

Frame-by-frame annotation is often discussed as if it were simply one of many technical approaches to data annotation. A line item in the budget. A point in the documentation. Something that can be discussed calmly and rationally. The engineer who wrote these lines thought so too, just yesterday.
Formally, everything looks simple: the video is broken down into frames, and each frame is annotated separately. But a video is not a set of images arranged in the correct order. It is a continuous process where objects exist in time, not in isolation. They accelerate, slow down, disappear, reappear, overlap with other objects, and behave in ways that are not typical of neat educational examples.
In a static image, an object is either present or absent. In a video, it changes from frame to frame, and it is these changes that carry the main meaning. The context between frames is often more important than the frames themselves, but it is this context that is most often lost when videos begin to be perceived as “a series of pictures.”
Before the release, it seemed that automation would do the job. That interpolation would fill in the gaps. That rare errors would not matter. It worked in the demo scenarios. It also worked on short, pre-prepared clips. But in real video, where movement is non-linear and decisions are made based on a chain of previous frames, inaccuracies began to accumulate.
Frame-by-frame annotation turned out to be what we were trying to get away from. It is expensive, slow, and difficult to fit into deadlines. It is difficult to explain to management and even more difficult to scale. But it remains the only reliable way to obtain data that can be trusted when movement becomes chaotic and automatic methods begin to guess rather than understand.
After the failed release, it became clear that saving on frame-by-frame accuracy doesn’t disappear, it just gets postponed. And it almost always comes back at night, in production, when it’s too late to explain why the model is behaving exactly as it was taught.
The Core Concept: How Video Annotation Works
When the term FPS appears in annotation guidelines, it usually seems innocuous. Frames Per Second. Thirty, sixty—numbers that are easy to glance over. The engineer who wrote this text also glanced over them until he had to recalculate the volume manually.
One minute of video at 30 FPS is 1,800 individual frames. Not “approximately.” Not “about.” Exactly 1,800 images, each of which may contain an error. Ten minutes is already 18,000 frames. An hour is more than 100,000. At some point, it becomes clear why conversations about video markup almost always end up being about budget and deadlines.

But the problem is not just the quantity. Each frame is linked to the previous and next ones. An error made in one of them does not remain local. It spreads further, affecting the trajectory, the speed, and how the model interprets what is happening. In images, the error is static. In the video, it spreads over time.
The goal of the frame by frame video annotation has never been to simply show the model where an object is located. That is a relatively simple task. It is much more difficult to teach the model to understand what the object was doing a second ago, what it is doing now, and what it is likely to do in the next frame. It is not about recognizing shapes, but about recognizing movement.
Many computer vision models depend on this temporal information. Trajectory prediction models use a sequence of frames to understand direction and intent. Autonomous driving systems rely on the history of pedestrian and vehicle movements, not on single images. Even models that formally work with individual frames are actually trained on data where temporal connectivity is already embedded at the annotation stage.
The problem is that time cannot be restored after the fact. If the annotation is inaccurate, if the object “jumps” between frames or loses its logical trajectory, the model learns incorrect dynamics. It may see the object correctly, but misunderstand its behavior. And this difference only becomes noticeable when the system goes beyond laboratory scenarios.
This is where it becomes clear why frame-by-frame labeling is so difficult to perceive as a process. It requires thinking not in terms of frames, but in terms of intervals. Not in terms of the position of the object, but in terms of its movement. And every time this principle is ignored, the video turns into a set of pictures — and the model begins to behave as if time does not exist for it.
Frame-by-Frame vs Interpolation
After that night’s release, the team finally sat down to figure out what went wrong. And it turned out that what no one really understood before was that “saving” on marking turns into nightmares when it comes to real data. Video interpolation seemed ideal. Mark only the key frames and let the tool fill in the gaps — it seemed like a time and effort saver. And indeed, on test videos with smooth car movements and a camera on a tripod, everything looked perfect. On short, idealized segments with straight-line movements, the models worked like a charm.
But in the real world, movement is almost never linear. Pedestrians stop, turn back, turn around on the spot, don’t keep their direction, and objects are partially hidden behind obstacles. And this is where interpolation ceased to be a tool and became a source of errors.
Engineers would then sit up at night, recalculating frame by frame. Every “mistake” in the interpolation was visible as a small but very painful detail. The bounding box on a pedestrian would jump: one frame to the left, another to the right. The ball in a soccer match “jumped” across the field, and the model’s trajectory was literally incorrect because the tool “assumed” that the movement was linear. And every time someone tried to prove that it could be “finished later,” the team realized that later would never come.

