

The term “human pose estimation” sounds deceptively simple today. It gives the impression that it is just another pose estimation in computer vision task — detecting a person in a frame and placing several points on their joints. In practice, however, it is an attempt to formalize one of the most difficult things a machine faces: the human body in motion.
It is not just about detecting a figure. The model must understand the geometry of the body — where one bone ends and another begins, which movements are possible, and which only look acceptable in a flat image. It must distinguish between posture and movement, symmetry and compensation, stability and loss of balance. And all this based on a set of pixels that know nothing about anatomy or physics.
In the early 2000s, the industry honestly acknowledged the complexity of this task and solved it with hardware. Microsoft Kinect was a compromise of its time: depth sensors, infrared projection, a pre-programmed model of the human body. The system did not so much “understand” the pose as guess it within the limits of rigidly defined assumptions. As long as the person stood facing the camera, at the correct distance and in a predictable pose, everything worked. As soon as the scenario went beyond these limits, failures began that could not be corrected by software.
The transition to software solutions seemed like a liberation from these limitations, but it quickly became clear that along with the rejection of specialized equipment, the safety net had also disappeared. Modern human pose estimation AI works with a regular video stream and is forced to independently extract what was previously provided by a depth camera — an understanding of space, volume, and the relative positions of body parts. Errors became less obvious but much more insidious: broken anatomy, unstable joints, and shaky skeletons in frame sequences.
Gradually, human pose estimation ceased to be viewed as a separate technology. It began to be perceived as an auxiliary component — one of the modules in a fitness app, virtual fitting system, or metaverse. This approach is convenient, but it hides a key dependency: it is the quality of the pose estimation that determines whether the product will be something more than a demonstration of the model’s capabilities.
A fitness app may look convincing as long as it counts repetitions. But as soon as it starts to “correct” technique, all the inaccuracies of pose estimation come to light. Virtual fitting may be impressive in a static frame, but it falls apart when in motion. Metaverses can draw detailed avatars that cease to be believable as soon as the user starts moving.
The thesis of this text is formulated without attempting to smooth things over: accurate pose estimation is not an option or an improvement.
How Human Pose Estimation Works (The Mechanics)
When the conversation turns to “how it works,” people usually expect a neat diagram and a linear explanation. In the case of human pose estimation, this approach quickly gives a false sense of simplicity. Under the hood, there is no single algorithm or universal trick — there is a chain of solutions, each of which adds accuracy in one place and creates vulnerability in another. Understanding this mechanism is important not for the sake of theory, but because this is where future product errors are laid.
The Goal: Mapping the Human Body into a Digital Skeleton
If we remove the marketing jargon, the goal of Human Pose Estimation seems rather dry: to turn the human body into a set of numbers. But this is where misunderstandings most often arise. It’s not about points for the sake of points. A digital skeleton is an attempt to capture the limitations of the body, its structure, and its degrees of freedom.
Such a skeleton is always a simplification. It ignores muscles, ligaments, and micro-movements, but at the same time, it must preserve topology: the elbow cannot suddenly “jump” over the shoulder, and the knee cannot behave like a hinge without restrictions. In practice, the task boils down to maintaining the illusion of anatomical integrity in each frame and between frames. And this is where most systems begin to fail.
At the heart of it all is keypoint detection, a fundamental operation in which the model attempts to determine the position of joints based on visual cues. An error in a single keypoint rarely looks critical on its own, but it almost always spreads further, breaking the entire geometry of the skeleton.
Approaches: Top-Down vs Bottom-Up

In recent years, two basic approaches have emerged in the industry, each solving the problem in its own way, with its own compromises that are rarely discussed in promotional descriptions.
The top-down approach is logical and intuitive. First, the system answers a simple question: is there a person in the frame and where are they? The detector forms a bounding box, and inside it, the model attempts to reconstruct the pose by finding key points.
This approach does indeed give more accurate results, especially in controlled scenes. But accuracy comes at a price. Each person in the frame is a separate pass for the model. As their number grows, the system begins to run into computational limitations, delays, and instability in real time. This is why top-down solutions often look brilliant in demos and unexpectedly weak in production scenarios with unstable video and dense movement.
The bottom-up approach goes in the opposite direction. It ignores the concept of “person” in the first stage and first looks for all possible key points in the image. Only then are these points assembled into separate people based on spatial and topological connections. This principle is the basis of multi-person pose estimation.
