

Over the past two decades, the field of computer vision has undergone significant changes. In the early stages of development, the focus was on video classification and object recognition: the system answered the question “Who is there?” — for example, a man or a car in the frame. Such approaches made it possible to create basic video surveillance systems and simple analytical solutions, but they could not understand what exactly was happening in the scene.
With the advent of complex neural network models and deep learning, the focus shifted to video event annotation — a task where AI must understand “What is happening?” Example: not just “a person is standing at the counter,” but “He is picking up an item and putting it back,” which is important for smart retail and cashierless store automation.
The thesis of the article is that in order to build intelligent systems — whether it’s security footage analysis, sports analytics, or retail — it is necessary to teach models to work with temporal information, context, and cause-and-effect relationships. Simply using action recognition or activity recognition on individual frames is not enough: modern systems require an understanding of temporal intervals, accurate determination of start and end timestamps, and the ability to recognize complex events through complex event processing.
In video surveillance and AI systems for sports, it is important not only to identify an object, but also to understand its behavior (behavior analysis). For example:
- In security footage analysis, detecting a person with a suspicious object has different meanings depending on whether they are simply passing by or attempting to commit theft.
- In sports analytics, activity recognition and action recognition allow you to automatically generate key moments of the match: goals, fouls, passes, saving analysts hours of manual work.
- In smart retail, accurately recording customer actions using AI video annotation and spatio-temporal annotation allows us to understand customer patterns: what was taken from the shelf, what was returned, and how this affects recommendations and logistics.
Thus, video event annotation is not just a task of marking objects in time; it is the key to AI understanding cause-and-effect relationships and being able to draw conclusions based on observed actions.
The Core Concept: Spatial vs. Temporal Annotation
One of the key differences in modern video annotation is the separation of spatial and temporal approaches. Understanding this difference is fundamental to all video event annotation tasks, including AI video annotation, action recognition, activity recognition, and temporal action localization.
Spatial annotation captures objects in individual frames using bounding boxes, providing the model with information about “where” the object is in space, but not what it is doing or for how long.
Temporal annotation adds a time dimension by capturing start and end timestamps and temporal intervals, allowing models to understand the sequence of actions and the context of events. It is the combination of spatial and temporal information — spatio-temporal annotation — that enables accurate behavior analysis, teaching AI to see not just objects, but the dynamics of what is happening, recognizing atomic actions, activities, and complex events.
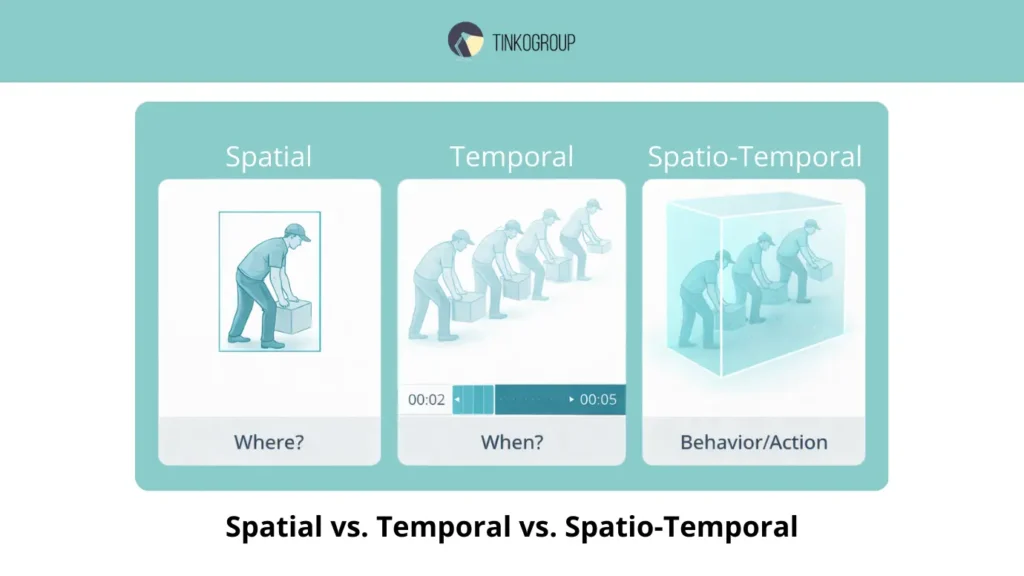
Spatial Annotation: Static Measurement
Spatial annotation is traditionally associated with bounding boxes — marking objects in a single frame. This technique is effective for video classification: the system knows where the object is located, but has no information about its actions or duration.
