

Here’s the uncomfortable truth: for the last decade, the AI industry has coasted on static laurels. We largely ignored tools like temporal segmentation because we obsessed over one narrow question: “What is in the frame?” We became terrifyingly good at drawing pixel-perfect boxes around pedestrians. But in 2026, identifying objects in a vacuum is just table stakes. It equals reading individual syllables while the rest of the world reads complex literature.
Today, the high-stakes question has changed. Now, we ask: “What is happening over time?” The difference between these two questions is the chasm between raw data and actual intelligence. You can build a model that recognizes a person holding a scalpel with 99.9% precision. Still, your AI is functionally useless if it cannot distinguish between a surgeon making a life-saving incision and an untrained hand causing a medical error. To understand the “why” and the “how,” we need more than pixels; we need the flow of time.
To define it without the academic jargon: what is temporal segmentation? It is the process of surgically partitioning a continuous video stream into meaningful, non-overlapping segments. Each segment must correspond to a discrete, legally defined action or event. We are taking the chaotic, high-dimensional soup of a video file and transmuting it into a structured chronology: “wind-up,” “impact,” “follow-through.”
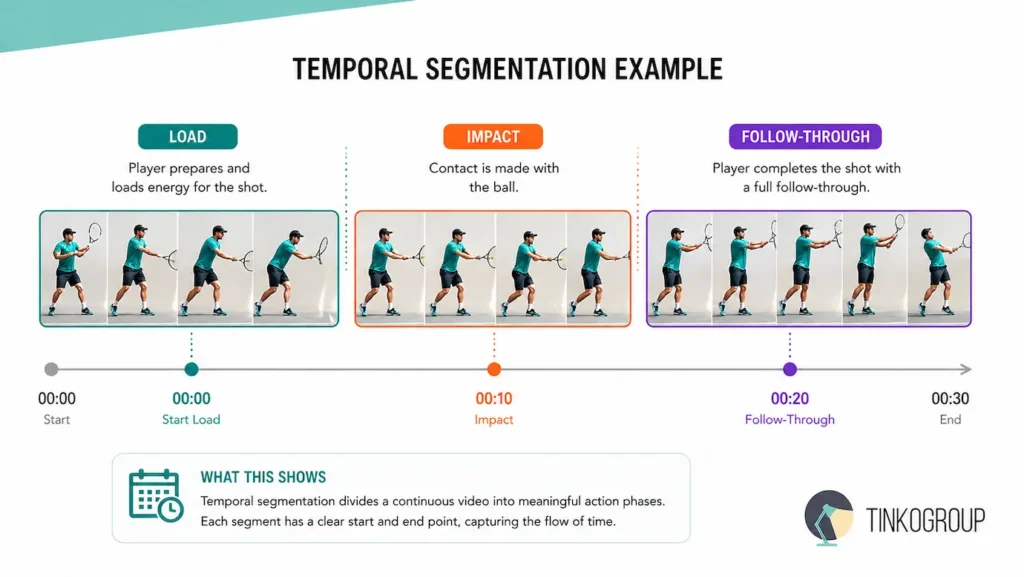
Why is this the undisputed foundation for Video Understanding (VU)? Because without video temporal segmentation, a video is just a deck of cards scattered on the floor. By breaking the stream into semantic blocks, we allow the machine to reason about causality. It is the bedrock of computer vision for video. Whether you are building elite sports analytics or high-security event detection AI, you aren’t just looking for movement — you are looking for the logic behind that movement.
In this article, we aren’t going to regurgitate documentation. We are going to dive into how temporal segmentation in video acts as the “nervous system” that finally allows cameras to do more than just record — it allows them to interpret. For any serious lead managing training data for video models, this is where the real work begins.
Temporal Segmentation vs. Spatial Segmentation: The Battle for the Third Dimension
In the world of video data labeling, we often hear people talk about “3D data.” But let’s be clear: we aren’t talking about depth sensors or LiDAR. We are talking about the Temporal Axis.
