

The ability to scale data annotation is a key step for modern AI projects. AI models require a huge amount of data for training. Without high annotation quality assurance, models will not be able to correctly recognize objects, text, or behavior.
As projects grow, so does the amount of data. It is impossible for one person to process millions of images, videos, or texts. Therefore, teams are forced to increase the number of annotators.
The problem is that as the team grows, quality is easily lost. New employees make mistakes. Managers lose control over the process. As a result, the project slows down, and the model receives inaccurate data.
A real-life example. A startup developing a facial recognition system for security had a team of 10 annotators. When the database increased 10 times, the quality of annotations dropped by 15%. They began to waste time fixing errors.

Data annotation at scale solves several problems at once:
- allows you to process large amounts of data faster;
- maintains the accuracy of annotations;
- reduces the time it takes to get a model into production.
Proper scaling involves technology tools and organizational strategies. It combines AI assistance, clear instructions, and quality control. Without this step, modern AI projects simply cannot grow. Teams will spend months fixing errors and training new employees.
Scaling is not only about speed, but also about data stability. The accuracy and reliability of the model depends on the quality of annotations.
Common Challenges When Scaling
Scaling data annotation is a complex process. At first glance, it may seem that it is enough to simply increase the number of annotators. But in practice, team growth often leads to new problems. These problems can slow down the project, reduce data quality, and increase costs. Let’s consider the key challenges that teams face when scaling.
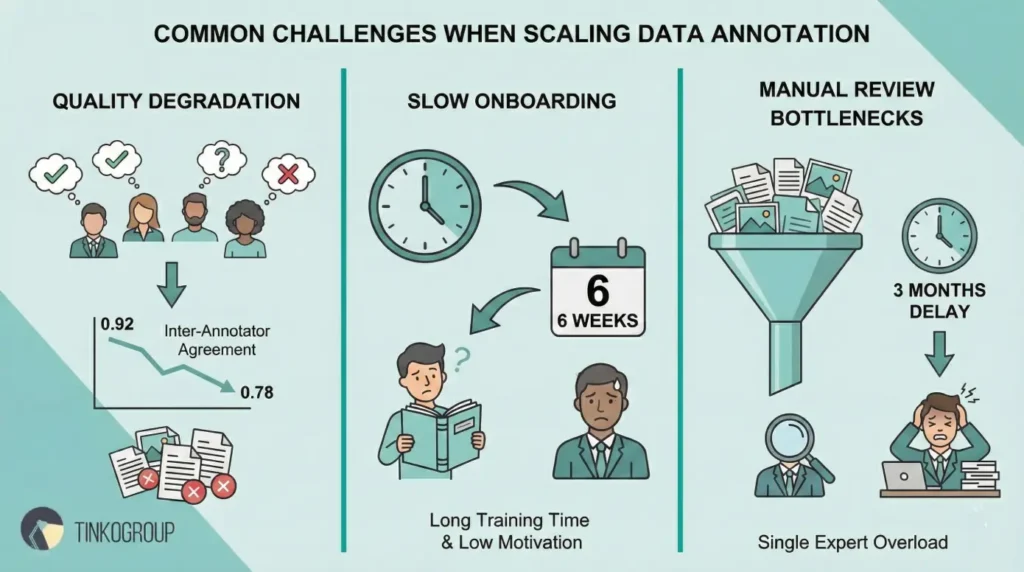
Quality Degradation with Larger Annotation Team
When the annotation team grows, the quality of the data often deteriorates. Each new employee interprets the labeling rules differently. Even experienced annotators can make mistakes when processing complex cases. Sometimes errors seem minor, but their impact increases when scaling. Even small labeling inconsistencies compound at scale and directly affect downstream performance, which is why correct annotations play a decisive role in detection model training. For example, a small inaccuracy on 100 images is unnoticeable, but on 100,000 images it is already a serious problem.
Another aspect is the difference in experience and skill level. Beginners usually make more mistakes, especially on complex tasks. Senior annotators can get used to their methods and make systematic errors.
A case study from Tinkogroup: the team of an NLP project for medical text labeling grew from 5 to 50 people. At the same time, the inter-annotator agreement fell from 0.92 to 0.78. This led to the need for additional checks and corrections, which slowed down the model training.