Pros:
- easy to implement;
- suitable for object recognition and segmentation tasks;
- used in basic video surveillance systems.
Cons and limitations:
- temporal context is ignored: the system does not understand what happens before or after the current frame;
- behavior analysis is impossible: for example, recognizing whether a person is trying to steal something or just walking by;
- limited use in complex scenarios: sports analytics, complex event processing, smart retail.
A classic example: a person picks up an item from a shelf in a store. Spatial annotation will mark “person + object,” but will not record the action “Picked up item” vs. “Put back item,” which makes the data of little value for training AI in the context of real behavior.
Temporal Annotation: Adding Time Measurement
Temporal annotation expands the capabilities of AI by recording start and end timestamps for each action or event. For example, an annotation might look like this: Start Time 00:05 → End Time 00:10, which allows the system to understand the duration and sequence of actions.
Advantages of temporal annotation:
- allows temporal action localization models to determine the exact start and end of actions;
- creates context for activity recognition: the system sees the sequence of atomic actions and can output complex events;
- improves the quality of behavior analysis, especially in security footage analysis and sports analytics.
Critical point: simply measuring time is not enough. Developing annotation rules is a key step in avoiding errors:
- When does an action begin? For example, does a fall begin when balance is lost or when contact with the surface occurs?
- How do you record complex events involving multiple objects simultaneously?
Errors at this stage directly affect the quality of AI video annotation: incorrectly marked temporal intervals will lead to action recognition failures and incorrect conclusions about behavior.
Integration of Spatial and Temporal: Spatio-temporal Annotation
For many industrial applications, the optimal solution is spatio-temporal annotation, which records both coordinates and time frames simultaneously:
- “where” and “when” the action takes place;
- provides the most detailed context for AI;
- allows you to build complex models of complex event processing, for example: in sports analytics, recording the player, ball, and duration of a pass, shot, or foul; in security footage analysis, tracking the movement of a suspicious person and their actions with objects.
The ability to combine spatial and temporal information makes it possible to train models that can see not just objects, but the dynamics of events, predict consequences, and perform accurate behavior analysis.
Action vs. Activity vs. Event (The Hierarchy)
For comprehensive video event annotation, it is important to understand the hierarchy of actions in a video. A modern system must not only see objects, but also interpret their behavior on three levels: atomic action, activity, and complex events.
Each level has its own value and complexity for AI: atomic actions form the basis for action recognition, activities combine sequences of movements for activity recognition, and complex events include scenarios with context that are important for complex event processing and accurate behavior analysis. Understanding this hierarchy is necessary for models to correctly recognize actions and events, record temporal intervals and start and end timestamps, and use spatio-temporal annotation to train reliable systems.
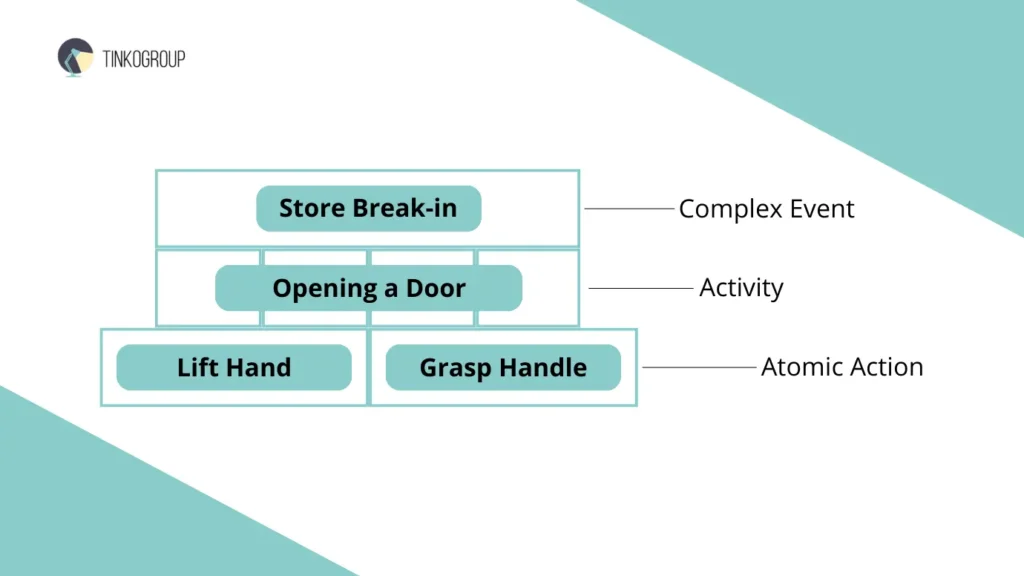
Atomic Action: the Smallest Unit of Movement
Atomic Action is a basic action that can be observed at the level of a single frame or a short time interval. Examples:
- raising a hand;
- picking up an object;
- turning the head.