To understand the evolution of temporal action localization, you first have to respect the limitations of the spatial world. Spatial Segmentation is about boundaries in a static universe. It asks: “Which pixels belong to the car, and which belong to the road?” It’s a geometry problem. You draw a polygon, you classify the mask, and you move on.
However, Temporal Segmentation is about boundaries in a fluid universe. It doesn’t care where the car is in the frame; it cares when the ‘turn’ began and when the car completed the “lane change.” While spatial labeling defines the object, temporal labeling defines the intent.
The Concept of the “Third Dimension” (Time) in Data Labeling
Think of a video as a stack of transparent photographs. Spatial labeling is like drawing on a single photo. Temporal action segmentation is like driving a needle through the entire stack.
When we label the “Third Dimension,” we are mapping the persistence of an action. This is the hardest part of machine learning for action detection. Why? Because objects have clear edges (the metal of a car vs. the asphalt), but actions do not.
- The blur problem. In spatial data, a blurry frame is a “bad sample.”
- The temporal reality. In temporal data, motion blur is a vital signal of speed and direction.
If you ignore the temporal dimension, you are essentially trying to understand a movie by looking at a single, random frame every ten minutes. You see a man in mid-air — is he jumping for joy, or is he falling? Without the T-axis, your AI is guessing.
Why Traditional Image Annotation Isn’t Enough for Behavioral AI
This is where I see most startups fail. They try to apply “image thinking” to “video problems.” They think that if they have 100,000 labeled images of a “hammer,” they can build an AI that understands “carpentry.”
They are wrong. Behavioral AI requires a totally different architecture for its activity recognition datasets. Traditional annotation is “stateless” — Frame A has no memory of Frame B. But behavior is entirely dependent on the state.
- Causality. To recognize a “theft” in a retail setting, the AI must see the sequence: (1) Item on shelf -> (2) Hand reaches -> (3) Item enters pocket. An image-based model only sees “hand near pocket,” which is a perfectly legal action.
- The “Flicker” effect. If you use image-based tools for video, your labels will “flicker.” Frame 1 is “Walking,” Frame 2 is “Undefined” because of a slight obstruction, and Frame 3 is “Walking.” This noise kills the gradient in Action recognition models.
- The metadata load. Frame-level annotation for behavioral AI doesn’t just need a label; it needs a “flow.” It needs to understand that the pixels in Frame 100 are the same physical matter as the pixels in Frame 1.
Traditional annotation treats time as a series of disconnected snapshots. Video temporal segmentation treats time as a narrative. In high-stakes AI applications — from autonomous surgery to drone-based surveillance — the narrative is the only thing that matters.
Types of Temporal Segmentation
When we discuss the taxonomy of temporal video segmentation, we are really discussing the density of human intent captured in a digital stream. Viewing these categories as simple variations of the same task is a mistake. In reality, they represent fundamentally different mathematical challenges that require unique neural architectures and distinct approaches to video data labeling.