Frame-by-frame annotation is the opposite of interpolation. It is a painful, slow, and expensive process where each frame is checked manually. Each frame is marked precisely, taking into account movement, changes in scale, shape, and partial concealment. Each frame is checked to see if the object is mixed up or if its identifier is shifted. This is the only way to get truly Ground Truth data. No interpolation, no guesswork, no “automatic alignment.” Only accuracy and control.
But the price of this accuracy is enormous. It’s not just in money, although it’s expensive there too. It’s in fatigue, in mental exhaustion, in endless checks. When annotators, engineers, and managers see these numbers — 1,800 frames per minute — they understand that this is no joke. Every frame is a potential error. Each frame is a small responsibility for how the model will behave in autonomous driving or in real time.
Sometimes it seemed like the whole process was pointless. The team sat up at night, accumulating fatigue, checking a ball that flies fifty meters in a fraction of a second, recording every pixel that changes position by a millimeter. And it is at moments like these that you realize that “saving” on interpolation is not worth dealing with the consequences later. What seemed like a trifle accumulates and bursts out in the form of model failures.
In retrospect, one simple thing becomes clear: if movement is predictable, interpolation is a useful tool. But life and video are rarely predictable. Human behavior, objects in an urban environment, sports situations — all of this is chaos. And it is chaos that reveals the true value of frame-by-frame annotation.
It’s not just marking up. It’s control over time, movement, and chaos all at once. It’s a process that no one likes, but no one can ignore. Because when you skimp on frames, you lose control over the model’s behavior. And at night, in the thick of working on the system, you understand this more clearly than ever.
Types of Objects & Annotation Methods in Video
After a failed release, the team once again immersed itself in marking up, and it became clear that different objects require completely different approaches, and there is simply no universal solution.

Bounding boxes are the simplest and, at the same time, the most deceptive. At first glance, everything is obvious: a rectangle around a car or pedestrian. On paper, it’s a piece of cake, but in real life, it’s a disaster. A car that appears to be stationary is actually moving slightly, objects on the road overlap each other, shadows fall differently, and the bounding box begins to “shake.” A small jitter in the marking, which seems insignificant, accumulates and breaks out in the form of incorrect model predictions. Every shift, every frame with an “incorrect” box is like the night before a release, when engineers review 1,800 frames per minute and think, “How did we not notice this before?”
Polygons are another level of pain. There are no simple rectangles here. You have to repeat the shape of the object almost pixel by pixel. This is important for drones, robots, and any objects with uneven boundaries. But imagine how much time it takes to correctly outline the contour of an object in each frame, especially if the object is moving chaotically. Polygonal marking is an endless game with points and lines, where a single mistake in a minute of blurring or sudden movement turns into a disaster for the model. The team sat up all night, changing points, moving them millimeter by millimeter, until their eyes were almost glued shut.
Keypoints or Skeleton Tracking is a separate story. When it comes to human movement, gait, sports analytics, or healthcare, every key point must be recorded: joints, hands, feet. And if even one point is missing or shifted, the entire model begins to interpret movements incorrectly. In a real project, this manifested itself in a video with soccer players: one incorrectly marked elbow, and the entire analysis of the player’s speed, direction, and intent became false. Even worse, when a player suddenly changes position, each key point must be manually adjusted so that the model does not “go crazy.”
Finally, video semantic segmentation is a real torture for the eyes and brain. Every pixel in every frame gets a label. At first glance, this seems ideal: accuracy, control, Ground Truth level data. In practice, it means thousands of hours of work, night shifts, and constant doubts. Where does the object end and the background begin? How do you mark partially hidden objects when the frame rate is high and the movement is chaotic? It’s not just hard work, it’s a constant feeling that you’ll never finish, that the model will still find a way to make a mistake, and your work may be in vain.
After those nights, the engineers understood one simple thing: every technique has its limits, its weaknesses, and its nights of suffering. Bounding boxes are fast, but sometimes not fast enough. Polygons are accurate, but terribly slow. Keypoints are informative, but dangerous with complex movements. Semantic segmentation is perfection on paper, hell in reality.
And no one on the team argued: if you want the model to really understand video and object movement, you have to put up with all of this. There is no other way. You can save on frames, interpolation, automation — and hope that the model will guess right. But the real world doesn’t guess, and this becomes obvious at night, when there are 1,800 frames on the screen and each one requires attention.