These actions do not have high business value on their own, but they are the foundation for building more complex scenarios.
Key points and criticism:
- Systems focused solely on action recognition often confuse similar movements. For example, “raising a hand” in sports can be a gesture of greeting, while in a store it can be an attempt to hide an item.
- Without the context of temporal intervals and start and end timestamps, the same action can be misinterpreted.
- For industrial applications (e.g., security footage analysis), recording individual actions is not enough: you need to see their sequence.
Activity: Sequence of Actions
An activity is a set of atomic actions combined into a pattern that makes sense in context.
Examples:
- running;
- picking items from a shelf repeatedly;
- passing a ball in football.
This is where activity recognition comes into play. The model must be able to distinguish between sequences of movements and identify patterns.
Real-life cases and criticism:
- In sports analytics, the system must distinguish between “light running” and “sprinting towards the goal,” which affects the analysis of player performance.
- In Smart Retail, “picking up an item” and “putting it back” are two different activity recognition patterns that are critical for understanding customer behavior.
- Errors in temporal interval annotation cause AI to perceive an action as longer or shorter, which distorts behavior analysis.
Complex Event: a Scenario with Context and Business Value
A Complex Event is the highest level of the hierarchy, where actions and activities are combined into a scenario with high business or security value.
Examples:
- a penalty kick in football;
- shoplifting in a store;
- abandoned luggage in airport security.
Features and challenges:
- For such events, accurate spatio-temporal annotation is critical for AI to understand who is involved, what actions preceded the event, and how they are related.
- Errors in temporal action localization at this level can lead to important events being missed or false alarms, which is unacceptable in security footage analysis systems.
- To build a reliable model, it is necessary to combine action recognition, activity recognition, and complex event processing, otherwise AI sees “movements” without context.
Key Conclusions
- Atomic Actions are the basis for all analysis, but are of little value to business on their own.
- Activity is the first level of understanding the sequence of actions and requires accurate annotation of temporal intervals and start and end timestamps.
- Complex Event is what provides value in real-world systems: sports, retail, security; it requires the integration of all levels and spatio-temporal annotation.
This hierarchy shows why video event annotation is not just video marking, but a complex task that includes AI video annotation, behavior analysis, and complex event processing.
The Annotation Workflow: Identifying Boundaries
For successful video event annotation, it is not enough to simply understand the hierarchy of actions and distinguish between atomic actions, activities, and complex events. Competent organization of the annotation process itself plays a key role, especially when it comes to accurate temporal action localization, the use of spatio-temporal annotation, and the recording of correct start and end timestamps.
It is the correct workflow that allows annotators to effectively identify the beginning and end of actions, synchronize data between the team, and create high-quality ground truth for training AI models. Errors at this stage, such as inaccurately marked temporal intervals or inconsistencies between annotators, can lead to misinterpretation of actions and reduced accuracy of behavior analysis, action recognition, and activity recognition.
A well-designed and standardized workflow ensures consistency in labeling, minimizes subjectivity, and lays the foundation for reliable complex event processing, which is especially important for industrial applications in security footage analysis, sports analytics, and smart retail.

How Annotators Work
Experienced teams of annotators perform the following steps:
- Video viewing — careful analysis of the scene with a focus on objects and their actions. Here, attention to detail is important, as the AI algorithm is not yet able to distinguish between them.
- Pausing at key moments — recording the potential start or end of an action. This is important for AI to correctly construct temporal intervals.
- Logging time boundaries — recording start and end timestamps for each annotated activity or event.
This process seems obvious, but in practice it requires strict discipline and experience. Each annotator must be able to interpret the context of an action: for example, determine when “picking up an object” becomes “theft” in a security footage analysis scenario, or when a series of passes forms a complex event in sports analytics.
The Problem of Boundary Ambiguity
One of the main difficulties is boundary ambiguity — the uncertainty of where an action begins and ends.
Example: Fall.
- The beginning: the moment when a person loses their balance?
- End: when they fully touch the ground?
- What if there are intermediate movements, such as an attempt to grab hold of something?
