Without knowing why a label was chosen, it’s hard to spot mistakes or understand the AI’s reasoning. This lack of transparency can be dangerous in sensitive areas, where even small errors can have serious real-world consequences. In short, if humans can’t see the logic behind AI suggestions, they can’t properly trust or correct them.
Governance and Audit Trails
Annotation must be both auditable and compliant. It’s vital for all industries, especially for finance, healthcare, and law. It’s no longer enough to know what was labeled. Organizations must also know how, why, and by whom every label was made. Audit trails can become a good solution.
These systems track data lineage, which shows the origin and changes of each data point. They include annotation justifications for tricky labels, quality metrics and change logs for updates to labels or guidelines.
The first steps have already been taken. The EU AI Act and ISO/IEC 42001 require companies to prove responsible data management. In healthcare, radiology labels might need verification by certified specialists. In finance, labeling must fairly detect fraud.
Clear audit trails and governance reduce compliance risks, ensure accountability, and build trust. It helps us use AI systems in real-world applications without undesirable outcomes.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Community-Driven and Decentralized Annotation Networks
Data labeling should not necessarily be done only by centralized vendors or in-house teams. Community-driven and decentralized networks are the future of data annotation. They let experts, enthusiasts, and everyday users contribute together. Some platforms even reward participation with tokens or recognition. Blockchain takes it a step further – it creates a secure, tamper-proof record of every contribution.
For example, Nuklai allows users to share AI-ready datasets safely and earn $NAI tokens while collaborating globally. Hypothesis lets people annotate web content, videos, or PDFs in real time, and Perusall turns readings into interactive forums where AI summarizes the group’s insights. These data annotation trends move control from big vendors to communities and make data accessible to everyone.
Benefits of Open Annotation Networks
The perks of decentralized annotation networks are huge. And the first is transparency. You can actually see who labeled your data and what edits were made and when. If something looks off, the full record is right there for anyone to check.
They’re also more diverse. It’s not one small team working in isolation – contributors from around the world bring different languages, cultures, and viewpoints. That mix reduces bias and leads to richer, more balanced data.
And because contributors can earn rewards, they are motivated to do their best work. In the end, everyone wins: the data gets better, the process is fairer, and AI systems become more trustworthy.
Future Outlook
Decentralized networks will make quality data available to everyone, not just large companies. Nuklai already lets people share and earn from their data, and DePin platforms give users more control through blockchain and tokens. Experts believe that in a few years, these systems will power secure, community-driven AI training.
This shift lowers costs, reduces bias, and brings innovation. Startups, researchers, and even schools will be able to access data that was once too expensive. Communities will create and improve datasets together and turn annotation into a shared, global effort that builds faster and fairer AI.
Conclusion
Data annotation has stepped beyond labeling images or tagging text. Today, it’s a sophisticated ecosystem where AI assists humans, synthetic data fills real-world gaps, and, actually, everyone can contribute to datasets that were once controlled by a few companies.
The data annotation trends we’ve explored aren’t distant possibilities. They are confidently changing how organizations build AI right now.
Companies that adapt early will train better models faster and cheaper than competitors stuck with outdated manual workflows. Those who ignore these shifts will not be able to keep up with the teams that use smarter annotation strategies.
Annotation is no longer a tedious preliminary step, but a strategic advantage. Start experimenting now. Your competition already is. If you are looking for a reliable partner to navigate these trends and implement high-quality annotation workflows, Tinkogroup is ready to support your AI journey.
Why is data annotation becoming more complex and important today?
Data annotation has evolved because AI systems now operate in real-world, high-risk, and dynamic environments. Modern models rely on massive, fast-changing, and multimodal data rather than small static datasets. To keep AI accurate and safe, annotation must be faster, more scalable, and more reliable. Trends like real-time annotation, synthetic data, and human-in-the-loop workflows help address data volume, quality, privacy, and edge cases that traditional manual labeling cannot handle efficiently.
Can AI fully replace humans in data annotation?
No. While AI and large language models can automate up to 70–90% of routine annotation tasks, human expertise remains essential. Humans are critical for handling edge cases, ethical decisions, rare scenarios, and high-stakes domains like healthcare, finance, and law. The most effective approach is human-in-the-loop annotation, where AI handles scale and speed, and humans provide judgment, validation, and governance.
How can organizations prepare for future data annotation trends?
Organizations should adopt hybrid annotation pipelines that combine AI automation, human review, and strong governance. This includes using LLMs for pre-annotation, integrating synthetic data where real data is limited, enabling real-time annotation for dynamic systems, and maintaining audit trails for compliance and bias control. Early adoption of these practices helps teams reduce costs, improve data quality, and build more robust and trustworthy AI models.