

A Beginner’s Guide to Data Annotation
Data annotation process is a fundamental building block within artificial intelligence (AI) and machine learning (ML). For beginners launching on this journey, understanding data annotation is crucial.
This process, which involves labeling and categorizing data to train AI models, transforms raw data into valuable insights. Whether tagging images for computer vision applications, transcribing audio for natural language processing (NLP), or categorizing text for sentiment analysis, data annotation is the silent force driving the accuracy and efficiency of intelligent systems.
So, this guide aims to make clearer data annotation, offering practical insights to help newcomers confidently guide this essential aspect of AI development. Let’s start our beginner’s journey!
The essence of data annotation
What is data annotation? In a nutshell, it is an essential aspect of machine learning and artificial intelligence. It is vital in enabling machines to interpret and understand human language, images, and other forms of data.
Regarding annotating data definition, it is labeling data to make it understandable for machine learning algorithms. It involves adding metadata to a dataset, which can include text, images, audio, and video, to highlight specific features, objects, or other relevant information. The primary goal is to provide a context that machines can use to learn from the data. However, even small inconsistencies at this stage can scale into serious issues later, which is why many teams eventually run into data labeling mistakes that hurt machine learning model performance.
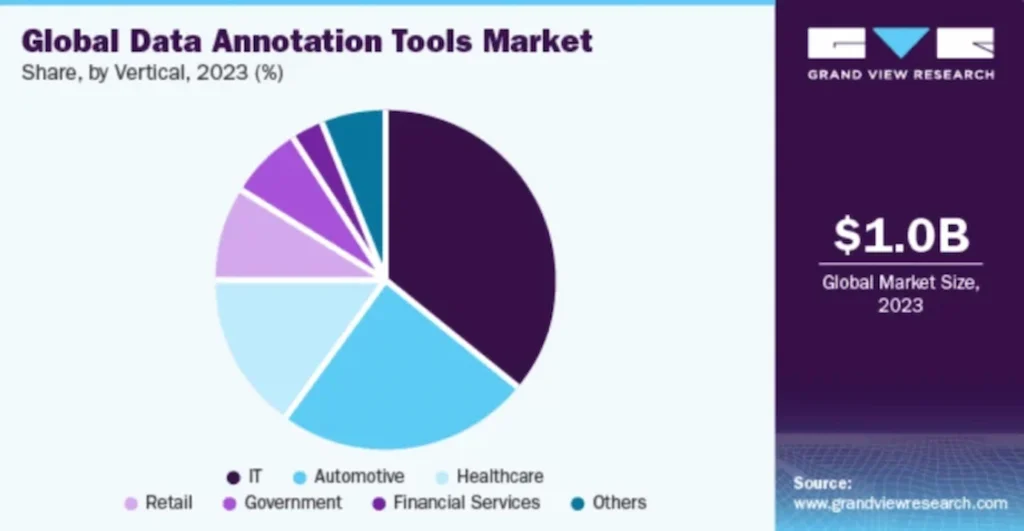
The global market for data annotation tools was valued at $1.02 billion in 2023 and is expected to grow by 26.3% annually from 2024 to 2030. This growth is mainly due to the rising use of image data annotation tools in the automotive, retail, and healthcare sectors. These tools help improve the value of data by adding tags or labels.
In fact, data annotation plays a key role in machine learning, mainly supervised learning, where models learn from labeled data. Here are the critical aspects of its role:
Training data preparation
Annotated data is the primary ingredient for training machine learning models. Supervised learning algorithms require examples of input-output pairs, where humans provide the output (label). This labeled data is used to train models to make predictions or classifications.
Validation and testing
In addition to training, annotated data is also used to validate and test machine learning models. Validation data helps tune model parameters and select the best model, while testing data evaluates the model’s performance on unseen data, ensuring its robustness and accuracy.
Domain-specific applications
Different industries require domain-specific annotations. For example, in autonomous driving, data annotation involves labeling road signs, lanes, pedestrians, and other vehicles. Medical imaging involves labeling tumors, organs, and other anatomical structures. This domain-specific annotation is crucial for developing specialized models that perform well in their respective fields.
Reducing bias and improving fairness
Annotated data helps identify and mitigate biases in machine learning models. By carefully curating and annotating diverse datasets, developers can ensure that models are trained on representative data, reducing biases related to gender, race, or other attributes and promoting fairness.
Now, let’s consider how the data annotation can be presented.
Main types of data annotations
The type of annotation applied depends on the data’s nature and the machine-learning task’s specific requirements. Below, you can check various types of data annotations.

Text annotation
This type of data annotation involves labeling text data with tags that provide contextual information. Text annotation is fundamental for natural language processing tasks.
- Named entity recognition (NER): Identifies and classifies entities in text into predefined categories such as names of people, organizations, locations, dates, etc.
- Part-of-speech tagging: Assigns parts of speech to each word in a sentence (e.g., noun, verb, adjective), which is crucial for understanding grammatical structure.
- Sentiment analysis: Labels sentences or phrases with sentiment indicators such as positive, negative, or neutral, helping in gauging public opinion or customer feedback.
- Intent detection: Identifies the intent behind a user’s query, which is essential for chatbots and virtual assistants to provide appropriate responses.
- Entity linking: Connects named entities to a knowledge base, adding depth to the understanding of the text by linking it to broader concepts.
Video annotation
This data annotation type involves labeling video frames to identify objects, actions, or events. Video annotation is vital for autonomous driving, video surveillance, and activity recognition applications.
- Frame-by-frame annotation: Annotates each frame individually, providing detailed information about the objects and their movements.
- Object tracking: Tracks the movement of objects across multiple frames, which is essential for understanding the dynamics in a video.
- Action annotation: Labels specific actions performed by subjects in the video, such as running, jumping, or hand gestures, which is important for activity recognition.
- Event annotation: Identifies and labels significant events or interactions in videos, which is helpful in management and sports analytics.
Image annotation
This type of data annotation involves labeling images with metadata to identify objects, features, or regions of interest. Image annotation is crucial for computer vision tasks.
