

Over the past twenty years, chatbots have changed significantly. Previously, they operated according to simple and strict rules. Now they have become smarter and more complex. Their programs have become more accurate. And teaching them has become easier.
But one problem remains. People do not talk to bots in single words. They speak in whole sentences. They clarify things. They change their minds right in the middle of a conversation. Sometimes they ask for several things at once in a single sentence.
This makes it difficult for chatbots to understand people. People speak in their own way, but the system only understands its own parameters. And that is why bots often make mistakes.
In production projects, this becomes apparent quite quickly. The user writes: “Find me tickets to Berlin for next Friday evening. But if it’s too expensive, check Saturday morning.” The system can correctly determine the general intent, such as searching for a flight. But if it does not extract specific details — the destination city, date, alternative condition, and time constraint — the command will not be executed as the user expects. The error occurs not because the model is “not smart”. But because it has not been trained to structure the input data correctly.
This is where slot annotation comes into play. It is not just text markup or a variation of basic entity annotation. It is a process during which the system is shown which elements of the user’s statement are operational parameters. The date, amount, address, size, product name — all of these become slots, which are then used by the NLP slot filling mechanism to perform an action. In essence, the developer creates a schema into which each sentence must be converted. Without such a schema, natural language understanding (NLU) remains at the level of meaning recognition. But it does not reach execution.
Experience in implementing corporate dialogue systems shows that most failures occur at the slot extraction stage. The intent may be determined correctly. But the slots are marked inconsistently or incompletely. In one banking project, the model accurately determined the presence of a monetary amount in the request. But confused the role of this amount: in some cases it referred to a transfer, in others to a balance request. The problem was not in the intent classification algorithm. But in fact, the chatbot training data contained ambiguous markup and did not take into account the strict relationship between intent and parameters.
It is important to understand that slot annotation is not just a type of AI text labeling. It is structural semantic annotation focused on performing a specific action. If entity tagging answers the question “what is this entity,” then slot annotation answers the question “what function does this entity perform within the current intent.” In dialogue systems without a clear entity role, it is impossible to ensure correct behavior. A location can be a city of departure or a city of destination, and an amount can be a limit or an actual payment value. Only through contextual understanding and a strict intent and slot filling scheme does the system begin to work predictably.
Practice shows that the quality of conversational AI datasets directly determines the behavior of the model in real scenarios. Even modern transformer architectures cannot compensate for chaotic markup. If the dataset lacks consistent slot value normalization, if synonyms are treated differently, if annotators interpret the same pattern differently, the model will reproduce this inconsistency. As a result, the business gets an unstable system that “understands in general”. But it regularly makes mistakes in the details.
The thesis, which has been confirmed by many years of experience in implementing NLU systems, remains unchanged: without high-quality slot annotation, even the most advanced model is unable to reliably execute commands. The model may demonstrate impressive results on test samples, but in production, everything depends on the accuracy of the parameters. Dialog systems are not about beautiful answers, but about correct actions. And action begins with a correctly marked slot.
What is Slot Annotation? (The Core Concept)
Slot annotation is the process of marking specific words or fragments in a sentence that serve as parameters for subsequent system actions. Within the intent and slot filling architecture, each user query is converted into a structured form: first, the intent is determined, then the values of the variables necessary to perform the operation are extracted. These variables are called slots.
Strictly speaking, a slot is a named parameter of business logic. It exists not for linguistic analysis, but for command execution. Unlike general entity tagging, where the task is to determine the type of entity (e.g., Location or Person), slot annotation fixes the functional role of that entity within a specific intent. This is a key difference that is often underestimated by teams new to working with conversational AI datasets.
Let’s consider a simple example. Sentence: “Book a flight to Berlin for next Friday.”

In this case, the model first determines the intent, for example, Book_Flight (intent classification task). Next, the slot extraction mechanism is launched. During the Slot filling process, the NLP system must identify the parameters necessary to complete the booking operation.