The quality problem is especially noticeable in projects with sensitive data, for example, in medicine or finance. Errors can lead to incorrect model conclusions and a decrease in trust in the product.
Slow Onboarding for New Annotators
Onboarding new annotators is one of the biggest challenges when scaling data labeling projects. Newcomers need time to understand the instructions, master the tools, and get used to the specifics of the project. In traditional approaches, training is often limited to reading documentation and participating in webinars, which takes a lot of time. For large teams, this method becomes extremely slow and ineffective.
Without dynamic instructions and visual examples, new employees often repeat the same mistakes. This increases the workload on QA and slows down the entire labeling process. Every additional hour spent on correcting newcomers’ mistakes affects the overall productivity of the team.
A case study from Tinkogroup: a startup developing a system for recognizing objects on video. Previously, training one new annotator took up to 6 weeks. After introducing interactive instructions with videos, visual examples, and descriptions of complex cases, the adaptation time was reduced to two weeks. Newcomers understood the rules faster, made fewer mistakes, and started making real contributions to the project faster
In addition to affecting speed, slow onboarding has a negative impact on the motivation of new employees. When they see themselves constantly making mistakes, their confidence in their abilities drops, which can lead to demotivation and increased turnover. Using dynamic guides, interactive examples, and regular feedback helps new annotators feel more confident and adapt to work processes faster.
Delays Due to Manual Review Bottlenecks
Manual check of markup is one of the main bottlenecks when scaling data annotation projects. When the data volume is small, manual check does not create problems. But when working with hundreds of thousands or millions of annotations, manual check becomes a huge burden for the team.
Every error requires correction, and sometimes correcting one annotation takes longer than its initial markup. This slows down the training of the model and increases the cost of the project. For teams that work with big data, manual check without automation can become a critical factor that can shift the project deadlines by weeks or even months.
A case study from Tinkogroup: a product classification project for a large online store. The team had 30 annotators, and all the results were manually checked by an expert. When the data volume began to grow rapidly, a serious bottleneck in the review process formed. As a result, the project deadlines shifted by three months, and the expert’s workload grew daily, which increased the risk of errors due to fatigue and overload.
The introduction of automated checks and peer reviews has helped reduce delays significantly. However, without multi-level QA, including expert review of complex cases, projects continue to face slowdowns and an increased risk of errors. Optimizing the review process through a combination of automated checks, peer reviews, and expert control allows you to scale data labeling without losing quality and minimize the impact of bottlenecks on project deadlines.
Strategies to Scale Data Annotation Without Losing Quality or Speed
Scaling the scale data annotation process without losing quality and speed requires a comprehensive approach. Simply increasing the number of annotators is not enough — it can lead to chaos, errors and slowdowns of the project. To maintain efficiency, it is necessary to work with technology, processes and the human factor at the same time.
The key point is that each part of the system must support the others. Technologies such as AI-assisted pre-labeling speed up routine work and reduce the workload on the team. Organizational solutions such as a modular team structure and automatic task distribution help to properly use the experience and skills of annotators. Dynamic instructions and multi-level QA pipelines ensure stable data quality and fast training of new employees.
Tinkogroup’s experience shows that successful scaling is possible only with the comprehensive implementation of these strategies. They help not only increase the amount of markup, but also maintain consistency, accuracy and speed of the team. Below, we will examine in detail the main strategies that have proven their effectiveness in real projects and show how they can be implemented in practice.
AI-Assisted Pre-Labeling for Efficiency Gains
One of the most powerful strategies for scaling data labeling is the use of AI-assisted pre-labeling. The essence of this approach is simple: artificial intelligence pre-labels data, and annotators check and correct the results. This method allows to significantly reduce the routine workload of the team and speeds up the labeling process without compromising quality.
In Tinkogroup projects, the use of an AI assistant gave impressive results. For example, when labeling images for an object recognition system, AI performed up to 70% of the primary work. Annotators remained only for complex, ambiguous cases, which allowed them to focus on the most critical aspects of labeling. As a result, the speed of data processing increased several times, and the IAA remained high.