This approach scales faster and performs better in crowds. But it has another, less obvious problem: when bodies overlap, the model begins to get confused about which limbs belong to whom. The arm is there, the point is found, but which person it belongs to is a question that the algorithm cannot always answer with certainty.
On paper, this looks like a purely engineering choice. In practice, it is a strategic decision that determines what mistakes the product will make consistently and what the team will have to put up with.
Why Keypoint Detection Is Never “Just a Subtask”
In many descriptions, keypoint detection is mentioned in passing, as if it were a secondary element of the system. In real projects, the opposite is true. It is the quality of keypoint detection that sets the upper limit of the accuracy of the entire model and determines how reliably it will work in practice.
The model may be architecturally complex, trained on huge datasets, have advanced attention layers and three-dimensional processing, but if it does not stably determine the position of the pelvis, shoulder girdle, or elbow, the entire skeleton begins to “float.” These errors are rarely noticeable in a single frame — the skeleton seems to “sit” on the body, and it appears that the system is working. But with skeleton tracking, when movement unfolds over time, even small deviations become apparent: joints change position, bone lines become distorted, and movements lose their naturalness.
Experienced engineers working with pose estimation have long since stopped talking about “pose search.” They talk about error control, about how to minimize the destructive inaccuracies that inevitably appear in real video. The mechanics here are not so much about building the perfect body as they are about building stable and predictable movement, where small errors do not destroy the entire analysis.
In addition, the quality of keypoint detection directly affects downstream tasks:
- Movement analysis in fitness apps will be inaccurate if the pelvis or knee is incorrectly identified;
- virtual clothing fitting will be unrealistic if the shoulders are misaligned;
- avatar animation in the metaverse will lose its smoothness if keypoints “jump” between frames.
That is why, in practice, teams combine automatic algorithms with manual validation, use motion smoothing between frames, and carefully control the quality of each keypoint. Without this, even the most advanced model, trained on millions of frames, risks becoming a “toy” rather than a reliable professional-grade tool..
2D vs. 3D Pose Estimation
The distinction between 2D and 3D in human pose estimation is often presented as a matter of complexity or the “next step in evolution.” In practice, these are two completely different ways of looking at motion, each with its own limitations and unexpected challenges that rarely manifest themselves at the prototype stage.

2D Pose Estimation works in the image plane, using only X and Y coordinates. The model sees the body the same way a camera sees it: without depth, without understanding what is closer and what is further away. For many simple scenarios, this is sufficient. Yoga, stretching, basic fitness exercises — anything where the poses are static or slow, and the accuracy requirements are limited to visual correctness. In these cases, 2D gives the impression of reliability: the movements seem correct, the skeleton “sits” on the body, and the user gets instant visual feedback.
However, problems begin to arise as soon as the movement ceases to be flat. Any tilt of the torso, turn, or weight transfer is often lost or misinterpreted. For example, a squat with the torso tilted to the side or a jump with a turn is easy to “break” in 2D. The model may “see” the pose as correct, even though from a biomechanical point of view it is already unsafe: the load is distributed incorrectly, the joints bend at a dangerous angle, and the user receives incorrect advice.
In contrast, 3D pose estimation adds a third coordinate — depth — and with it, the very nature of the analysis changes. The body ceases to be a silhouette and becomes a volume. Now the model is able to see:
- how much the back is tilted and how the center of gravity shifts during movement;
- the depth of the step when running or lunging;
- the amplitude of arm and leg swings, especially during crossing movements;
- the true distance between joints in space, not just on the camera projection.
This is critical for professional sports, where the accuracy of angles and load distribution directly affect the athlete’s performance and safety. For avatar animation, any depth error destroys the illusion of realism. In the Digital Twins concept, where movement must correspond to physical reality, it is simply impossible to obtain a correct digital twin of a person without 3D.
It is important to understand that 3D is not an “improved version” of 2D, but a different class of tasks with different data, different annotation requirements, and its own sources of error. The transition to volume does not automatically solve problems with occlusion, non-standard poses, or overlapping bodies, but it makes possible what is fundamentally unattainable in 2D:
analysis of movement as a process in space, rather than as a set of poses on the screen;
- understanding of load distribution and body symmetry;
- tracking of complex interactions between multiple people in a scene;
- correct integration of movement into 3D avatars, virtual fittings, and digital twins.
In practice, teams working with 3D face a host of new challenges: depth cameras must be calibrated, datasets include more key points, and annotation requires strict rules for each axis. An error in the Z-coordinate often leads to a “floating” skeleton, even if the XY coordinates remain accurate. This explains why the implementation of 3D is always accompanied by additional work on skeletal annotation, manual validation, and high-quality skeleton tracking.