- Bounding boxes: Draws rectangular boxes around objects to define their location and size. Commonly used in object detection and recognition.
- Polygon annotation: Uses polygons to delineate the precise shape and boundary of objects, providing more accurate localization than bounding boxes.
- 3D cuboids: Annotates objects with three-dimensional boxes, capturing depth information. Essential for applications like autonomous driving, where understanding the 3D structure of objects is crucial.
- Landmark annotation: Marks key points on objects, such as facial features (eyes, nose, mouth) or anatomical landmarks in medical images. Useful for facial recognition and pose estimation.
Audio annotation
This data annotation type involves labeling audio data with information such as transcription, speaker identification, or acoustic events. This is key for speech recognition and sound classification.
- Speech transcription: Converts spoken words into text, enabling the development of speech recognition systems.
- Speaker identification: Labels segments of audio with the speaker’s identity, useful for applications like voice-activated assistants and call center analytics.
- Acoustic event detection: Identifies and labels sounds or events in audio recordings, such as doorbells, alarms, or gunshots, which is critical for security and surveillance systems.
- Emotion annotation: Labels audio data with emotional states such as happy, sad, or angry, important for applications in sentiment analysis and affective computing.
Semantic segmentation
This type of data annotation involves classifying each pixel in an image into a predefined category. Semantic segmentation provides a detailed understanding of the scene and is helpful for high-precision applications.
- Scene understanding: Classifies every pixel in an image, enabling a comprehensive understanding of the scene.
- Medical imaging: Identifies and labels different tissues or structures in medical images, aiding diagnosis and treatment planning.
- Urban planning: Used in aerial imagery to classify land use and cover, assisting in urban planning and environmental monitoring.
Polygon annotation
This data annotation type involves outlining objects with points connected by straight lines, forming a polygon. Polygon annotation provides a precise boundary around objects, making it ideal for tasks requiring detailed localization.
- Object localization: Precisely outlines objects in images or videos, providing accurate shape and area information.
- Semantic segmentation: Used with polygon annotation to classify each pixel within the outlined area, improving object recognition.
3D cuboids
This type of data annotation involves drawing three-dimensional boxes around objects to capture their spatial orientation and volume. 3D cuboids are crucial for tasks that require depth perception and spatial awareness.
- Autonomous vehicles: Helps understand the 3D environment, allowing vehicles to navigate and avoid obstacles effectively.
- Robotics: Enables robots to interact with objects accurately in three-dimensional space, essential for manipulation and navigation.
Bounding boxes
They are one of the most commonly used types of data annotations. In fact, bounding boxes involve drawing rectangular boxes around objects in images or video frames. This method is straightforward but effective for a wide range of applications.
- Object detection: Identifies the presence and location of objects within an image, which is essential for surveillance, autonomous vehicles, and retail analytics.
- Image classification: Helps in categorizing images based on the objects they contain, useful in organizing and searching large image databases.
- Face detection: Locates faces in images or videos, a critical step in facial recognition systems.
Best features for data annotation
Effective data annotation relies on various features to ensure quality, efficiency, and scalability. Here are the best features that make data annotation successful:
High-quality labels
The cornerstone of effective data annotation is high-quality labels. Accurate and consistent labeling ensures that the machine-learning model can be trained correctly from the data. Quality can be achieved through:
Clear guidelines
Providing annotators with detailed instructions and examples to minimize ambiguity.
Expert annotators
Employing domain experts who understand the intricacies of the data, such as medical professionals for annotating medical images.
Quality control
Implementing a multi-tier review process where labels are verified by multiple annotators and reviewed by experts to ensure consistency and accuracy. Organizations often complement these workflows with annotator performance benchmarks to identify quality issues early while maintaining project velocity.
Collaboration capabilities
Effective data annotation often requires collaboration among multiple annotators and experts. Features that facilitate collaboration include:
Real-time collaboration
Tools that support real-time collaboration where multiple annotators can work on the same dataset simultaneously.
Commenting and feedback
Features that allow annotators to leave comments and feedback, enabling better communication and understanding among the team.
Task management
Tools that help assign tasks, track progress, and manage workflows to ensure timely completion of annotation projects.
Scalability
As datasets grow, the data annotation process must be able to scale accordingly. Scalability features include:
Cloud-based solutions
Utilizing cloud infrastructure to handle large datasets and allow remote access for annotators.
Batch processing
Ability to process and annotate large batches of data simultaneously to increase throughput.
Flexible workforce
Using a combination of in-house and outsourced annotators to manage varying workloads and scale up quickly when needed.