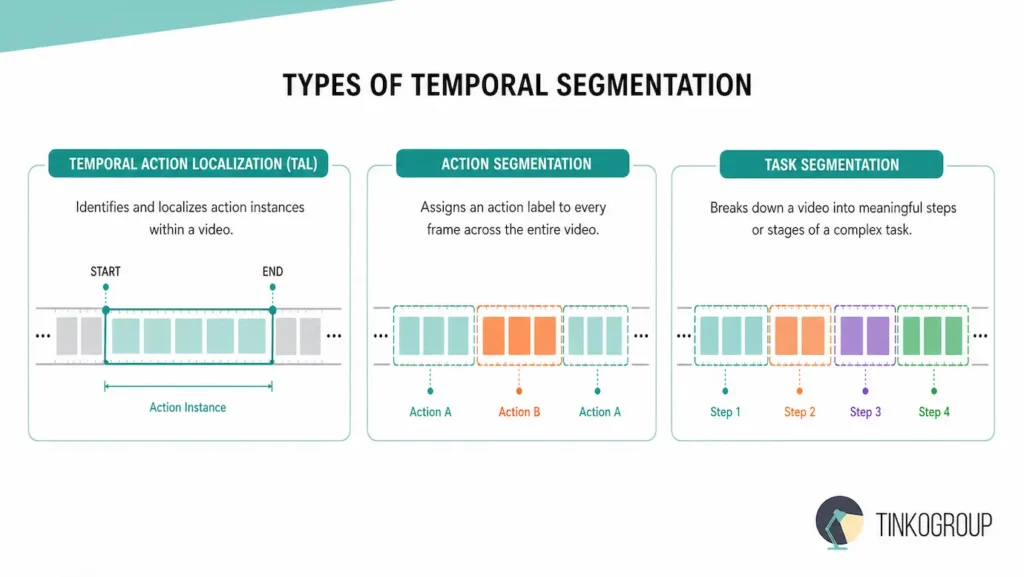
The Precision of Temporal Action Localization (TAL)
The most common entry point for most data scientists is temporal action localization. In this paradigm, we treat the video as a sparse environment. Imagine a ten-hour surveillance feed from a high-security facility. For 99% of that duration, nothing of interest happens — just the static noise of an empty hallway. The goal of TAL is to pinpoint the exact “needle in the haystack.” It identifies the specific temporal interval where a person might be falling, or a vehicle is making an unauthorized turn.
This is the bedrock of event detection AI. Mathematically, TAL functions much like an object detector in the spatial world; it generates “proposals” for where an action might be, and then a secondary network refines those boundaries and classifies the event. This is an efficiency-first approach, designed to filter out the “background” class so that human operators or downstream AI models only focus on the critical segments.
The Continuous Flow of Temporal Action Segmentation
However, when the complexity of the environment increases — such as in a busy kitchen or a manufacturing plant — sparse localization is no longer sufficient. Here we enter the much more grueling territory of temporal action segmentation. Unlike localization, which only cares about the “highlights,” action segmentation demands a classification for every single frame in the video. There is no background class to hide in. Every millisecond must be accounted for.
If a person is walking, then transitions into a run, and finally comes to a stop, the model must identify the exact frame where the kinetic energy shifted. This creates a continuous narrative of movement. This density is why frame-level annotation becomes so resource-intensive. You aren’t just looking for an event; you are mapping the entire lifecycle of human behavior. This approach is vital for machine learning for action detection in robotics, where a machine needs constant feedback on its environment.
Logical Boundaries and Event Transitions
We also have to consider the foundational role of Boundary Detection. Before a model can even begin to classify an action, it often has to solve a more primitive problem: where does one event end and another begin? In the early days of Google, we saw this in basic shot transition detection for video indexing.
Today, it has evolved into something much more subtle. We now look for logical boundaries — moments where a tennis player’s “serve” physically concludes, and the “volley” phase begins. Without high-precision boundary detection, the rest of the Action recognition pipeline suffers from “boundary noise,” where the start and end of actions become blurred, leading to catastrophic errors in downstream analytics. Identifying these transition points is a core requirement for creating high-quality activity recognition datasets.
Fine-grained Analysis: Temporal Action Segmentation vs Task Segmentation
Finally, we reach the pinnacle of this field: Fine-grained Segmentation. This is where the nuanced debate of temporal action segmentation vs task segmentation truly lives. In a surgical or industrial setting, simply knowing that a person is “moving their hand” is useless. That is a kinetic action, but it doesn’t describe the objective.
Temporal task segmentation looks past the physical movement to identify the stage of a complex process. In a surgical video, this means distinguishing between “making an incision” and “suturing.” One requires a specific set of tools and risks; the other involves entirely different protocols. Fine-grained segmentation breaks these tasks down into sub-activities that might only last a few frames.