It can be said that 2D is suitable for visually understandable, simple applications, while 3D is suitable for tasks where accuracy, physical correctness, and in-depth motion analysis are important. It is this difference that determines whether a product will be a “toy” or a professional tool for sports, medicine, and the metaverse.
The Role of Data: Skeletal Annotation
Usually, data is discussed in general terms: “we need more data,” “a better dataset,” “the model will train itself.” In human pose estimation, this is misleading. Human pose estimation models do not simply learn to find points in an image. They must learn the topology of the body — that is, understand which parts are connected to each other, which movements are permissible and which lead to a “broken” pose, and how these connections behave dynamically.
Without this knowledge, the skeleton becomes a set of disparate coordinates. Formally, the points may be located correctly, but the body will look strange, unnatural, and the movements illogical. In real applications, this manifests itself in “floating” arms, “jumping” shoulders, and distorted poses when transitioning from frame to frame.
What Topology Really Means
When we say that a model “understands” the body, what we really mean is that it has learned a set of strict rules laid down through skeletal annotation:
- the elbow is always between the shoulder and the wrist;
- the knee cannot change its direction of bend from frame to frame;
- bone lengths remain stable within a single sequence;
- the movements of symmetrical body parts correlate, even if one of them is partially hidden.
These restrictions do not arise on their own. They are formed exclusively through correct annotation. Every error in the connections, every missed point or inaccurate line is automatically transferred to the model, and it is almost impossible to correct this at the architectural level.
Anatomy Formats Used in Practice
There is no universal skeleton in the industry. Different formats are chosen for specific tasks and scenarios:
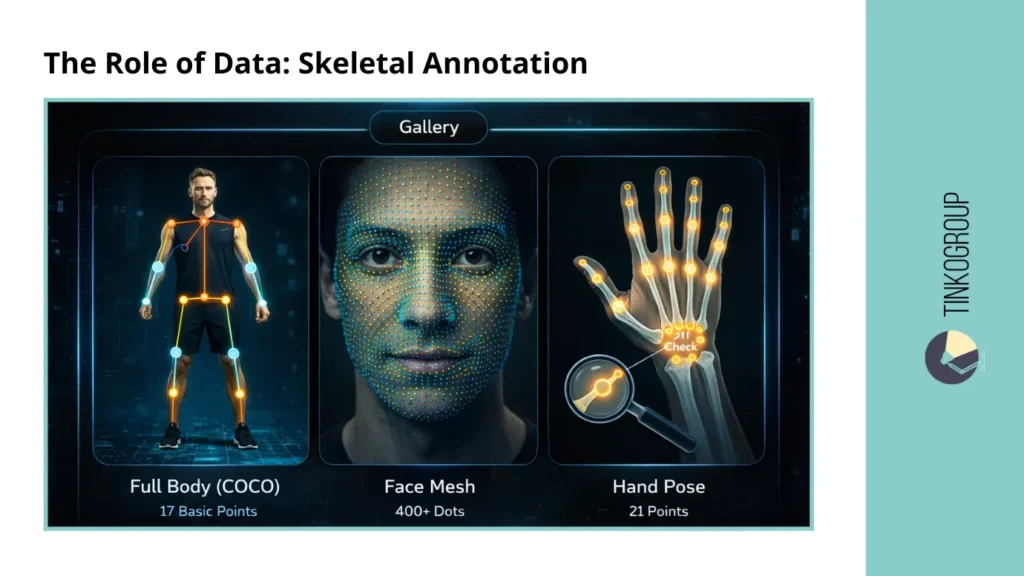
- COCO Format — 17 key points. The basic standard for the entire body, on which most general models are trained. It is convenient, fast, and relatively easy to mark up, but limited in the detail of complex movements.
- Face Mesh — 400+ points. Used where micro-movements are important: AR filters, avatar animation, expression of emotions. Here, every inaccuracy is noticeable, and manual correction is critical.
- Hand Pose — 21 points. A key element for gesture and interface control. Even a small error can lead to misinterpretation of hand movements.
Each format is a separate compromise between accuracy, processing speed, and annotation cost. The choice of format directly affects the capabilities of the product and the limitations of the model.
The Annotation Workflow: Why Humans Still Matter
Automatic annotation rarely does the job completely. Joint connections are especially tricky: the points might be found correctly, but the skeleton lines and their topology often get messed up. That’s why human checking is still a must.