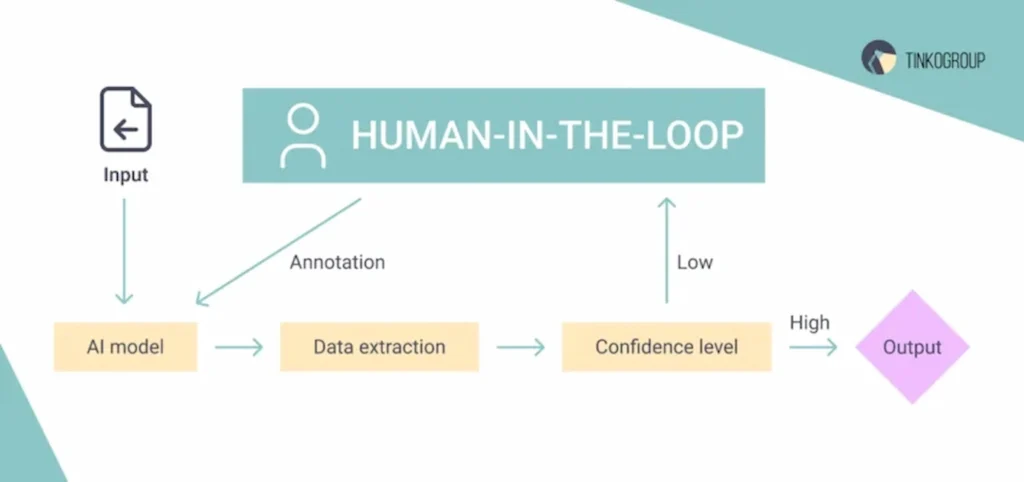
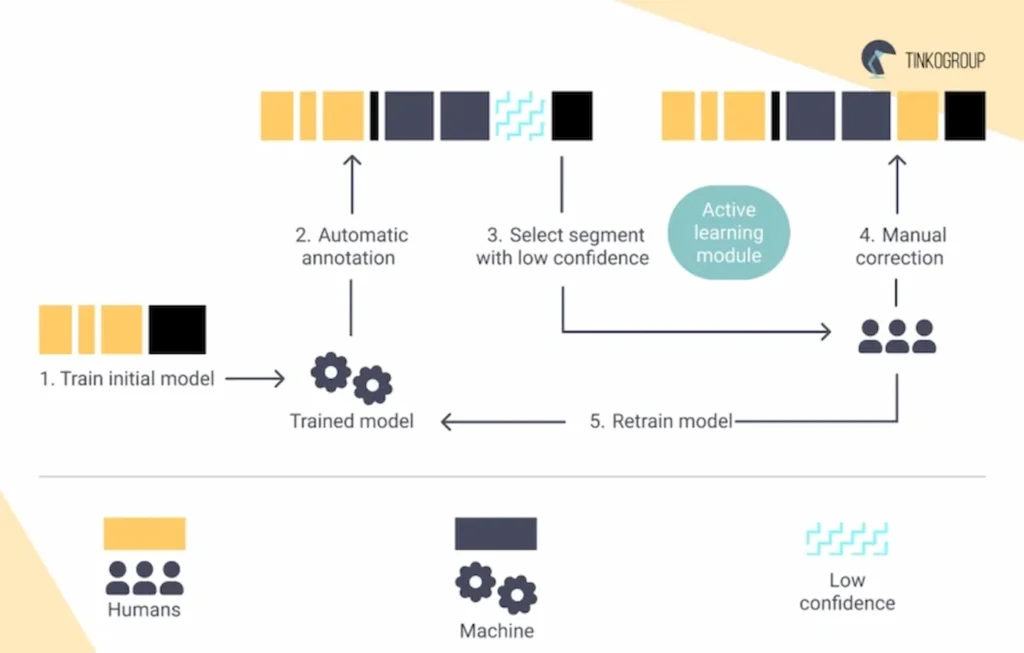
Human-in-the-loop
Incorporating human-in-the-loop (HITL) approaches can significantly enhance the data annotation process.
Active learning
Using models to identify and prioritize the most uncertain or informative samples for human annotation, thus maximizing the impact of each annotated sample.
Feedback loops
Allowing annotators to provide feedback on model predictions and suggestions, which can then be used to improve the model iteratively.
Dynamic adjustment
Continuously adjusting the annotation strategy based on model performance and feedback, ensuring the annotation process remains efficient and effective.
Below is an example of human-in-the-loop annotation.
Security and privacy
Data annotation often involves sensitive information, especially in healthcare and finance. Ensuring the security and privacy of data is paramount:
Data encryption
Implementing robust encryption methods for data at rest and in transit to protect against unauthorized access.
Access controls
Restricting access to data based on roles and responsibilities, ensuring that only authorized personnel can view or annotate sensitive information.
Compliance
Adhering to relevant data protection regulations, such as GDPR (General Data Protection Regulation) or HIPAA (Health Insurance Portability and Accountability Act), to ensure legal compliance and protect user privacy.
Integration with machine learning pipelines
Seamless integration with existing machine learning pipelines can significantly streamline the data annotation. Integration features include:
API access
Providing APIs (application programming interfaces) that allow easy integration with other tools and platforms used in the machine learning workflow.
Data import/export
Supporting various data formats and enabling smooth import and export of data to and from the annotation tool.
Continuous learning
Integrating data annotation tools with active learning frameworks can suggest the most informative samples for annotation, thus improving model performance iteratively.
Automated quality assurance
Automated quality assurance features help maintain the quality of annotations without excessive manual oversight:
Consistency checks
Automated checks that detect inconsistencies in annotations, such as overlapping labels or missing annotations.
Statistical analysis
Tools that analyze the annotations statistically to identify outliers and errors.
Model validation
Use preliminary models to validate annotations by predicting labels on a validation set and comparing them with human annotations.
Efficient workflow management
Efficient workflow management features ensure that annotation projects are completed on time and within budget:
Task assignment
Automatically assigning tasks based on annotator expertise and workload to optimize efficiency.
Progress tracking
Real-time dashboards that track the progress of annotation projects and provide insights into productivity and performance.
Time management
Tools that monitor the time spent on each task to help manage deadlines and improve efficiency.
Fundamental benefits of data annotation
The accuracy and effectiveness of AI models depend significantly on the quality of the annotated data on which they are trained. Here are the top benefits of data annotation:
Enhanced model accuracy
The primary benefit of data annotation is the significant improvement in the accuracy of machine learning models. Accurate labels ensure the model can learn and generalize from the training data. For example, correctly annotated images in image recognition allow the model to identify objects, faces, and scenes with high precision. Similarly, properly annotated text data in natural language processing helps understand and generate human language more accurately. High-quality annotated data is a foundation for training models that perform well in real-world applications.
Better decision-making
Data annotation aids in better decision-making by enabling models to provide more reliable outputs. In sectors like healthcare, annotated medical images can help AI systems accurately detect diseases, leading to better diagnosis and treatment plans. In finance, annotated datasets help predict market trends and assess risks more effectively. When models are trained on well-annotated data, their insights are more trustworthy, leading to improved strategic decisions.
Personalized customer experiences
Businesses can use annotated data to create personalized customer experiences. In e-commerce, for instance, annotated customer behavior data can help understand preferences and predict future purchases. This allows companies to offer tailored recommendations, enhancing customer satisfaction and loyalty. Similarly, in digital marketing, annotated data enables the creation of highly targeted campaigns that resonate more with the audience, increasing engagement and conversion rates.