This is the “high-resolution” end of video temporal segmentation, and only this approach builds AI that truly understands the intricacies of professional human labor.
Key Use Cases: Where Every Second Counts
The real-world application of temporal video segmentation requires a move away from generalist models toward domain-specific precision. Whether it is on a football pitch or in an operating theater, the temporal boundaries must be absolute.
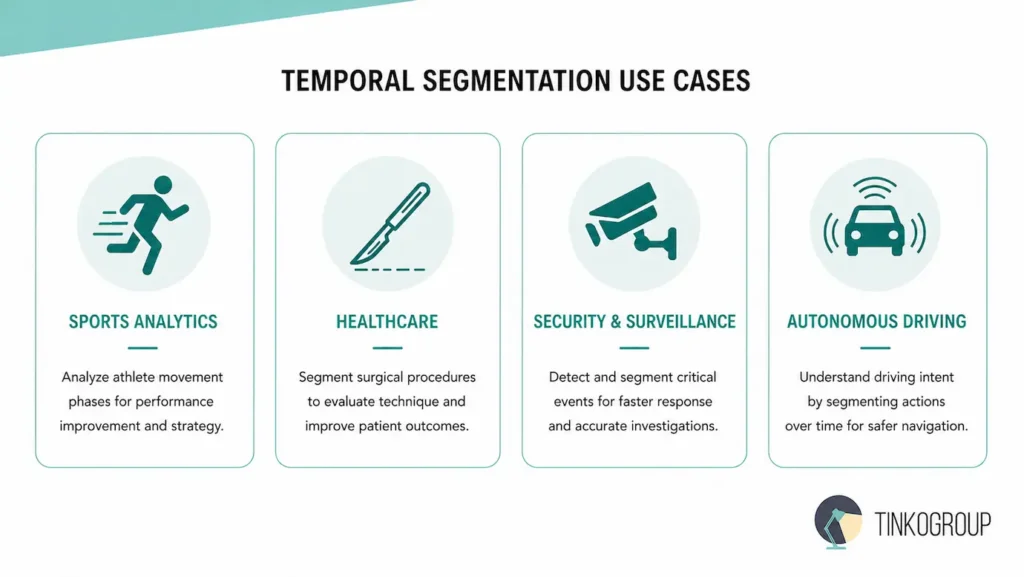
Revolutionizing Sports Analytics
In professional sports, mere milliseconds separate an elite athlete from a hobbyist. Action recognition allows teams to automate the analysis of thousands of hours of footage that used to require manual tagging by roomfuls of interns.
- Performance optimization. For a golf swing or a tennis serve, temporal action localization identifies the precise moments of “loading,” “impact,” and “follow-through.” This allows for biomechanical overlays that show exactly where a player’s form is breaking down.
- Automated event indexing. Broadcasters use event detection AI to instantly find goals, fouls, or yellow-card incidents across multiple simultaneous matches, enabling real-time highlight generation.
- Tactical analysis. By using activity recognition datasets, coaches can analyze “off-ball” movements, segmenting a player’s entire game into “sprinting,” “jogging,” and “pressing” to manage fatigue and strategy.
High-Stakes Security and Surveillance
Traditional motion detection is the bane of security leads — it triggers for a stray cat just as easily as it does for a burglar. Machine learning for action detection changes the paradigm from “motion” to “behavior.”
- Anomaly detection. In retail, the system ignores someone picking up a shirt but flags the specific temporal sequence of “concealing an item” versus “placing it in a cart.”
- Violence prevention. In public spaces, temporal segmentation in video can distinguish between a friendly hug and the start of a physical fight by analyzing the kinetic intensity and duration of the interaction.
- Unauthorized entry. Beyond just seeing a face, the AI can detect the “tailgating” action — where a second person enters a secure door before it closes — which is a temporal sequence that static image recognition simply cannot solve.