The advantage of this approach is not only time saving, but also a reduction in human errors in routine tasks. AI performs standard operations stably, and only complex or controversial elements are checked manually. This is especially important when scaling a team: when a large number of new annotators join a project, pre-labeling helps maintain consistency and reduces the risk of system errors. It is important to remember that AI-assisted pre-labeling does not replace annotators completely. Its purpose is to speed up the process, ease the workload, and improve the overall efficiency of the team. But it is the combination of machine learning data annotation and human verification that allows projects to scale without losing quality.
Multi-Layer QA Pipelines
A key element of ensuring the quality of data labeling is multi-tiered QA pipelines. They allow combining three important levels of control: automated checks, peer review, and expert review. This approach ensures high data accuracy even when the team grows significantly.
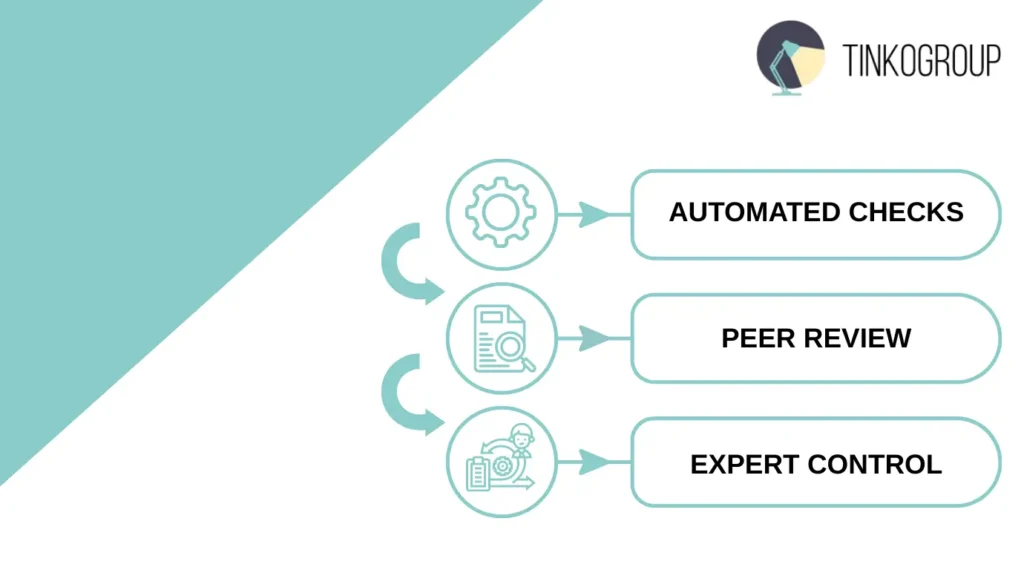
Automated checks perform basic quality control and identify obvious errors such as missing annotations, duplicates, or format inconsistencies. This level reduces the workload on humans, allowing annotators to focus on more complex aspects of labeling.
The next level is peer review, when annotators check each other’s work. This approach helps quickly find errors in large amounts of data and provides additional quality control. Peer review also serves as a learning tool because annotators see how their peers resolve controversial cases.
Expert review is used for complex or controversial cases where human judgment is important. Experts analyze ambiguous situations, correct the labeling, and update instructions for the team to reduce the number of errors in similar tasks in the future. A case study from Tinkogroup: a project to classify goods for a large e-commerce company. The data went through three QA levels: first, AI performed an automatic check, then a team of annotators conducted a peer review, and the final check was left to experts. The result was impressive: the number of critical errors decreased by 80%, and the markup speed increased by 2.5 times.
Advice from Tinkogroup experts: Create dashboards to track error types in real time. This helps to quickly identify systemic problems, promptly adjust instructions, and improve the quality of work of the entire team.
Dynamic Annotation Guidelines
Static instructions often become outdated or remain unclear to new employees. This shift toward living documentation reflects broader changes in how data annotation is evolving, where flexibility, rapid iteration, and continuous feedback are becoming standard. This is especially noticeable in projects with rapidly changing requirements, complex data, or a large number of annotators. In such conditions, dynamic instructions become critical. They include visual examples, video demonstrations, descriptions of complex cases and rare exceptions, which significantly facilitates the team’s work and reduces the number of errors.