Efficient automation
Data annotation is crucial for developing AI systems that can automate routine tasks, increase efficiency, and reduce costs. For example, annotated data is used to train chatbots and virtual assistants, enabling them to understand and respond to customer queries effectively. In manufacturing, annotated datasets help in developing robots that can identify and handle objects precisely, leading to improved productivity. Automating repetitive tasks with the help of annotated data allows human workers to focus on more complex and strategic activities.
Improved security
Annotated data enhances system security by improving the accuracy of models designed to detect fraud and other malicious activities. For instance, annotated datasets are used in cybersecurity to train models to identify patterns associated with cyber threats. This helps in the early detection and prevention of attacks. Similarly, in the banking sector, annotated transaction data helps identify fraudulent activities and protect both institutions and customers.
Development of advanced technologies
Data annotation is at the heart of developing advanced technologies such as autonomous vehicles, facial recognition, and speech recognition systems. For autonomous cars, annotated data from various sensors (cameras, LIDAR, etc.) is essential for understanding the environment and making safe driving decisions. In facial recognition, annotated images help accurately identify individuals, which can be used for security purposes or user authentication. In speech recognition, annotated audio data improves the system’s ability to accurately understand and transcribe spoken language.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Enhanced user interaction
In interactive AI applications, annotated data is fundamental for improving user interaction. Virtual assistants like Siri, Alexa, and Google Assistant rely on annotated data to understand user commands and provide relevant responses. This enhances the user experience by making interactions more natural and intuitive. Annotated datasets enable these systems to learn from user inputs and continuously improve performance.
Support for continuous learning
AI models require continuous learning and updating to stay relevant and practical. Data annotation supports this by providing fresh, accurately labeled data for ongoing training. This is particularly important in dynamic fields like social media monitoring and sentiment analysis, where trends and public opinions change rapidly. Regular updates with annotated data ensure that the models remain up-to-date and perform well in changing environments.
Facilitation of research and development
Data annotation is essential for research and development in AI and ML. Researchers rely on annotated datasets to test hypotheses, validate models, and explore new algorithms. High-quality annotated data accelerates innovation by providing a reliable basis for experimentation and discovery. This is crucial for advancing the field and developing new applications that benefit various industries.
Scalability of AI solutions
Finally, data annotation enables the scalability of AI solutions. Well-annotated datasets allow companies to scale their AI applications across different domains and regions effectively. For instance, a voice recognition system trained on annotated data from multiple languages can be deployed globally. This scalability is vital for businesses expanding their AI capabilities and reaching a broader audience.
Detailed process of data annotation
This process involves several stages, each requiring careful attention to ensure the quality and utility of the annotated data. Let’s discover the main steps together!
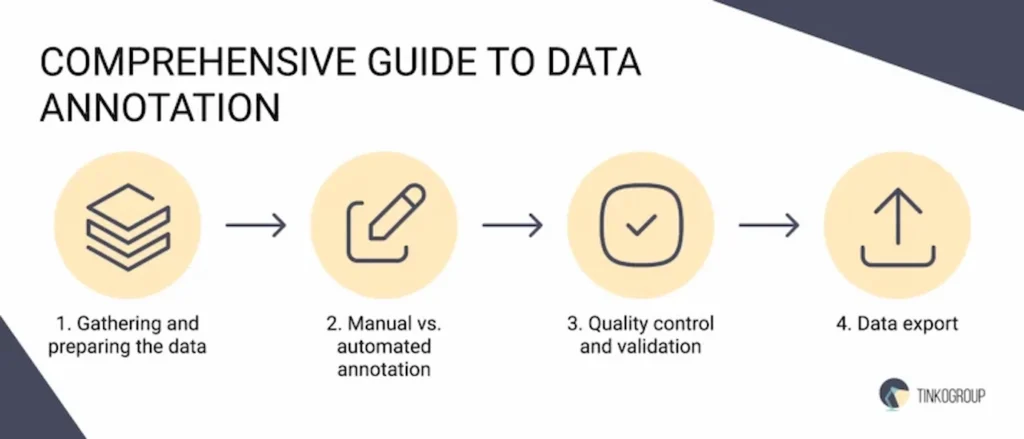
1. Gathering and preparing the data
The first step in the data annotation process is gathering and preparing the data. This involves collecting raw data from various sources and preprocessing it to ensure it is ready for annotation.
Data collection:
- Identify sources: Determine where the data will come from. Sources can include databases, web scraping, sensors, surveys, and more.
- Gather data: Collect the data in a raw format. This might include text documents, images, videos, audio recordings, or other data types.
- Data privacy and security: Ensure the data collection process adheres to relevant privacy laws and security standards to protect sensitive information.
Data preparation:
- Cleaning data: Remove any irrelevant, duplicate, or noisy data. This includes correcting errors, filling in missing values, and standardizing formats.
- Data formatting: Convert the data into a format suitable for annotation. For example, text data might need to be segmented into sentences or paragraphs, images need to be resized or cropped, and audio files need to be trimmed.
- Sampling: If dealing with large datasets, it might be necessary to sample a subset of the data for annotation, ensuring the sample is representative of the entire dataset.
2. Manual vs. automated annotation
Data annotation can be performed manually by humans, automatically by machines, or through a combination of both. Each approach has its advantages and challenges.
Manual annotation
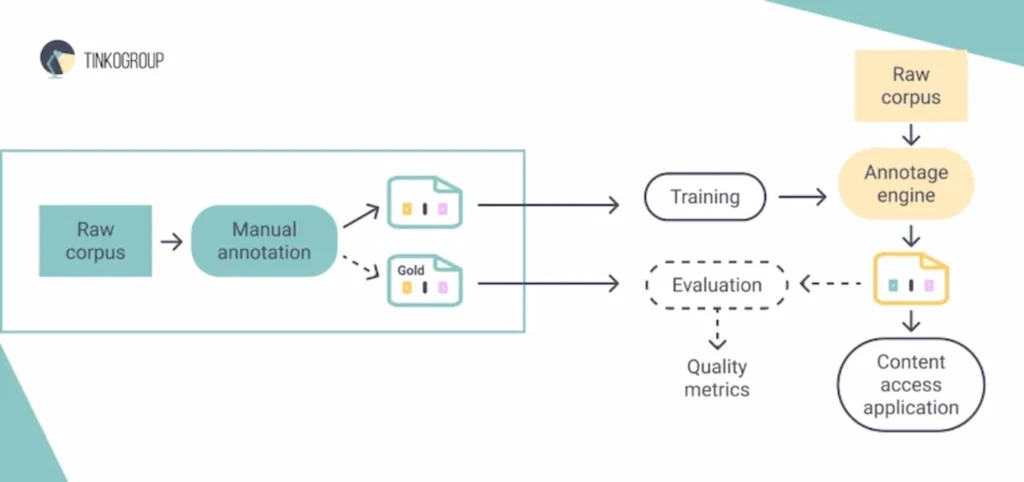
Advantages:
- Accuracy: Human annotators can understand context and nuances, leading to high-quality annotations.