The Challenge of Temporal Consistency
In the evening, after another failure, the team gathered again in front of their screens. This time, the problem was almost imperceptible at first glance: objects “shaking” between frames. The bounding box, which was supposed to remain stationary on a car or pedestrian, shifted slightly from frame to frame. One pixel to the left, another to the right, sometimes down. It was almost imperceptible to the eye, but the model reacted to it as if it were a signal: the object was moving, changing direction, accelerating. In reality, it was standing still.
This problem was called temporal consistency, and it was the bane of everyone who worked with video. As long as the frames were marked automatically or using interpolation, the jitter appeared at every step. The models began to get confused: trajectory predictions became chaotic, object identifiers got mixed up, and motion predictions became completely inaccurate. Every small shift in marking creates a chain reaction of errors, which then pops up in production at the most inopportune moment.
Sometimes the team tried to rationalize: “Well, it’s a minor issue, the models will learn to ignore it.” But that was a deception. In practice, the model does not know how to “ignore.” It takes data literally, and any inaccuracy in the frame is perceived as a change in movement. In autonomous driving, this means that the car may suddenly “decide” that a pedestrian is changing direction, even though they have simply stopped. In sports, it means that a player has suddenly accelerated, when in fact they have slowed down. At night, reviewing thousands of frames, engineers saw how a small tremor turned into a big mistake.
Frame-by-frame annotation is the only thing that helps to cope with this problem. When each frame is checked manually, each mark is fixed with precision, and the tremors practically disappear. Engineers spent nights adjusting the positions of bounding boxes, polygons, and key points. Every frame that could “shake” was corrected, sometimes millimeter by millimeter. It’s tedious and painfully slow, but it’s the only way to ensure the smoothness and stability of the data, without which the models begin to learn incorrectly.
And every time someone tried to suggest “speeding up the process” with automation, there was a quiet but heated discussion: saving time now would result in chaos later. The team understood that if temporal consistency was violated in even a couple of hundred frames, the importance of correct annotations only becomes apparent after weeks of testing in a real environment, when it would be almost impossible to fix them.
So, night after night, the engineers began to understand that working with video is not just about marking objects. It is a battle against time itself. Each frame is a small point in the history of movement. If temporal consistency is violated, history turns into chaos, and no automation can save the situation.
Handling Complex Scenarios (Occlusion & ID Switching)
After several nights of marking up, when their eyes were already glued shut, the team once again encountered a situation that looked simple on paper but turned into chaos in reality. This was due to objects disappearing from the frame, being covered by others, and suddenly reappearing. This is where the concept of occlusion comes into play.
Partial occlusion is when an object is not fully visible. For example, a car is driving down the street, and a pole or pedestrian appears in front of it for a moment. Part of the car has disappeared from the frame, but part of it is still visible. At first glance, it seems like no big deal: just draw a bounding box around the visible part and continue. But in practice, every little thing like this causes the model to falter. It sees the object as a fragment rather than a whole, begins to incorrectly predict its trajectory, and after a few frames, everything goes downhill.
Full occlusion is even worse. The car is completely hidden behind a tree. The team of engineers sat up all night, arguing about what to do with such frames. Skip them? Assign a temporarily “frozen” bounding box? Any mistake here has consequences, because the model sees the disappearance of the object as the end of its trajectory. And when it suddenly reappears, the model no longer understands that it is the same object. This is where object Re-identification, or ReID, comes to the rescue.
Object tracking in such conditions becomes an art of survival. The system must recognize that this is still #Car_01, which disappeared behind a tree for a couple of seconds, and assign it its previous identifier. Any mistake, and the IDs get mixed up, the trajectories go wrong, and the tags jump chaotically from object to object. The team then sat up at night, double-checking every frame that included occlusion, manually correcting the ID, realizing that automatic ReID algorithms are often not ready for complex situations.