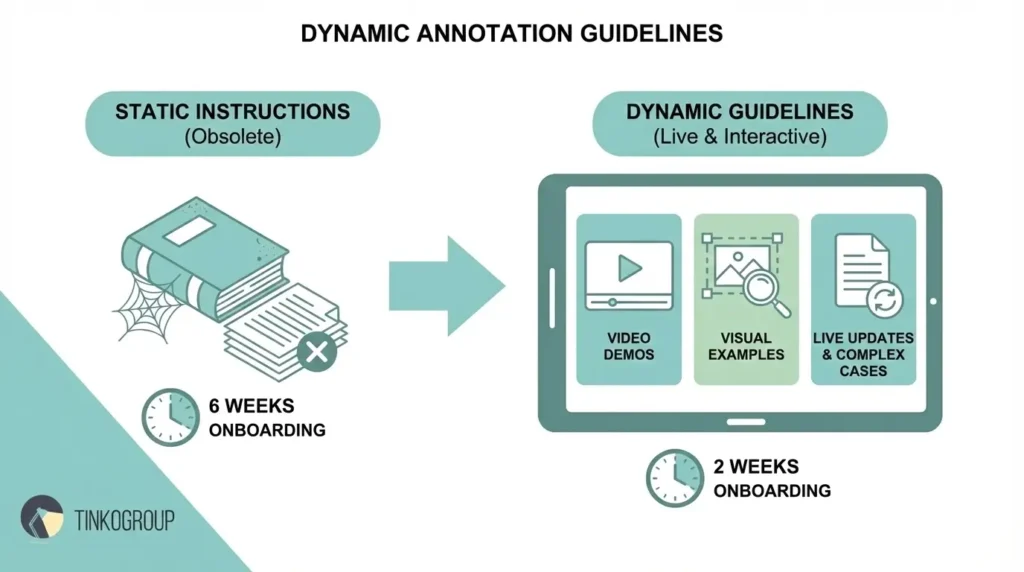
Live updates help keep instructions up-to-date, synchronizing them with changes in project requirements. Thanks to this, annotators always work with up-to-date rules, and the onboarding time for new employees is reduced. This approach also helps to avoid misunderstandings that can lead to system errors, especially when the team is growing quickly.
Advice from Tinkogroup experts: include complex cases, visual examples, and explanations of exceptions in instructions. This not only reduces the number of questions from annotators, but also speeds up the training of new employees, allowing them to achieve stable markup quality faster.
Modular Team Structure and Automated Task Routing
Organizing a team on a modular principle is one of the key ways to scale the data labeling process while maintaining quality and efficiency. The essence of the approach is that annotators are divided into groups depending on the complexity of the tasks and the level of experience. Simple tasks are performed by beginners, more complex ones by experienced employees, and specialized cases require the participation of experts.
Automated task distribution ensures that each annotator gets work that matches their skills. The system itself directs complex or specialized tasks to the most qualified employees, which helps to avoid errors that can occur with random distribution. This approach reduces the workload on experts and increases the overall productivity of the team.
Advice from Tinkogroup experts: regularly monitor the performance of annotators and redistribute tasks based on the analysis of results. This allows you to maintain a balance between speed and quality, avoid overloading individual employees and ensure stable project execution even when scaling the team.
Key Metrics to Measure Success
To scale data annotation effectively, it is important to measure success using key metrics. These help track the quality, speed, and efficiency of the team’s work. Below are the key metrics that every team should focus on.

Inter-Annotator Agreement (IAA)
Inter-Annotator Agreement (IAA) is a key metric that shows how consistently different annotators label the same data. Its main purpose is to measure the degree of agreement in understanding and applying instructions between people working on the same task. The higher this value, the more reliable the labeling is considered, as it reflects a uniform interpretation of the rules and criteria.
IAA is usually expressed as a coefficient, such as Cohen’s Kappa or Krippendorff’s Alpha, which take into account the probability of random coincidence. High values of these metrics mean that the labeling is not the result of random coincidences, but reflects real agreement between participants.
In real projects, it is important to monitor the IAA value throughout the entire work cycle, and not just at the data preparation stage. For example, a sharp drop in the value may indicate that the instructions have begun to be interpreted differently, or that new annotators are not sufficiently trained. This is a signal to revise the guides, conduct additional training, or hold calibration sessions where annotators work together to resolve controversial cases.
In addition, IAA helps to identify ambiguities in the data or rules themselves. If even experienced annotators disagree on the markup, this may mean that the wording of the instructions is too vague, and the examples in the guideline do not cover the full range of possible situations. In this case, improving IAA is directly related to improving the quality of the instructions and examples.