- Flexibility: Can handle complex and ambiguous data that machines might struggle with.
Challenges:
- Time-consuming: Manual annotation is labor-intensive and can be slow.
- Costly: Hiring and training annotators can be expensive.
- Scalability: Scaling up manual annotation efforts can be difficult, especially for large datasets.
Automated annotation
Advantages:
- Speed: Automated systems can process large volumes of data quickly.
- Cost-effective: Reduces the need for extensive human labor.
- Scalability: Easily scales to handle large datasets.
Challenges:
- Accuracy: Automated systems may struggle with complex or ambiguous data and can introduce errors.
- Initial setup: Requires significant effort to develop and fine-tune the annotation algorithms.
Hybrid approach
Combines the strengths of both manual and automated data annotation.
- Pre-annotation by machines: Automated systems can provide initial annotations, which human annotators can then review and refine.
- Active learning: An iterative process where machines identify the most uncertain samples for human annotation, improving model performance with fewer annotated examples.
- Quality assurance: Humans can focus on quality control and validation of automated annotations.
3. Quality control and validation
Ensuring the quality of annotations is critical for the success of machine learning models. Quality control and validation involve multiple steps to verify the accuracy and consistency of data annotations.
Quality control measures:
- Multi-tier review: Implement a multi-layer review process where initial annotations are checked by senior annotators or domain experts.
- Inter-annotator agreement: Measure the consistency between different annotators to identify and resolve discrepancies.
- Spot checks: Randomly sample and review annotations to identify potential issues.
Validation techniques:
- Consensus building: Use multiple annotators for the same data points and reach a consensus to ensure accuracy.
- Gold standard data: Compare annotations against a pre-defined gold standard dataset to evaluate accuracy.
- Automated validation: Use preliminary models to validate annotations by predicting labels on a validation set and comparing them with human annotations.
Feedback loop:
- Annotator training: Provide continuous training and feedback to annotators to improve their performance.
- Error analysis: Regularly analyze errors and provide feedback to annotators to avoid similar mistakes in the future.
4. Data export
The final step in the data annotation process is exporting the annotated data in a format suitable for machine learning model training and evaluation.
Exporting data:
- Format selection: Choose a format compatible with machine learning frameworks. Standard formats include JSON, CSV, XML, and specialized formats like COCO for images.
- Data structuring: Organize the data into a structured format, ensuring annotations are clearly linked to their corresponding data points.
- Metadata inclusion: Include metadata such as annotation timestamps, annotator IDs, and any relevant comments or notes that can aid in model training and evaluation.
Data management:
- Version control: Implement version control to keep track of different versions of the annotated dataset.
- Backup and storage: Ensure that annotated data is securely stored and backed up to prevent data loss.
Integration with machine learning pipelines:
- API integration: Use APIs to integrate the annotated data directly into machine learning pipelines for seamless training and evaluation.
- Continuous updates: Set up processes for continuous annotation and updating of the dataset as new data becomes available, ensuring that the model remains up-to-date.
Thus, investing in a comprehensive data annotation process is essential for employing the full potential of machine learning and artificial intelligence.
Data annotation in various scenarios
Data annotation involves labeling or tagging data, such as images, text, videos, and audio, to enable machines to understand and learn from it. Here, we explore various use cases where data annotation plays a key role, illustrating its impact across multiple industries.
Healthcare
Medical imaging:
- Scenario: Annotating medical images, such as X-rays, MRIs, and CT scans, to identify and label anatomical structures, diseases, and anomalies.
- Impact: Data annotation in medical imaging helps in developing AI models that can detect diseases like cancer, fractures, and neurological disorders with high accuracy. This aids radiologists in diagnosing conditions more quickly and accurately, leading to improved patient outcomes.
Electronic health records (EHR):
- Scenario: Annotating text in EHRs to identify relevant patient information, such as symptoms, diagnoses, treatments, and medical history.
- Impact: Annotated EHRs enable natural language processing models to extract valuable insights from unstructured data, enhancing decision-making in clinical settings and contributing to personalized patient care.
Autonomous vehicles
Object detection and recognition:
- Scenario: Annotating images and videos captured by vehicle sensors to label objects like pedestrians, other vehicles, traffic signs, and road obstacles.
- Impact: High-quality annotations are crucial for training models that can recognize and respond to various objects on the road. This is essential for the safe operation of autonomous vehicles, improving their ability to guide complex environments and reducing the risk of accidents.
Lane detection:
- Scenario: Annotating road lanes in images and videos to train models for lane detection and lane-keeping assistance.
- Impact: Accurate lane detection is fundamental for autonomous driving systems to maintain the correct lane, execute safe lane changes, and avoid collisions, enhancing overall driving safety.
Retail and e-commerce
Product categorization:
- Scenario: Annotating product images and descriptions to categorize them accurately.
- Impact: Improved product categorization enhances search functionality and recommendations on e-commerce platforms, leading to a better user experience and increased sales.
Sentiment analysis:
- Scenario: Annotating customer reviews and feedback to determine sentiment (positive, negative, neutral).
- Impact: Sentiment analysis helps retailers understand customer satisfaction and preferences, enabling them to improve products and services based on consumer feedback.
Finance
Fraud detection:
- Scenario: Annotating financial transactions and communications to label them as legitimate or fraudulent.