In practice, annotators check and correct:
- the correctness of joint connections (the arm should not “jump” over the body);
- the stability of bone length between frames;
- the continuity of movement during partial occlusion;
- anatomical plausibility in non-standard or extreme poses.
These steps seem simple on paper, but with large video footage and datasets with thousands of frames, they become a real engineering problem. Without careful verification, skeleton tracking turns into a chaotic stream of points, movements look artificial and lose their meaning for analysis.
Every time the team skips even one validation step, the model “remembers” the errors. This explains why even the most advanced architectures can show convincing results on a single frame and break down in real time with dynamic movements or complex scenes. Ultimately, data quality and human annotation are what distinguish a demo prototype from a professional tool.
Challenges in Pose Estimation
When discussing human pose estimation, it often seems like a purely technical task: there is an image, there is a model, there are key points — and everything works. In reality, it is much more complicated. The main difficulty is the chaos of the real world. People move unpredictably, overlap each other, strike unusual poses, lighting changes, the camera moves, and against this backdrop, the model must make conclusions that even an experienced person would not make without context.

Occlusion — Invisible but Important Parts
Partial occlusion is a constant headache. When a limb is hidden behind an object or the body itself, standard algorithms behave extremely erratically. In one frame, the arm is visible, in another it disappears — and the skeleton begins to “float.” Models trained only on visible poses will never learn to correctly predict the position of hidden joints without special annotations.
The industry solution sounds simple in theory: mark “Invisible but present” and adjust manually. In practice, this requires enormous patience and time: annotators must estimate the position of the limb using context, camera angle, and even body physics. The error here is invisible in a single frame, but becomes catastrophic when tracking movement in a video, when the skeleton begins to “break” and create unrealistic movement.
Crowded Scenes — When There Are Too Many People
Another classic problem is scenes with large numbers of people. In sports matches, mass events, or even in fitness centers, limbs often intersect. The model can find all the key points, but cannot understand who they belong to. Limb identification errors are one of the most common problems in multi-person pose estimation.
This is not just a technical challenge. For engineers and development teams, it is a strategic choice: how many people should the system process at once, how to correct point ownership errors, how to reduce the likelihood of “mixed up” limbs, and how to visually display the skeleton correctly when in doubt. Ignoring these issues at the beginning of development almost always leads to disaster in production when users see “flying” arms and legs.
Unusual Poses — Non-standard Movements
Standard datasets almost always contain normal human movements: walking, running, squatting, exercising. But the world is not limited to these movements. Yoga, gymnastics, parkour, dance tricks — these are a completely different level of complexity.
Models trained on standard sets break down on these poses. They either “break” the skeleton or predict impossible joints. For engineers, this means the need to create special pose estimation datasets for such scenarios, manual validation, and constant error control. Sometimes it is necessary to retrain the model on tens of thousands of frames of non-standard movements — and even then, the predictions are not always stable.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Hidden difficulties and the human factor
In addition to technical aspects, there is another, “invisible” side to human pose estimation — the human factor. Even the most advanced model cannot compensate for errors in the data, and these errors most often come from the people who create the annotations.
Annotators get tired, their attention wanders, and the annotation rules are interpreted differently. As a result, the same frame can be annotated differently by different people or even by the same person on different days. Every inaccuracy, missed joint, or incorrect skeleton line is automatically transferred to the model. This means that errors are not “random” — they become an integral part of the system and manifest themselves in any skeleton tracking, especially in dynamic scenes.
In real projects, engineers are forced to develop strategies to compensate for human error:
- Smoothing movements between frames to minimize skeleton jumps;
- Controlling bone length so that they remain stable in the sequence;
- Taking into account body symmetry, especially in cases of partial occlusion;
- Manually correcting individual complex sequences where the algorithm fails.
Even with advanced architectures and large datasets, without attention to the human factor, the system remains unreliable. In practice, it is the competent organization of the marking process and quality control of annotations that make the difference between a demonstration prototype and a professional-grade working tool.
Ultimately, understanding and managing the human factor is not a minor detail, but a critical element in the development of pose estimation models, without which any technical innovations lose their meaning.
Why This Is Critical
All these complexities are not just an academic problem. They determine the actual reliability of the product. A fitness app that “corrects” squat technique will give incorrect advice if one arm is in the wrong position. In avatar animation or the metaverse, an error at a single key point destroys the illusion of movement. And this is where the difference between demonstration prototypes and real working systems becomes apparent: without understanding and managing these issues, the product will never become a professional tool.