Without strict synchronization, a team of annotators may record boundaries differently, leading to inconsistencies in AI video annotation and reduced accuracy in action recognition and activity recognition.
Such difficulties are especially critical for complex event processing and behavior analysis in the real world. For example:
- In security footage analysis, an incorrectly recorded moment of a fall can lead to a missed alarm or a false alarm.
- In sports analytics, if temporal intervals are recorded inaccurately, AI may incorrectly assess the effectiveness of players’ actions.
The Need for Strict Rules
To overcome Boundary Ambiguity, teams use Annotation Guidelines — detailed instructions, standards, and examples for consistent definition of the beginning and end of an action.
Elements of strict rules:
- clear definitions of atomic actions, activities, and complex events;
- instructions on how to interpret ambiguous scenes;
- mandatory use of spatio-temporal annotation to synchronize coordinates with time;
- regular annotation quality checks and cross-validation.
These rules are not just a formality: they ensure data consistency, which is critical for training AI video annotation models with high accuracy.
Without a clear procedure and consistent standards, video event annotation loses its meaning. Annotators not only provide ground truth, but also form the foundation for accurate temporal action localization, behavior analysis, and effective complex event processing.
Types of Temporal Annotation
In video event annotation practice, there are several types of temporal annotation, each with its own purpose, complexity, and value for AI. Understanding these types is critical for accurate temporal action localization, behavior analysis, and building AI video annotation systems.
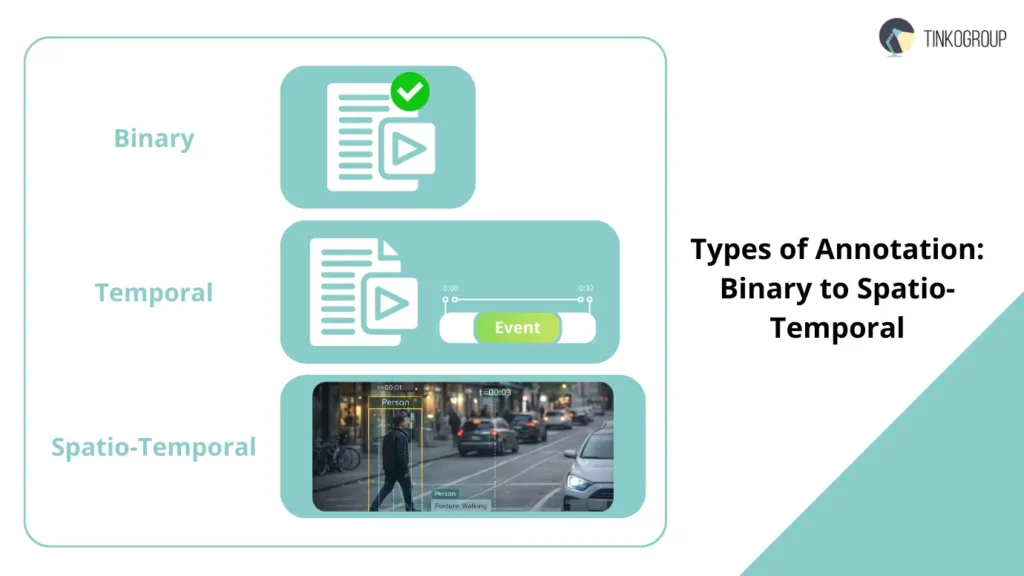
Binary Classification
Binary Classification is the simplest type of annotation. The annotator answers the question: “Is this event in the video? Yes/No.”
Examples:
- “Is there a fight in this video?”
- “Is there abandoned luggage in this clip?”
Advantages:
- easy to perform;
- used for preliminary video filtering;
- allows you to quickly collect a dataset for training basic video classification models.
Limitations:
- start and end timestamps are not recorded, so AI does not know the duration of the action;
- cannot be used for complex event processing;
- only suitable for rough content assessment, but of little value for security footage analysis or sports analytics tasks where context and exact event timing are important.
Criticism. For industrial AI focused on the precise behavior of objects, binary classification is often too primitive. It does not allow for in-depth behavior analysis or training models to understand complex sequences of actions.
Temporal Detection
Temporal Detection records not just the fact that an event has occurred, but its exact boundaries: “Where exactly is the fight?” (01:15–01:40).
Advantages:
- allows AI models to see the duration of actions;
- creates a basis for activity recognition and temporal action localization;
- more useful for complex event processing, where time is critical.