Slots:
- Destination = Berlin
- Departure_Date = next Friday
After that, the bot does not simply “understand” the request. It fills in the internal data structure. These slots are converted into a machine-readable format (like {“dest”: “BER”, “date”: “2026-02-20”}) and passed to the booking system API, where Destination becomes the route search argument and Departure_Date becomes the time filter.
It is important to emphasize that a slot is not a word as such, but the value of a variable. Therefore, slot value normalization is critically important in industrial practice. For example, “tomorrow” must be converted to a specific calendar date, taking into account the current time, time zone, and business logic of the service. Without parameter normalization, even correctly executed semantic annotation does not guarantee correct operation.
Experienced engineers view slot annotation as an interface between human language and the business operating system. Natural language understanding (NLU) can determine the general meaning of a phrase. But without accurately filling in the slots, the command remains incomplete. A bot does not make reservations “somewhere sometime” — it requires specific arguments.
Therefore, in high-quality chatbot training data, slots are designed in advance as part of the domain schema. Annotation is carried out strictly in accordance with this schema, and each example in the dataset is checked for consistency between intent and parameters. Only with this approach does intent and slot filling transform from a theoretical concept into a reliable mechanism for executing user requests.
Entity Annotation vs. Slot Annotation: Deep Dive
In the practice of building dialogue systems, the difference between entity annotation and slot annotation is fundamental. Although both approaches relate to AI text labeling tasks, their goals and operational value differ.
Entity annotation is a broader process of marking “objects” in text. It answers the question: what is this entity? In entity tagging, annotators mark categories such as Person, Organization, Location, Product, Date, and others. For example, in the sentence “Send the contract to Microsoft in London,” the word “Microsoft” would be labeled as Organization, and “London” as Location. This is the fundamental level of semantic annotation, which is used in information retrieval systems, search engines, and analytical tools.
However, this is not enough for chatbots and natural language understanding (NLU) systems. A dialogue system must not only recognize entities. It must also understand their functional role within a specific action. This is where slot annotation comes in as a narrower and more applied layer of annotation.
The relationship between them can be described as follows: slot annotation is essentially contextualized entity annotation. If entity annotation fixes the type of entity, then slot fixes its role within the intent.
Let’s consider the example of “London.” Out of context, it is always a location. Regardless of the sentence, entity tagging will consistently assign the category of location to this word. But in a dialogue system, this is not enough.
- In the phrase “Fly from London,” the word “London” acts as the origin slot.
- In the phrase “Fly to London,” it is the destination slot.
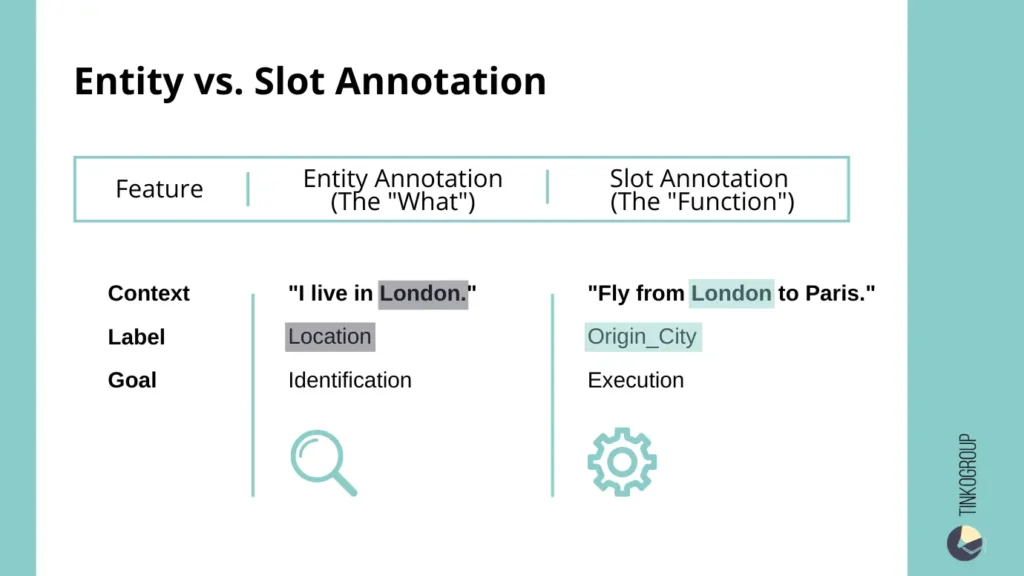
From the point of view of entity annotation, nothing has changed. It is still a location. But from the point of view of slot extraction, everything has changed. The system must distinguish the direction of movement, otherwise it will incorrectly form a request to the booking API.