Annotation Throughput
Annotation throughput is a metric that reflects how many data units a team of annotators can process in a certain period of time. It helps to assess the team’s productivity and plan project deadlines. It is important to understand that high labeling speed without quality control can be dangerous: a large number of annotations performed quickly may contain errors that will subsequently negatively affect the model’s performance.
In real projects, Annotation throughput is measured differently depending on the type of data. For text tasks, this can be the number of documents or sentences processed in an hour or a day. For computer vision, it is the number of images or video frames. It is important to consider the complexity of the tasks: simple classification requires less time, while labeling complex objects in images or videos can take significantly more time per data unit.
The growth of throughput is directly related to the scaling of the team and the implementation of technological solutions. For example, the use of AI-assisted pre-labeling allows annotators to check pre-labeled data faster, which significantly increases the number of processed units without reducing quality. Also, a modular team structure and automatic distribution of tasks by annotators’ experience level help to evenly load the team and speed up the process.
Tracking throughput is important not only for measuring current efficiency, but also for predicting future needs. Understanding how much data the team can process in a week or month helps to adjust deadlines, resources, and the workload of annotators, which is especially important when scaling projects.
Error Rate
Error rate is a metric that reflects the number of errors made by annotators when labeling data. It is important to understand that errors come in different levels: critical and non-critical. Critical errors directly affect the performance of the model or the quality of the final product, such as an incorrect classification of a medical image or an incorrectly labeled object for an autonomous system. Non-critical errors usually do not significantly affect the model’s output, such as a missed auxiliary tag or a small typo in text labeling.
In real projects, analyzing the Error rate helps to understand where systemic problems arise, which tasks cause the greatest difficulties for annotators, and which areas of the data require additional attention. For example, if critical errors are concentrated in one class of objects, this may mean that the instructions for this type of data are not clear enough or that annotators need additional training.
Monitoring the Error rate is especially important when scaling teams. As the number of annotators increases, the likelihood of errors increases, and without a clear QA system, they can quickly accumulate. A multi-level QA pipeline, including automated checks, peer review, and expert control, helps reduce the number of critical errors and maintain stable data quality. Regular monitoring of the Error Rate helps not only maintain quality, but also optimizes training processes, task distribution, and the use of technological tools such as AI-assisted pre-labeling. Combined with other metrics such as Annotation throughput and IAA, this indicator gives a complete picture of how efficiently and reliably the annotation team works.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Time-to-Quality
Time-to-quality is a metric that shows how long it takes a new annotator to reach the target level of accuracy in data markup. It is important for assessing the effectiveness of the onboarding process and training of new team members. The faster an employee reaches the required level of accuracy, the faster they begin to contribute real value to the project without increasing the risk of errors.
In real projects, time-to-quality is measured individually for each new annotator and is often averaged for the entire team. If a newcomer takes too long to reach the target accuracy. This is a signal to review the instructions, training methods, or feedback system. For example, static text instructions may not be clear enough. And the lack of visual examples complicates the understanding of complex cases.
Tinkogroup’s experience shows that the introduction of dynamic instructions, visual examples, and interactive guides can significantly reduce time-to-quality. Newcomers quickly navigate the tasks, make fewer mistakes, and feel confident. The process is also accelerated by distributing tasks by complexity level: newcomers are given simpler cases, gradually increasing their complexity as their competencies grow. Time-to-quality control helps not only optimize the training process, but also plan team scaling. Understanding how much time new annotators need to achieve the desired level of accuracy allows you to allocate resources in advance and adjust the workload, avoiding delays in the project.
Mini Case Study
Let’s introduce Tinkogroup’s project on image labeling for an AI object recognition model. At the beginning, everything was relatively calm: a team of 10 annotators processed data without haste. But after a few months, the amount of data grew 15 times. The team realized that without scaling, the project simply would not have time.
Problems at the Start
The team’s growth turned out to be more difficult than expected. New annotators often made mistakes due to unclear instructions. Older employees were overloaded trying to check someone else’s work. Manual checking became a real bottleneck: checking each annotation took hours, and sometimes days. Everyone felt stressed and tired, and it seemed that the project could stall.