Challenges:
- determining the start and end of an action often causes boundary ambiguity;
- different annotators may record start and end timestamps differently, especially for actions with a smooth start or end;
- requires strict rules and cross-checking of data, otherwise AI will be trained on “noisy” time intervals.
Example: In sports analytics, when recording a series of passes, AI must see not only the moment of ball contact, but also the entire sequence of the action. An error of even 1–2 seconds can lead to an incorrect assessment of the result.
Spatio-Temporal Annotation
Spatio-temporal annotation is the most detailed and expensive type of annotation, where both “where” and “when” an action occurs are recorded:
- “where is the fight AND draw a box around the people fighting”;
- the coordinates of the object are combined with start and end timestamps;
- used to train advanced AI video annotation systems capable of performing in-depth behavior analysis.
Advantages:
- full integration of spatial and temporal information;
- suitable for complex cases: security footage analysis, sporting events, smart retail;
- allows you to build models for complex event processing, where both participants and sequence of actions are important.
Challenges and criticism:
- requires significant resources: trained annotators, expensive tools;
- any error in spatio-temporal annotation affects the accuracy of action recognition and activity recognition;
- objects can overlap and actions can occur in parallel, which increases the risk of incorrect labeling;
- large projects require strict standardization of rules and multiple data validation.
Example: In security footage analysis, when an attempted theft is recorded, AI must see not only the person with the object, but also their path of movement, time spent in the area, and interaction with other people. This is the only way to build a reliable incident recognition algorithm.
Key Findings
Binary Classification is suitable for quick video filtering, but is of little value for high-accuracy AI training.
Temporal Detection adds critical information about the time of action and serves as the basis for temporal action localization and activity recognition.
Spatio-temporal annotation provides full context and is an essential tool for training AI video annotation models, enabling complex behavior analysis and complex event processing.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Industry Use Cases
The effectiveness of video event annotation is only evident in real-world industrial scenarios, where AI models encounter a variety of human behaviors and complex environments. Below are key areas of application with examples, challenges, and integration of action recognition, activity recognition, spatio-temporal annotation, and behavior analysis.
Security & Surveillance
In security systems, it is critical not only to record the presence of people, but also to understand their actions in context — the key task of security footage analysis.
Examples of events:
- detecting violence — fights, aggressive actions;
- abandoned luggage — objects left unattended;
- intrusion — entering restricted areas.
Challenges and criticism:
- AI can recognize movement, but without temporal action localization and accurate start and end timestamps, it does not understand what specifically happened;
- false positives are possible in complex scenes: people crowding together, objects overlapping each other;
- reliable operation requires strict spatio-temporal annotation so that the algorithm sees not only objects, but also their actions in context.
Real-life case: At an airport, a system with AI video annotation detected abandoned luggage. Without correct annotation of temporal intervals, the system responded with a delay, demonstrating the importance of accurately recording time boundaries and training on high-quality data.
Sports Analytics
In the sports industry, video event annotation and activity recognition are used to automatically tag key moments in matches.
Examples:
- every pass, shot on goal, foul, or goal;
- automatic creation of highlights and analytical reports for coaches and teams.
Challenges:
- player actions occur quickly, often in parallel;
- errors in start and end timestamps can lead to incorrect identification of key moments;
- accurate analysis requires the integration of action recognition, activity recognition, and complex event processing.
Example: When analyzing a soccer match, AI recorded a pass, but without correct spatio-temporal annotation, it lost information about who exactly received the ball, which reduced the value of the analytics.
Smart Retail
Modern cashierless stores, such as Amazon Go, use AI video annotation to track customer actions. Examples of actions:
- picked up item — picked up an item;
- put back an item — returned an item to the shelf.
Challenges:
- it is difficult to distinguish between these actions due to the dense arrangement of people and objects;
- accurate spatio-temporal annotation is required for ai to see both the object and the person at the same time;
- any error in temporal intervals leads to incorrect interpretation of actions and reduces the quality of behavior analysis.
Real-life case: In an experimental store, the system incorrectly recorded the return of an item to the shelf, which revealed the need for strict annotation and quality control rules.
Healthcare
In healthcare, video event annotation is used to monitor elderly people and detect falls.
Examples:
- fall detection — recording the moment of loss of balance;
- activity tracking within activity recognition to assess physical activity levels.
Challenges and criticism:
- falls may be partially obscured by objects or other people;
- the start of the fall and contact with the surface must be accurately recorded using start and end timestamps;
- for AI training, it is critical to correctly mark temporal intervals and use spatio-temporal annotation, otherwise the system may miss a dangerous event or cause a false alarm.