Industry Use Cases
The practical application of human pose estimation is where technology ceases to be an abstraction and begins to impact people’s lives. Here, it is no longer important how perfect the model is in the laboratory; what matters is how it behaves in real-world conditions, with real people, with all their quirks, mistakes, and unpredictability.

AI Fitness Trainer
One of the most obvious and sought-after applications has been personal fitness analytics. Apps that correct the technique of squats, lunges, or planks in real time are heavily dependent on the quality of movement analysis. Simply detecting key points is not enough: the system must evaluate the amplitude of movement, body symmetry, center of gravity shift, and exercise speed. An error in one limb or an inaccurate assessment of the knee can turn useful advice into an injury-prone warning.
At the same time, engineers face the same problems mentioned earlier: hand occlusion, leg overlap, and non-standard poses. The system must learn to recognize movements in conditions not covered by the training dataset, and sometimes do so almost at random, relying on physics and body topology.
Professional Sports
In sports, measurement accuracy reaches a whole new level. Golf, running, pole vaulting, skiing — here, any inaccuracy in assessing the angle of the shoulder, the amplitude of the swing, or the placement of the foot becomes critical. Using human pose estimation AI allows coaches to analyze athletes’ technique, identify hidden problems, and optimize movement for maximum efficiency.
But in reality, such projects often fail when it comes to non-standard movements: athletes take unusual poses, overlap with the coach or equipment, and models without specialized retraining simply “lose” their joints. Only by combining 2D and 3D data and carefully working with annotations can results suitable for professional analysis be obtained.
Retail (Virtual Try-On)
Digital clothing fitting is another area where pose estimation is no longer a laboratory experiment. The user must see how the fabric fits the body, how the sleeve moves when the arm is raised, how the fit changes when the torso is turned. Any error in the skeleton or incorrect depth causes the virtual clothing to “float,” cover parts of the body, or look unrealistic.
To achieve this, skeleton tracking, 3D models, and hybrid datasets are used to ensure that movements remain continuous and believable. In the real world, this requires a huge number of frames, manual validation, and constant checking of animations, especially for different body types and poses.
Healthcare
Pose estimation plays a vital role in healthcare. Monitoring recovery after a stroke, checking the gait of elderly people, detecting falls — all these tasks depend on a stable, accurate skeleton. An error at a single key point here can lead to an incorrect assessment of progress or a missed fall, making the system potentially dangerous.
Engineers must carefully tune algorithms, verify the quality of skeletal annotation, and account for all possible non-standard patient poses. Human validation remains a critical element in this field — no fully automated process can yet replace an attentive observer.
Conclusion
When it comes to human pose estimation, it’s easy to get carried away by beautiful demos and promises of real-time performance. Everything may look convincing on the screen: avatars repeat movements, fitness apps count repetitions, and virtual clothing try-ons seem almost real. But the real test comes when the system encounters the chaos of real life: unexpected poses, overlaps, poor lighting, and non-standard movements.
The difference between a toy app and a professional tool is determined by the quality of the pose estimation models and the depth of the data on which they are trained. Even the most advanced model architecture is powerless if the skeleton annotation contains errors, if there is no control over occlusions, or if the data does not cover the real range of movements. It is the understanding of these limitations, constant testing, and careful work with human markup that make the product stable, reliable, and ready for the real world.
Real teams know that technology here is not magic, but the result of tens of thousands of frames, hundreds of hours of annotation, and continuous testing. It is impossible to ignore this process.
If your goal is to create a stable product in the field of computer vision, the Tinkogroup team helps build and scale pose estimation systems: from high-quality datasets to production-ready models.
Why is 3D Pose Estimation better than 2D for sports and fitness apps?
While 2D analysis works on a flat X-Y plane, it often fails during torso tilts or center of gravity shifts. 3D Pose Estimation adds the depth (Z-coordinate), allowing the system to track the true distance between joints and body symmetry. This is crucial for providing accurate feedback in professional sports where biomechanical correctness is vital.
What is the main challenge in multi-person pose estimation?
The biggest hurdle is “disentangling” limbs in crowded scenes. When people overlap or interact closely, the AI may struggle to identify which arm belongs to whom. This requires advanced processing and high-quality skeletal annotation to maintain anatomical integrity in dense environments.
How does the “skeleton rulebook” improve model accuracy?
The “rulebook” or body topology defines strict anatomical constraints—for example, bone lengths must remain stable, and joints cannot bend in impossible directions. By teaching the model these rules during annotation, we prevent “broken” skeletons and ensure that movement looks natural and remains stable across video frames.