That is why the architecture of intent and slot filling requires a more rigorous scheme than just a set of entities. Intent classification defines the action (e.g., Book_Flight), and then slot filling NLP extracts the parameters corresponding to that action. If you only mark entities without specifying their role, the model will know that there is a city in the text. But it will not understand what to do with that city.
Practical experience shows that teams that limit themselves to entity annotation when creating conversational AI datasets encounter a high rate of logical errors in production. In one travel-tech project, the system correctly identified cities in 95% of cases. But in almost 18% of queries, it confused the city of departure with the city of destination. The reason was that the chatbot training data did not contain explicit role markup — only the Location category.
For dialogue systems, it is important not just to recognize “things”. But it is necessary to understand their function. This is the key difference. The entity annotation is responsible for classifying entities, while slot annotation is responsible for their operational interpretation. Without specifying the role of an entity, it is impossible to ensure correct contextual understanding and predictable execution of actions.
That is why, in industrial practice, slot annotation is considered a mandatory layer on top of entity annotation. An entity is a language object. A slot is an argument of business logic. The chatbot needs the second one.
Types of Slots to Annotate
In industrial practice, slot annotation is not limited to a single type of parameter. Different categories of slots require different strategies for marking, verification, and subsequent processing in slot filling NLP systems. Experience with conversational AI datasets shows that competent slot classification critically affects the accuracy of actions and the stability of chatbot training data.
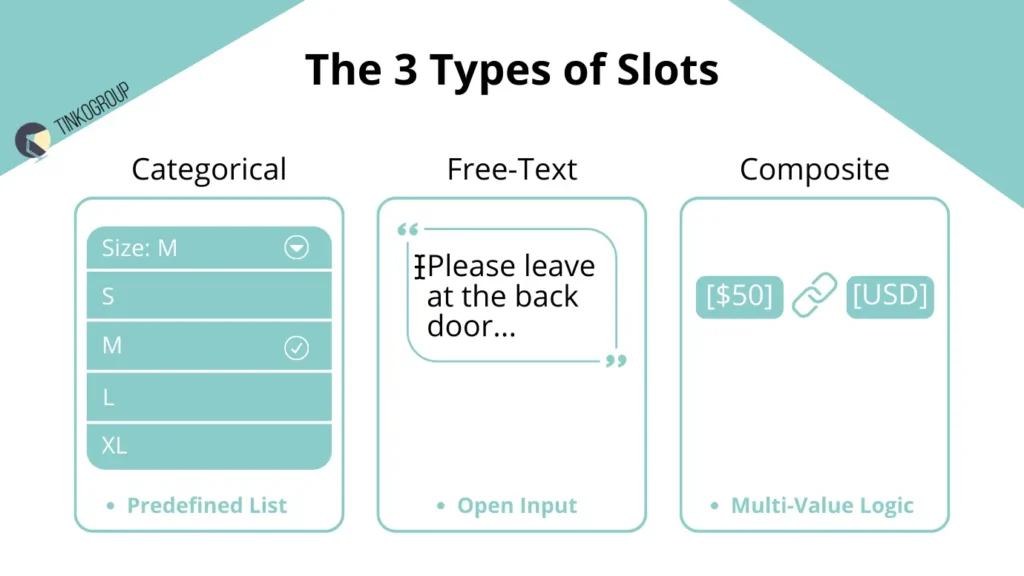
Categorical slots are fields where you can only choose from a predefined list. For example, clothing size: S, M, or L. Or delivery method: standard or express. It could also be a product category, such as pizza toppings. It is very important to only choose from the list. You cannot come up with new options. If someone adds their own value, the model will get confused. It will start learning incorrectly and will make mistakes.