Example: In a nursing home, the system recorded a fall with a delay due to an incorrect start of the temporal interval, which highlighted the importance of strict annotation for reliable behavior analysis.
So:
- Security footage analysis requires a precise understanding of human actions, especially during high-risk events.
- Sports Analytics needs to integrate action recognition, activity recognition, and complex event processing for reliable match analysis.
- Smart Retail demonstrates the value of AI video annotation for understanding customer actions and behavior.
- Healthcare demonstrates that without accurate annotation of time intervals and coordinates, AI can be ineffective.
These cases show that video event annotation is not just frame marking, but complex work with spatio-temporal information for real industrial tasks.
Why Humans are Essential (Context Matters)
Despite advances in AI video annotation, modern models still face limitations in understanding context. They can perform accurate action recognition and activity recognition, recognize objects and sequences of actions, and record temporal intervals and start and end timestamps, but they are often unable to distinguish between behaviors that are visually similar but have different meanings and consequences.
For example, one person may be running in a park — a sporting activity — while another may be running away from a secure area in an attempt to escape. For AI, the visual data is almost identical, but the interpretation of these actions is radically different, especially for security footage analysis tasks.
This is where experienced human annotators play a key role. They provide the accurate ground truth needed to train AI, distinguishing subtle behavioral nuances, such as “picked up an item from a shelf” vs. “hid an item” in smart retail, or “foul” vs. “natural fall” in sports analytics. Human annotation also ensures the correct use of spatio-temporal annotation, when it is necessary to simultaneously record the coordinates of objects and the time boundaries of actions, and supports complex event processing scenarios, where several actions are combined into a business-valuable case.
Without human involvement, AI risks producing false positives or missing important events. In sports analytics, errors in activity recognition and temporal action localization can lead to inaccurate assessments of player performance and strategies. In smart retail and healthcare, incorrect annotation of temporal intervals and inaccurate behavior analysis can result in financial losses or risks to human health.
Thus, the human role in video event annotation remains irreplaceable. Experience, the ability to consider context, and analyze complex interactions between objects allow for the creation of high-quality ground truth, on which AI learns to correctly distinguish between atomic actions, activities, and complex events, perform accurate behavior analysis, and effectively carry out complex event processing and temporal action localization. Without this, systems remain limited in their understanding of what is happening, despite advances in video annotation AI and spatio-temporal annotation.
Conclusion
Video is four-dimensional data: three spatial dimensions plus time. Video event annotation requires not only attention and accuracy, but also a deep understanding of context, sequence of actions, and cause-and-effect relationships between them. Each action, each Atomic Action, each Activity, and each Complex Event must be accurately marked using spatio-temporal annotation, precise start and end timestamps, and correctly defined temporal intervals so that AI can perform reliable behavior analysis, action recognition, activity recognition, temporal action localization, and complex event processing.
Modern solutions in the fields of security footage analysis, sports analytics, smart retail, and healthcare show that without high-quality data annotation, it is impossible to build systems that understand events the way humans do. Manual annotation by experts provides the necessary ground truth, allows models to be trained, minimizes errors, and creates highly accurate AI video annotation algorithms.
For companies seeking to implement advanced action and event recognition technologies, Tinkogroup offers professional video event annotation services, including a full cycle of spatio-temporal annotation, action recognition, activity recognition, complex event processing, and data quality control. For more details and to order the service, please visit the Tinkogroup video annotation services page. This will allow you to create a reliable foundation for any AI applications that require a deep understanding of video and object behavior.
What is the difference between action recognition and activity recognition?
Action recognition usually focuses on short, “atomic” movements observed in a single frame or a brief sequence, such as “waving” or “picking up an object.” Activity recognition is more complex; it identifies a series of these actions that form a meaningful pattern over time, like “playing football” or “shopping in a store.”
Why is spatio-temporal annotation more effective than simple bounding boxes?
While simple bounding boxes only show where an object is located in a single frame, spatio-temporal annotation tracks both the location and the time boundaries of an action. This allows AI models to understand the dynamics of a scene, recognize sequences of events, and perform deeper behavior analysis that static measurements cannot capture.
What is boundary ambiguity in video event annotation?
Boundary ambiguity refers to the difficulty of pinpointing exactly when an action starts and ends. For example, does a fall begin the moment someone loses balance or when they hit the floor? To ensure high-quality training data, teams must follow strict guidelines to minimize subjective interpretations and ensure all annotators mark these timestamps consistently.