Healthcare and the Digital Surgeon
The operating room is perhaps the most demanding environment for temporal task segmentation. Here, AI acts as a “black box” recorder that helps improve patient outcomes.
- Surgical workflow analysis. By breaking a surgery into phases (e.g., ‘access,’ ‘resection,’ ‘closure’), hospitals can identify bottlenecks and ensure staff follow every safety protocol for the required duration.
- Training and feedback. Junior surgeons can compare their movements against training data for video models featuring expert performances to receive ‘frame-level’ critiques on their economy of motion.
- Safety alerts. If a surgeon skips a critical step in a checklist or performs it out of sequence, the AI can trigger a real-time alert, potentially preventing a fatal error.
Predictive Intelligence in Autonomous Driving
For a self-driving car, knowing that a pedestrian is present is only half the battle. The car must predict what the pedestrian will do next.
- Intent recognition. Using video temporal segmentation, the vehicle analyzes the subtle temporal cues of a person standing at a curb — the weight shift, the turn of the head — to distinguish “standing still” from “about to cross.”
- Reactive maneuvering. If a cyclist begins a “left turn” gesture, the car needs to recognize the start of that temporal boundary immediately to adjust its braking path. This is where frame-level annotation saves lives.
Scalable Content Moderation
In the era of 24/7 livestreams, human moderators cannot keep up. Computer vision for video is the only way to police the digital frontier at scale.
- Prohibited content flagging. Automated systems scan long-form videos for specific temporal signatures of violence, illegal acts, or copyrighted broadcasts, flagging the exact segments for human review.
- Ad placement. By identifying the “natural breaks” in content using boundary detection, platforms can insert advertisements without disrupting the viewer’s experience, maximizing revenue without sacrificing engagement.
The Challenges of Video Data Quality
In my years moderating for Google, I’ve seen thousands of “perfect” models fail the second they hit real-world video. Why? Because video data is messy, heavy, and fundamentally subjective. Most data scientists treat video like a sequence of images. That is their first — and often fatal — mistake.
The Curse of Ambiguous Boundaries
The biggest lie in video data labeling is that actions have a clear start and end. They don’t.
Take a “jump” in a sports analytics context. When exactly does it start? Is it the moment the knees begin to bend? Is it the microsecond the heels leave the ground? Or is it the shift in the center of gravity? There is no universal physical law that defines these boundaries. This is the problem of subjective perception.
If you have ten annotators, you will get ten different [start_time, end_time] pairs. This “boundary noise” creates massive instability in temporal action localization. If your training labels are off by even five frames, your loss function will never converge. To solve this, you need more than just “labelers” — you need a rigid, standardized taxonomy that defines the atomic start of every movement.
Fighting the “Flicker” of Temporal Inconsistency
In the early days of action recognition, we saw a recurring nightmare: “flickering” labels.
Imagine a model analyzing a surgical video: it identifies “suturing” for 30 frames, briefly jumps to “cutting,” then snaps back. This Temporal Consistency failure collapses the action’s entire logic. Unlike spatial errors, where one wrong pixel matters little, misaligned frames destroy temporal understanding. Preventing flickering labels requires frame-level annotation that respects the previous frame’s state—you cannot label Frame B without knowing Frame A.
Consequently, “stateless” image tools remain useless for high-precision computer vision for video. Many advanced video AI systems now depend on high-density keypoint tracking to maintain temporal consistency and accurately model movement, intent, and biomechanical behavior across frames.
Long-Range Dependencies and the Context Trap
The hardest challenge in machine learning for action detection. Most modern neural networks have a “short memory.” They can look at 10 or 20 frames and tell you what’s happening. But what if the action lasts an hour?
In a complex surgical procedure or a long-form livestream, the context from the first ten minutes radically changes the meaning of the last ten minutes. Handling these long-range dependencies is a massive technical hurdle. If your model doesn’t remember the beginning, it can’t perform accurate temporal task segmentation at the end. You need specialized architectures — like Long-form Transformers or Dilated TCNs — that can hold hours of context without exploding your VRAM.