- Impact: Annotated data helps train models to detect fraudulent activities in real time, protecting financial institutions and their customers from fraud.
Document processing:
- Scenario: Annotating financial documents, such as invoices and receipts, to extract relevant information.
- Impact: Automated document processing systems can quickly and accurately extract data from financial documents, improving efficiency and reducing manual errors in financial operations.
Top practices for effective data annotation
Compelling data annotation ensures that models are trained on accurate, high-quality data, leading to better performance and more reliable outcomes. Our team prepared the best practices for achieving practical data annotation:

1. Define clear objectives
Before starting the data annotation process, it’s essential to understand the project’s goals and requirements clearly.
Task definition
Clearly define the specific task or problem the machine learning model aims to solve (e.g., object detection, sentiment analysis).
Annotation guidelines
Develop detailed guidelines that outline what needs to be annotated, how it should be annotated, and any specific rules or conventions to follow.
2. Select the right annotation tool
Choosing the appropriate data annotation tools is critical for efficiency and accuracy.
Feature compatibility
Ensure the tool supports the specific types of annotations required (e.g., bounding boxes, polygons, text labels).
User-friendliness
The tool should have an intuitive interface that is easy for annotators to learn and use.
Scalability
The tool should be able to handle large datasets and support real-time collaboration among multiple annotators.
Integration
Look for tools that can easily integrate with your existing data pipelines and machine learning frameworks.
3. Implement rigorous training programs
Training annotators thoroughly is crucial to achieving high-quality data annotations.
Comprehensive training
Provide detailed training sessions that cover the annotation guidelines, tool usage, and examples of correctly annotated data.
Ongoing support
Offer continuous support and resources like FAQs, help desks, and regular feedback sessions to address any questions or issues.
Practice projects
Start with practice projects to allow annotators to familiarize themselves with the process and receive feedback before working on actual data.
4. Utilize automation and active learning
Incorporating automated techniques can enhance efficiency and consistency.
Pre-annotation tools
Use automated tools to provide initial annotations that human annotators can review and refine.
Active learning
Implement active learning techniques where the model identifies uncertain or informative samples for human annotation, improving the efficiency of the data annotation process.
Hybrid approaches
Combine manual and automated annotation methods to use both strengths.
5. Manage workflow efficiently
Efficient workflow management ensures that annotation projects are completed on time and within budget.
Task assignment
Use automated systems to assign tasks based on annotator expertise and workload.
Progress tracking
Implement real-time tracking of annotation progress to monitor productivity and performance.
Time management
Monitor the time spent on each task to identify bottlenecks and improve efficiency.
6. Conduct regular feedback and iteration
Continuous improvement is vital to maintaining high data annotation quality.
Regular feedback
Provide regular feedback to annotators based on their performance to help them improve.
Error analysis
Analyze errors and provide targeted training or adjustments to guidelines to prevent recurrence.
Iterative refinement
Continuously refine annotation guidelines and processes based on feedback and evolving project needs.
7. Employ domain expertise
Involving domain experts can significantly enhance the quality and relevance of annotations.
Expert involvement
Include domain experts in the development of annotation guidelines and the review process.
Specialized training
Provide specialized training for annotators working on complex or technical data to ensure they understand the nuances.
8. Maintain comprehensive documentation
Documenting the entire data annotation process helps ensure transparency and reproducibility.
Annotation guidelines
Maintain up-to-date documentation of annotation guidelines, including examples and edge cases.
Process documentation
Document the entire annotation process, including tool configurations, workflow steps, and quality control measures.
Version control
Keep version-controlled records of annotated datasets to track changes and updates.
Advanced technologies in data annotation
Data annotation tools are essential in preparing datasets for machine learning and AI projects. These tools provide functionalities that enhance data annotation processes’ accuracy, efficiency, and scalability. Here’s a detailed overview of some of the best technologies in data annotation.
- Scale AI
Scale AI is a robust data annotation platform that satisfies various annotation needs, from text to images to 3D point clouds. It is known for its scalability and the ability to handle large datasets efficiently.
Key features:
- Automation: Uses machine learning to pre-annotate data, which human annotators can refine, significantly speeding up the process.
- Quality assurance: Implements rigorous quality control measures, including consensus mechanisms and inter-annotator agreement checks.
- Versatility: Supports various types of annotations, including image segmentation, object detection, and text labeling.
- Integration: Seamlessly integrates with existing data pipelines and machine learning frameworks through APIs.
Advantages:
- High scalability for large datasets.
- Strong quality control processes.
- Extensive support for multiple data types and annotation needs.
Use cases:
- Autonomous driving, where precise object detection and segmentation are crucial.
- NLP projects requiring large-scale text annotation.
- Doccano
Doccano is an open-source data annotation tool that is user-friendly and highly customizable. It supports various text annotation tasks, making it a favorite among NLP researchers and practitioners.
Key features:
- Ease of use: Intuitive interface that makes creating and managing annotation projects easy.
- Customizable: Supports custom annotation schemas and workflows.
- Collaboration: Facilitates collaborative annotation efforts with multi-user support.
- Support for multiple tasks: Includes named entity recognition, text classification, and sequence labeling functionalities.
Advantages:
- Open-source and free to use.
- Highly customizable to fit specific project needs.
- Easy to set up and use, even for non-technical users.
Use cases:
- Academic research requiring custom text annotations.
- Enterprises needing flexible and cost-effective text annotation solutions.