And another pain point is motion blur. When an object moves quickly, especially in high-speed video or sports scenes, it smears. Contours are lost, colors can blend into the background, and marking it becomes torture. Polygons, bounding boxes, keypoints — all of this has to be adjusted almost at random, checking against previous frames and predictions. Each such blurred movement can break the model: it sees the object not as a single whole, but as a blur. These challenges — from unstable movement to disappearing objects — are precisely what define the complexity of video AI. The illustration below captures the core phenomena that demand a frame-by-frame approach:
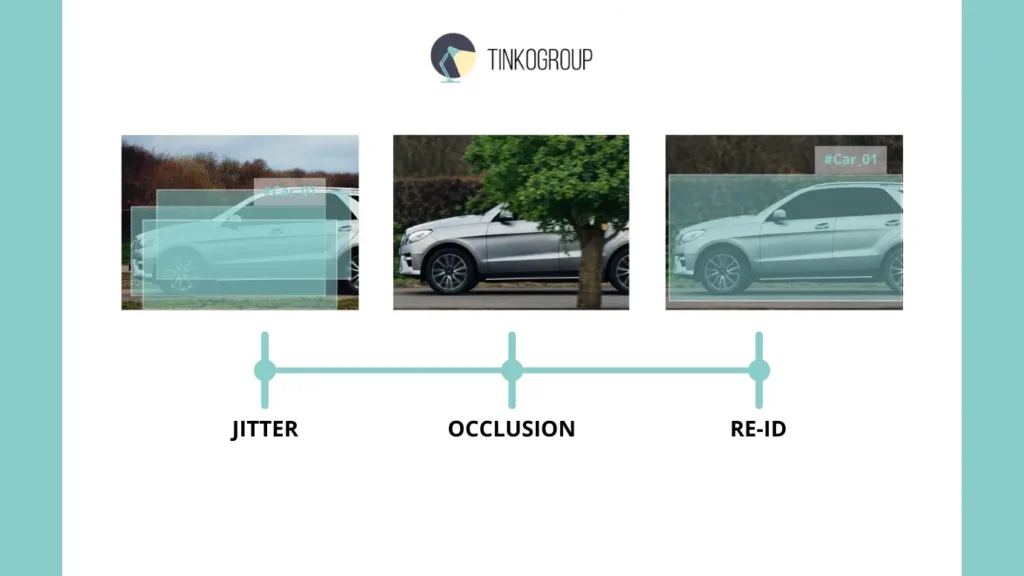
And on nights like these, engineers understand a simple truth: complex scenarios with occlusion, changing identifiers, and motion blur are not bugs, they are the nature of video. If even one moment is missed, the model “learns” incorrectly, and the consequences will only become apparent when the system is released into the real world. Every decision requires patience, time, and attention. Every night spent marking frames reminds us that accuracy comes at the price of human fatigue, not just money and time.
In such conditions, frame-by-frame annotation is not a luxury, but the only way to maintain control. Without it, the chaotic movements of objects, disappearances, and blurring turn into a sequence of errors that are impossible to defend against later. And that is why the team, tired and irritated, still remembers those nights with cold gratitude: only through every check, every corrected mark, every night of struggle could they obtain data that is truly valuable.
Industry Use Cases
When engineers finally stopped discussing abstract approaches and looked at real-world applications, it became clear that the problem was not with the marking tools, but with how the real world behaves in video. Below are the scenarios where all the compromises come to light particularly quickly.
Autonomous Vehicles
In autonomous driving, it is not machines that cause the most problems, but people.
Pedestrians:
- suddenly change direction;
- take a step back, then to the side;
- stop for no reason;
- appear from behind parked cars.
In such scenarios:
- interpolation begins to guess the trajectory;
- object tracking loses its movement logic;
- the model confuses stopping with turning.
Only frame-by-frame marking allows you to maintain a continuous history of pedestrian movement and train the model to respond to sudden, illogical changes in behavior.
Sports Analytics
Sports have proven to be one of the most unforgiving scenarios for video marking.
The main challenges are:
- high speed of moving objects;
- sudden accelerations and changes in direction;
- frequent collisions and overlaps.
When analyzing soccer or tennis:
- the ball moves faster than most algorithms can interpret;
- motion blur distorts the shape of the object;
- an error in one frame breaks the entire trajectory.
The team quickly realized that without a frame-by-frame approach, the ball would “teleport” across the field, and the analytics would lose their meaning. The models see speed but do not understand movement.
Security & Surveillance
In video surveillance systems, the main difficulty is crowds.
In dense scenes:
- objects constantly overlap each other;
- people enter and exit the frame;
- and identifiers are often mixed up.
For such systems, it is critical to:
- maintain correct object tracking;
- avoid ID switching;
- understand behavioral patterns rather than single frames.
Without frame-by-frame stability, data becomes noisy and algorithms begin to respond to false signals. This is where marking errors do not appear immediately, but after weeks of operation.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Medical Imaging
Microscopic video turned out to be the most unexpected and difficult case of all. Before that, the team was sure that the main difficulties were speed, chaotic movement, crowds, and overlaps. But under a microscope, the world behaves differently. Almost nothing happens abruptly there. And that is what makes the task truly difficult.