Team Solutions
Tinkogroup took a comprehensive approach. First, they implemented AI-assisted pre-labeling. Artificial intelligence labeled images in advance, and annotators checked and corrected them. This immediately reduced the monotony of the work and gave the feeling that they were working “in tandem” with the machine.
Secondly, they created a multi-level QA pipeline. Automatic checks caught simple errors, peer-review allowed the team to check each other, and experts solved complex cases. Each annotator could now see the results of their work and understand where accuracy could be improved.
Thirdly, the instructions became dynamic. Video explanations, visual examples, explanations of complex cases — all this helped newcomers get into the process faster. New employees stopped getting lost and began to produce results in just a couple of weeks
Finally, the team was restructured according to the modular principle. Tasks were distributed automatically based on experience level. Experienced annotators took complex cases, newcomers — simple ones, gradually moving on to more complex ones.
Results
In 6 months, the team grew from 10 to 150 people.
- The speed of work increased 6 times: now the team processed 120,000 annotations per week instead of 20,000
- The quality remained high: IAA reached 0.91.
- Critical errors decreased from 3% to 0.7%.
- Newcomers reached the target accuracy in just 10 days instead of 4 weeks.
Summary
Scaling a team while maintaining quality is possible. The main thing is to combine technological solutions with proper work organization and constant feedback. This case shows that with the right strategy, team growth does not lead to chaos. Annotators feel confident, speed increases, and data quality remains high.
Expert Tips
Scaling data annotation is always a combination of technology and the human factor. The experience of the Tinkogroup team shows that even the most advanced tools cannot replace the proper organization of work and proper training of annotators. In this section, we share four key tips that help speed up the data labeling process, maintain high quality, and make the team’s work more efficient. Each tip is based on Tinkogroup’s real-life experience and has been tested in practice in projects of various scales.
Expert Tip #1: Use AI-Assisted Labeling for Routine Tasks
In projects with large amounts of data, annotators quickly get tired of repetitive tasks. Tinkogroup implemented an AI assistant that pre-labeled images and texts. Annotators checked and corrected only complex or controversial cases. Result: speed doubled, and quality did not suffer. Advice: start with a small pilot dataset to evaluate the accuracy of AI before scaling to the entire project.
Expert Tip #2: Build a Multi-Level QA Pipeline
The usual manual check slows down the process and creates stress for the team. Tinkogroup implemented a three-level QA: automatic checks → peer review → expert control. Annotators received quick feedback, and experts focused on complex cases.
Expert Tip #3: Make instructions Dynamic and Visual
Static instructions become outdated and do not help beginners. Tinkogroup created dynamic guides with videos, images, and examples of complex cases. Beginners reached the target accuracy faster, and experts spent less time on explanations. Tip: Update instructions as new data types and rare exceptions appear. Visual examples reduce the number of errors by 30–40%.
Expert Tip #4: Organize Modular Teams and Automate Task Assignment
When the number of annotators grows, manual task assignment becomes ineffective. Tinkogroup divided the team by experience levels. Beginners worked on simple tasks, experienced annotators took on complex cases. The system automatically assigned tasks depending on their qualifications.
Conclusion
To sum up, success directly depends on the right approach, attention to detail and the use of proven strategies. Following the tips above, you can avoid common mistakes and achieve better results.
Tinkogroup is ready to help you at every stage — from consultation to the implementation of comprehensive solutions tailored to your needs. We will provide an individual approach, professional support and a guaranteed result.
Find out more about how we can help you by clicking on the link.
Why does data annotation quality usually drop when teams scale?
When annotation teams grow, differences in experience, interpretation of guidelines, and onboarding speed lead to inconsistencies. Without AI assistance, dynamic guidelines, and multi-layer quality control, errors accumulate quickly and directly impact model performance.
Can data annotation be scaled without sacrificing accuracy?
Yes. Successful scaling combines AI-assisted pre-labeling, modular team structures, automated task routing, and multi-level QA pipelines. This approach increases throughput while maintaining high inter-annotator agreement and low error rates.
What metrics should be tracked when scaling data annotation?
Key metrics include Inter-Annotator Agreement (IAA) to measure consistency, Annotation Throughput to track productivity, Error Rate to monitor quality risks, and Time-to-Quality to evaluate onboarding efficiency for new annotators.