- VGG Image Annotator (VIA)
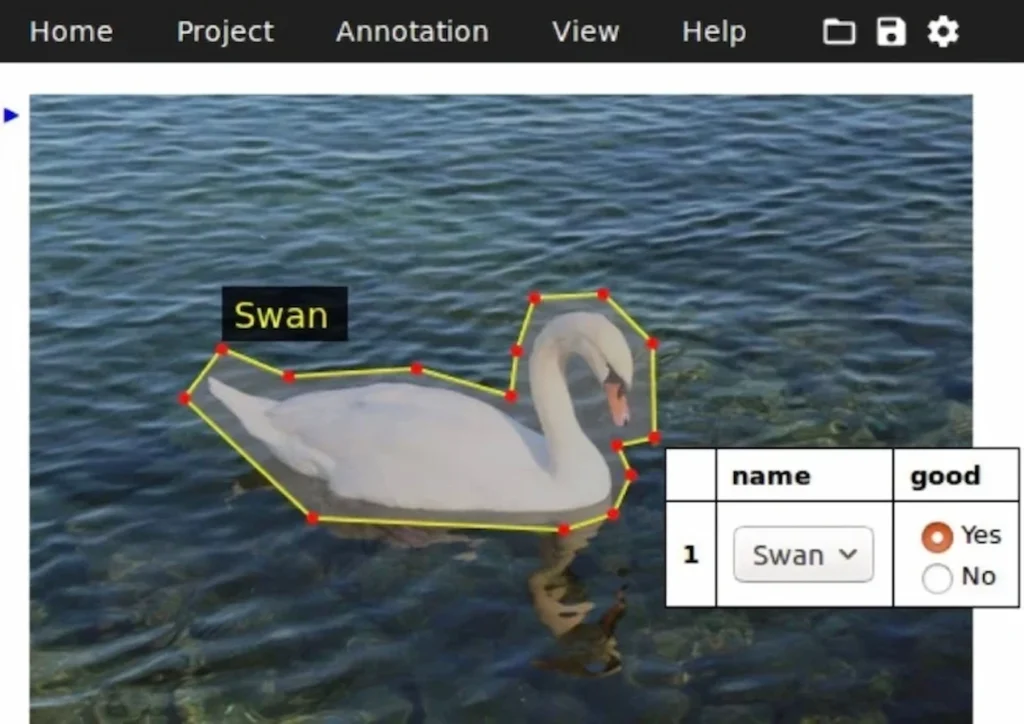
The VGG Image Annotator (VIA) is an open-source data annotation tool developed by the Visual Geometry Group at the University of Oxford. It is designed for image annotation and supports various types of image labeling.
Key features:
- Versatile annotations: Supports bounding boxes, polygons, and points for annotating images.
- Lightweight: A standalone application that doesn’t require any server or database setup.
- Custom attributes: Allows users to define custom annotation attributes.
- Simple interface: User-friendly interface suitable for individual and team projects.
Advantages:
- No need for extensive infrastructure setup.
- Highly versatile with support for various annotation types.
- Free and open-source, making it accessible for all.
Use cases:
- Annotating medical images for research and diagnostic tool development.
- Creating datasets for training computer vision models in academic projects.
- Video Annotation Tool from Internet Curation (VATIC)

VATIC is a powerful data annotation tool designed for video annotation, allowing users to label objects and track their movements across video frames.
Key features:
- Object tracking: Facilitates frame-by-frame object tracking in videos.
- Web interface: Accessible via a web interface, making it easy for teams to collaborate remotely.
- Customization: Allows users to define custom labels and attributes.
- Scalability: Handles large video datasets efficiently.
Advantages:
- Optimized for video annotation tasks.
- Supports detailed object tracking across video frames.
- Open-source, providing flexibility and customization options.
Use cases:
- Annotating surveillance footage for security and behavioral analysis.
- Labeling sports videos to track player movements and actions.
- PageProofer
PageProofer is a versatile data annotation tool designed for web page and application feedback, making it suitable for UI/UX (user interface/user experience) testing and development.
Key features:
- In-browser annotations: Users can annotate directly on live web pages and applications.
- Collaboration: Supports real-time collaboration and feedback from multiple users.
- Task management: Integrates with project management tools to streamline workflow.
- Versatile feedback: Allows users to provide various types of feedback, including text, drawings, and screenshots.
Advantages:
- Simplifies the process of gathering UI/UX feedback.
- Real-time collaboration enhances team efficiency.
- Easy integration with project management tools.
Use cases:
- Web development projects requiring iterative feedback and testing.
- UX/UI design teams looking to streamline the feedback process.
- Xodo
Xodo is a comprehensive data annotation tool supporting PDF and other formats. It’s designed for personal and professional use, providing a range of annotation features.
Key features:
- Multi-format support: Works with PDFs, Word documents, and other file types.
- Collaboration: Enables multiple users to annotate and comment on documents in real time.
- Cloud integration: Integrates with cloud storage services like Google Drive and Dropbox.
- Annotation tools: Offers a variety of annotation tools, including highlighting, underlining, and drawing.
Advantages:
- Versatile support for different document formats.
- Real-time collaboration capabilities.
- Cloud integration for easy document management.
Use cases:
- Collaborative document review and editing in corporate environments.
- Academic research requires detailed document annotations.
- Eclipse
Eclipse is a well-known integrated development environment (IDE) that also offers robust support for data annotation through various plugins. It’s beneficial for annotating code and related documentation.
Key features:
- IDE integration: Seamlessly integrates annotation tools within the development environment.
- Custom plugins: Supports various plugins for different annotation needs.
- Version control: Integrates with version control systems like Git, facilitating collaborative annotation.
- Syntax highlighting: Offers advanced syntax highlighting and code annotation features.
Advantages:
- Comprehensive integration within a development environment.
- Supports collaborative annotation and version control.
- Customizable through various plugins.
Use cases:
- Software development projects requiring detailed code annotations.
- Collaborative programming and peer reviews in agile development teams.
Common challenges in data annotation
The data annotation process comes with several challenges that can impact the quality, efficiency, and overall success of machine learning projects. Understanding these challenges is essential for developing strategies to reduce them and ensure high-quality annotated datasets.
- Quality and consistency
Ensuring high-quality and consistent annotations is one of the most significant challenges in data annotation. The accuracy of machine learning models heavily depends on the quality of the training data.
Challenges:
- Subjectivity: Some data, especially text and images, can be subjective, leading to varying interpretations among annotators.
- Annotator expertise: Inadequate knowledge or expertise among annotators can result in inaccurate labels, particularly in specialized fields like medical imaging or legal document analysis.
- Inter-annotator variability: Different annotators may label the same data differently, causing inconsistency in the dataset.