For example, in one clothing store, the size “XL” was recorded separately, which was incorrect. Because of this, the system made mistakes in 12 out of 100 cases when people chose a size.
Free-Text Slots are open fields in which users can enter any data, such as message text, delivery address, or order comments. Marking up such slots requires special attention to data normalization and standardization. In industrial practice, slot value normalization is used to convert text values to a single format. For example, the addresses “10 Lenin Street” and “Lenina 10” must be interpreted as the same value for the delivery system to work correctly. Without normalization, Free-Text Slots create a huge load on downstream processes and increase the likelihood of failures.
Composite Slots are complex structures that combine several elements into a single logical parameter. A classic example is a monetary amount with currency: “50 dollars” is broken down into Amount = 50 and Currency = USD. Another example is date and time: “next Friday at 5 p.m.” becomes Date = [specific date] and Time = 5 p.m. Such slots require advanced semantic annotation and a clear connection to intent, because an error at this level directly affects the correctness of the query execution. In a real-life case study of a large travel project, incorrect marking of the composite slot “amount + currency” led to 4% of false bookings with the wrong currency, which caused budget overruns and user dissatisfaction.
Experience shows that competent division of slots into Categorical, Free-Text, and Composite allows you to:
- reduce the number of errors at the slot extraction stage,
- simplify QA and consistency control,
- ensure correct downstream logic operation,
- increase the accuracy of intent and slot filling even in complex multi-step dialogues.
Engineers with 20 years of experience emphasize that the marking strategy must be integrated with the chatbot training data architecture. All slots must be synchronized with intents, have normalized values, and correspond to the general contextual understanding scheme so that the system performs actions predictably and consistently.
The Annotation Workflow & Challenges
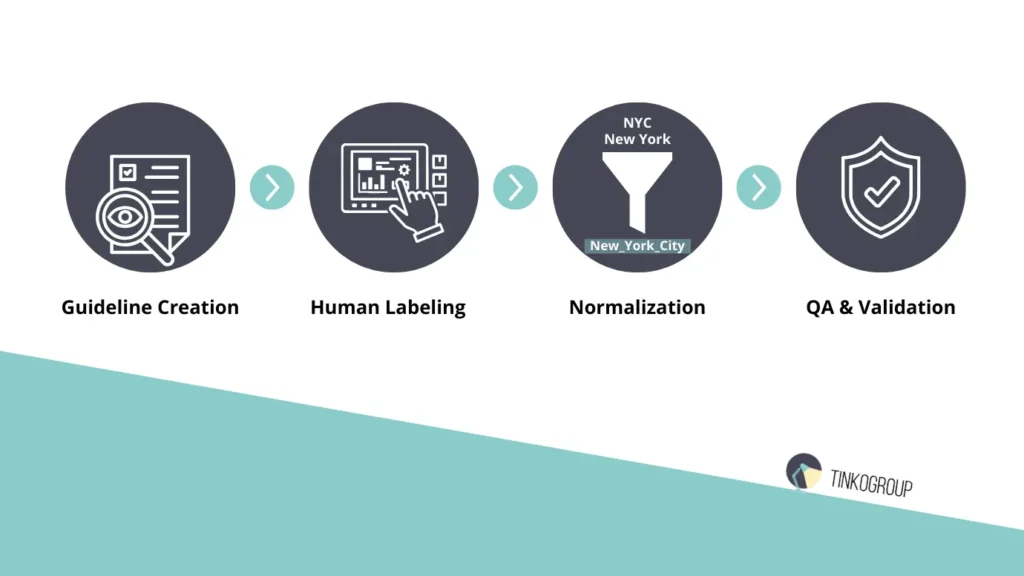
Creating high-quality conversational AI datasets is not simply a matter of highlighting words in a text. In practice, experienced engineers note that successful annotation requires a rigorous, multi-level workflow that includes preparing guidelines, training annotators, quality control, and constant interaction between the team and the product side. The main difficulties along the way are related to ambiguity, dependencies between slots and intents, and maintaining consistency in annotation.