At first glance, it seems that such videos are easier. The camera is static. The objects are small. The movement is slow. Sometimes it seems that the frames are almost indistinguishable from each other. But it is this “almost imperceptibility” that breaks everything. When the engineer first started looking at such data at night, after a failed release in another project, a strange feeling arose: the model is wrong not because it does not see movement, but because it sees it where it does not exist.
Microscopic videos have their own characteristics, which quickly cease to be theory and become a practical problem:
- minimal object displacements that are difficult to distinguish from noise;
- slow but fundamentally important movements;
- extremely high sensitivity to temporal consistency.
In this data, even a small inaccuracy looks like an event. A slight displacement of the markings between frames is perceived by the model as active cell movement. Where a person sees noise or optical error, the algorithm sees a change in behavior. And the longer it sees this, the more confident it becomes in its conclusions.
When tracking cells, problems do not manifest themselves immediately. In the first few hours, everything looks correct. There are trajectories, and the movements seem logical. But then it becomes apparent that:
- a slight tremor in the markings is interpreted as active migration;
- an error in a few frames distorts the entire time analysis;
- automatic methods cannot cope with visual noise and artifacts.
The most unpleasant thing about these scenarios is the delay in consequences. The error does not immediately become apparent. It accumulates. It affects statistics, conclusions, and the interpretation of results. And when it becomes clear that the analysis was based on unstable data, it turns out that going back is already too expensive.
This is where frame-by-frame annotation ceases to be a conversation about quality. It is no longer a question of accuracy or perfectionism. It is a question of the correctness of conclusions. In medical scenarios, the price of an error is not expressed in model metrics or a drop in accuracy. It is expressed in incorrect interpretations, false patterns, and conclusions that look convincing but are based on shaky data.
This realization does not come immediately. It comes at night, when an engineer manually checks hundreds of frames, notices how a barely noticeable shift repeats itself over and over again, and realizes that the model did exactly what it was taught to do. And in this data, one cannot afford to be “roughly correct.” Here, it is either accurate or nothing.
Conclusion
At this point, the engineer has no illusions left. High-precision models do not come from architectures, presentations, or successful demos. They come from data. And if the data is inaccurate, if it is “roughly correct,” if time was saved in its collection, then the model will behave in exactly the same way—roughly.
Video is especially unforgiving of compromises. It does not forgive shaky markers, lost identifiers, or guesswork instead of facts. An error made in a single frame stretches out over time and takes on a life of its own. That’s why attempts to simplify annotation almost always come back at night — in logs, in strange system behavior, in the feeling that the model “doesn’t understand something,” even though everything was done correctly on paper.
Frame-by-frame annotation remains a difficult, expensive, and slow process. But with each iteration, it becomes increasingly clear that this is not excessive precision, but a basic level without which reliable results are impossible. When movement becomes chaotic, when objects disappear, return, and behave unpredictably, automation begins to guess. And guessing is a poor basis for systems that are expected to be accurate and responsible. This is precisely where a human-in-the-loop approach stops being a methodological choice and becomes a structural necessity: only a human can interpret intent, continuity, and context where automated logic breaks down.
High-precision models require high-precision data. Not because it is written in best practices, but because the real world cannot be simplified into algorithms. It remains complex, nonlinear, and inconvenient. And if the data does not reflect this complexity, the model will never learn it.
For teams that understand the cost of mistakes and don’t want to go down that road twice, there are professional frame by the frame video annotation in machine learning and the frame by frame video annotation in AI services where frame-by-frame accuracy is not an option but a standard. You can learn more about these approaches on the Tinkogroup video annotation service page.
When should I use interpolation instead of frame-by-frame annotation?
Interpolation works best for predictable, linear movements where objects are fully visible and the camera is stable. However, for complex scenarios like urban traffic, sports, or crowded areas, frame-by-frame annotation is necessary to capture non-linear behavior and maintain accuracy.
How does frame-by-frame annotation solve “jitter” (temporal consistency)?
Jitter occurs when automated tools or interpolation “guess” an object’s position, leading to small shifts between frames. Manual frame-by-frame marking ensures that the bounding box or polygon stays perfectly aligned, preventing the model from perceiving false movements.
Why is frame-by-frame annotation crucial for autonomous driving?
In autonomous driving, understanding intent is key. A pedestrian might stop, hesitate, or suddenly turn back. Frame-by-frame precision captures these subtle temporal cues, allowing the AI to predict behavior accurately rather than just recognizing a shape on the road.