Mitigation strategies:
- Clear guidelines: Provide detailed instructions and examples to minimize ambiguity.
- Training programs: Implement comprehensive training programs for annotators to ensure they understand the requirements and standards.
- Review processes: Establish multi-tier review processes where annotations are cross-checked by multiple annotators and reviewed by experts.
- Scalability
This is a critical concern, especially when dealing with large datasets that require extensive annotation.
Challenges:
- Resource intensive: Manual annotation is time-consuming and labor-intensive, making it difficult to scale.
- Cost: Hiring and training a large number of annotators can be expensive.
- Data volume: Managing and annotating vast amounts of data efficiently is challenging.
Mitigation strategies:
- Automation: Incorporate automated annotation tools and techniques to handle repetitive and straightforward tasks, increasing throughput.
- Crowdsourcing: Use crowdsourcing platforms to quickly access a large pool of annotators.
- Hybrid approaches: Combine automated and manual annotation processes to balance quality and efficiency.
- Tool limitations
The limitations of the annotation tools used often constrain the effectiveness of data annotation.
Challenges:
- User interface: Complicated interfaces can slow down the annotation process and lead to errors.
- Functionality: Lack of necessary features, such as support for specific annotation types (e.g., 3D cuboids, semantic segmentation) or integration with machine learning pipelines.
- Performance: Tools that cannot efficiently handle large datasets or high-resolution data can impede the annotation process.
Mitigation strategies:
- Tool selection: Carefully select annotation tools that offer the required functionality and are user-friendly.
- Customization: Opt for tools that allow customization to fit specific project needs.
- Scalability: Ensure the tools can handle large datasets and integrate seamlessly with machine learning pipelines.
- Cost management
Balancing the costs associated with data annotation while maintaining high quality is a persistent challenge. For a clearer picture of real-world pricing, check out our guide to the actual cost per 10K labels and how to optimize without compromising quality.
Challenges:
- Labor costs: Manual annotation is labor-intensive and expensive, especially for large-scale projects.
- Tool costs: Advanced annotation tools and platforms can be costly.
- Quality assurance costs: Implementing robust quality assurance processes requires additional resources and investment.
Mitigation strategies:
- Cost-benefit analysis: Conduct a thorough cost-benefit analysis to identify the most cost-effective annotation strategies.
- Outsourcing: Consider outsourcing to specialized annotation service providers who can offer competitive pricing.
- Efficiency improvements: Use automation and hybrid approaches to improve efficiency and reduce costs.
- Complexity of data types
Annotating different types of data (text, images, video, audio) requires specialized skills and tools, adding complexity to the process.
Challenges:
- Varied requirements: Each data type has unique annotation requirements and challenges.
- Tool compatibility: Finding tools that efficiently handle multiple data types can be difficult.
- Annotator expertise: Ensuring annotators have the necessary skills for different data types can be challenging.
Mitigation strategies:
- Specialized training: Provide targeted training programs for annotators based on the data types they will be working with.
- Versatile tools: Choose versatile annotation tools that handle multiple data types.
- Cross-functional teams: Develop cross-functional teams with expertise in various data types to manage the annotation process effectively.
Our comprehensive data annotation services
At Tinkogroup, we understand that high-quality data annotation is the cornerstone of effective machine learning and AI solutions. Our wide data annotation services are designed to meet the diverse needs of our clients across various industries, ensuring precision, efficiency, and scalability.
Here’s an in-depth look at our reliable data annotation services and what sets us apart in the data processing industry:
Comprehensive service offering
Our data annotation services cover a wide range of data types and annotation needs, ensuring that we can support any machine learning or AI project. For example, you can check how we work on image categorization in the video below.
High-quality and consistent annotations
In general, quality assurance is at the heart of our data annotation services. Our specialists implement rigorous quality control measures to ensure that our annotations are accurate and consistent.
Customized solutions
Every project is unique, and we offer customized annotation solutions tailored to meet specific client needs. It is about project assessment, custom guidelines, client collaboration, seamless integration and data management, API integration, data formats, version control, and continuous updates.
For example, let’s consider our text annotation case study. We aimed to improve the accuracy and efficiency of identifying and classifying entities in text data, focusing on names, organizations, and locations. Our team implemented a sentiment analysis annotation system to assess and label the emotional tone of the text. We also organized visual data by providing detailed descriptions and labels for different image elements. This comprehensive approach created a more robust and universal data analysis and management system.
Thus, whether you are developing cutting-edge AI applications or refining existing models, our expertise, advanced tools, and rigorous processes ensure that your data is annotated to the highest standards. Partner with us to experience seamless, efficient, and secure data annotation services that drive innovation and success in your machine-learning projects.
Final thoughts
As we’ve explored, data annotation is the cornerstone that transforms raw data into structured and meaningful information, enabling AI models to learn and make accurate predictions. For beginners, understanding the nuances between data annotation and data labeling and mastering the steps involved in the annotation process is crucial.
As you move forward, remember that the quality of your annotations directly impacts the performance of your AI models. Invest time in setting up robust annotation guidelines, using the right tools, and ensuring thorough quality control to achieve the best results.
If you’re planning to outsource, here’s a helpful breakdown of the data annotation providers in 2025 with service comparisons and pricing tips.
Are you ready to take your data annotation to the next level? Our software development team simplifies and enhances the data annotation process. Contact us today to learn more about how our data processing services can support your AI projects and elevate your data annotation efforts.
FAQ
What is data annotation?
Data annotation is labeling or tagging data to make it understandable and usable for machine learning algorithms. This involves adding metadata to various data types, such as images, videos, audio, and text, to help AI models learn and make predictions.
What is the difference between data annotation and data labeling?
Data labeling typically refers to assigning predefined categories or tags to data points. It is a subset of data annotation focused on categorization. Data annotation is a broader term that contains data labeling and adds more detailed metadata.
How to do data annotation?
Performing data annotation involves several steps, and the process can vary depending on the type of data and the requirements of the AI project. Here’s a general guide: define objectives, choose the right tools, prepare your data, annotate the data, iterate and refine, and more.