One of the key challenges is ambiguity — the ambiguity of words and expressions. Users often use the same words with different meanings depending on the context. For example, the word “Apple” can mean a fruit or a corporation, and “May” can mean a month or a modal verb. In dialogue systems without context, such ambiguity leads to slot extraction errors, and even the most accurate intent classification model cannot cope with the correct matching of parameters. To solve this problem, annotators must work with the entire dialogue, not just a single message, and annotation guides must contain clear instructions for interpreting contexts.
The second difficulty is dependency. Slots depend on human intent. A slot itself means nothing. Its meaning changes in different situations. For example, in the phrase “Change my flight to Paris,” the word “Paris” is the destination. This is the Destination Slot.
But in another phrase, “Schedule a meeting in Paris,” the word “Paris” means the meeting place. This is the Meeting_Location Slot.
Annotators must have a good understanding of a person’s specific intention. They must know what action the word refers to. If they make a mistake, the model will get confused. It will not understand what to do.
In real projects, the team had to communicate a lot. Annotators talked to developers and managers. Together, they clarified the annotation rules so that everything would work correctly.
The third problem is consistency of annotation. Even the same object can be represented in different ways: “NYC,” “New York,” “New York City.” Without standardization of values and strict annotation rules, the model receives conflicting data and is trained incorrectly. In industrial practice, slot value normalization and inter-annotator agreement methods are used to solve this problem, where several specialists check the same sample and agree on the values. This is the only way to ensure stable system performance in real dialogues.
Experience with large conversational AI datasets shows that the annotation workflow must be rigorous and multi-layered:
- Creating detailed guidelines for each intent and slot.
- Preparing and training a team of annotators with domain-specific knowledge.
- Multi-level verification of markup, including independent QA and reconciliation of results from multiple annotators.
- Normalization of slot values, including spelling variations, abbreviations, and synonyms.
- Continuous iteration and updating of rules as the domain expands and new scenarios are added.
Only with such discipline does the annotation process become reproducible and reliable. Otherwise, even a modern slot filling NLP system will generate errors, and chatbot training data will be unsuitable for industrial use. Experience shows that saving money at this stage always results in costly production failures, reduced accuracy of intent and slot filling, and an increase in the number of fallback responses.
Industry Use Cases
The practical significance of slot annotation becomes particularly evident when analyzing specific cases from different industries. Experience with implementing dialogue systems shows that without high-quality labeled conversational AI datasets, even the most advanced slot filling NLP models are unable to ensure predictable bot behavior.
In online stores, people write queries however they want. They don’t choose from predefined buttons.
For example: “Find me size 10 running shoes.” The system must understand that the person wants to find a product. This is called Search_Product. But that’s not enough. You also need to understand the details correctly. The product is running shoes. The size is 10.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

If someone entered the data incorrectly or did not check the size, the system may make a mistake. It may show size 9 instead of 10. Or it may not understand the word “tenth” if it is expecting the number “10.”
Engineers noticed that even small errors in such details harm the store. People cannot find the product they need and do not buy it. Because of this, sales can decrease by about 7% if there are many errors.
In banking, accuracy is critical: any error in slots can have financial consequences. Consider the request “Pay John $20.” The intent is Transfer_Money. To execute the transaction correctly, the system must allocate Recipient = John, Amount = 20, Currency = USD. Omitting or incorrectly matching any of these slots will result in a transfer error or transaction block. In a real project for a large bank, incorrect Currency annotation in conversational AI datasets caused 2% of false transfers between accounts in different currencies, requiring manual intervention and a review of the entire slot extraction scheme.
In healthcare, correct slot annotation is directly related to safety and quality of service. Example: “Schedule an appointment with Dr. Smith.” Intent — Book_Appointment. The system must correctly identify Doctor_Name = Dr. Smith, and, if necessary, the Date/Time slots. Errors in annotation can lead to double bookings or missed patient appointments. In medical projects, professional teams of annotators with experience in healthcare strictly followed the rules for normalizing doctor names and time formats to minimize risk.
These cases demonstrate the key practical role of slot annotation and slot value normalization. Without proper annotation and verification standards for conversational AI datasets, the system cannot ensure accurate and predictable behavior in real interactions with users. The experience of engineers with 20 years of practice confirms that the successful implementation of dialogue systems depends on discipline in creating chatbot training data and the quality of slot annotation, not just on the power of the model.
Conclusion
The practice of implementing dialogue systems in various industries shows one consistent pattern. The “intelligence” of a chatbot is determined not by the size of the model, but by the quality of the data on which it is trained. It is the accuracy of slot annotation, the consistency of entity annotation, and the correct combination of intent classification and slot extraction that shape the actual behavior of the system in production.
Natural Language Understanding (NLU) can be implemented based on modern transformers or hybrid architectures. But without strictly structured conversational AI datasets, even the most advanced model will demonstrate instability. Errors in chatbot training data are scaled. Inconsistent slot value normalization leads to logical failures. Insufficient semantic annotation undermines contextual understanding. As a result, business logic suffers and users lose trust in the system.
The experience of engineers with many years of practice confirms that investments in high-quality AI text labeling and a strict intent and slot filling scheme always pay off. A well-designed annotation process reduces the number of errors in production, increases the accuracy of automation, and makes the system predictable.
The quality of annotation is the foundation on which the intelligence of the system is built. Everything else is just an add-on.
If the team treats labeling as something very important, rather than just a formality, everything works better. The model becomes stable and can be improved more quickly. When there are clear rules, multi-stage verification, and specialists who understand the subject, ordinary text is transformed into useful data for AI. This data helps the system to work for a long time and bring benefits.
To create a large and reliable system with a chatbot, it is not enough to simply try different models. You need to work carefully with the data. When the markup is done correctly, when the intentions of users are clear, and all data is recorded accurately and consistently, the system ceases to be just an experiment. It becomes a real working tool. And it all starts with good quality data.
If your project requires professional training of conversational AI datasets, slot scheme development, or large-scale data annotation for NLP tasks, you can contact the expert team at Tinkogroup. Learn more about NLP and text annotation services.
How should annotators handle cases where a single word could represent multiple slots?
This is known as overlapping entities. The best practice is to rely on the context of the entire sentence. If the system supports it, use multi-labeling; otherwise, the annotation guidelines should prioritize the intent that most directly impacts the chatbot’s required action.
What is the most effective way to maintain consistency across a large dataset labeled by different people?
Consistency is achieved through a robust “Gold Standard” dataset—a pre-labeled set that all annotators must match. Regular inter-annotator agreement checks and a centralized Slot Annotation Guide ensure that everyone interprets slot boundaries, like dates or locations, the same way.
How does the precision of slot boundaries affect the chatbot’s performance?
Precise boundaries are critical. If a slot (like a product ID or a name) is missing a character or includes extra spaces, the Downstream Natural Language Understanding (NLU) model might fail to trigger the correct API call. Clean, tight annotation is what makes a chatbot “smart” rather than just functional.