The Sheer Weight of Data Volume
Let’s talk logistics. An image is a few kilobytes. A high-resolution video at 60fps is a gargantuan beast.
When you scale activity recognition datasets, you aren’t just dealing with code; you are dealing with massive infrastructure. Moving, storing, and decoding petabytes of video for training is a logistical nightmare that stops many teams in their tracks. The “weight” of video data means that every mistake in your video temporal segmentation strategy is magnified. If you choose the wrong encoding format or the wrong sampling rate, you’ve just wasted six months and a million dollars in computing.
Best Practices for High-Precision Video Labeling
In my tenure moderating technical content for Google, I’ve seen the “labeling debt” sink more startups than poor code ever did. When you are dealing with temporal segmentation, “good enough” is a death sentence for your F1 score. You need a strategy that balances human intuition with algorithmic efficiency.
Frame-by-Frame vs. Keyframe Interpolation: The Strategic Trade-off
The most common question I get from AI Product Managers is: “Do we really need to label every frame?” The answer is a frustrating “it depends.”
Frame-by-Frame labeling is the gold standard for frame-level annotation. High-velocity actions demand it — think of a surgeon making a micro-incision or a sprinter’s foot hitting the track. If the action is fast and the background is dynamic, you cannot trust an algorithm to guess what happens between Point A and Point B. You pay for this in time and cost, but you buy a model that actually understands the “physics” of the movement.
On the other hand, Keyframe Interpolation is your best friend for slow-moving or predictable actions. By labeling only the “anchor” frames and letting a linear or spline-based algorithm fill the gaps, you can cut your temporal video segmentation costs by 80%. However, the danger here is the “drift.” If the object rotates or is briefly occluded, interpolation creates “hallucinated” labels that poison your activity recognition datasets. A veteran team knows exactly when to switch gears: interpolation for the “setup,” frame-by-frame for the “impact.”
Using Multi-view Data: The Truth is in the Angles
In complex environments like retail or professional sports, a single camera angle is a lie. Occlusion is the enemy of temporal action localization. If a person puts an item in their pocket, but their back is to the camera, the temporal boundary is lost.
To achieve true high-precision temporal segmentation, you must synchronize multiple camera angles. When you have three synchronized views, a “hidden” action in Camera A becomes a “clear” action in Camera B. This multi-view approach allows annotators to pin the exact frame of an event with surgical precision. It turns a 2D guessing game into a 3D ground truth. If you aren’t using multi-view data for your training data for video models, you are essentially training your AI to be blind in one eye.
Standardizing Action Taxonomies: Defining the Atomic Unit
The most expensive mistake in event detection AI is failing to define a “Start” and a “Stop.” If you tell ten people to label a “run,” one will start when the person leans forward, and another will start when the first foot leaves the ground. This creates a “smearing” effect in your data that no amount of computation can fix.
You must create a “Protocol Bible.” This document should define the atomic unit of every action.
- The “Start” trigger. For a “fall” detection model, does the event start at the loss of balance or the moment of impact?
- The “Stop” trigger. Does a “suture” end when the needle passes through the skin or when the knot is tightened?
Standardizing your taxonomy ensures that your temporal action segmentation remains consistent across thousands of hours of video. It eliminates the “subjective noise” I talked about earlier and ensures that your model is learning physics, not human opinion.
Tinkogroup’s Edge in Video Annotation
What most teams in AI don’t advertise is that everyone is drowning in raw data. Having petabytes of footage is easy; having petabytes of useful footage is a Herculean task. Tinkogroup has built its reputation by solving the “unsolvable” friction points in video data labeling that keep most CTOs awake at night.
Mastering the Infrastructure of Massive Video Datasets
When you move from image sets to video, your storage and compute requirements don’t just grow — they explode. Tinkogroup’s first true “edge” is our custom-built data pipeline designed specifically for temporal video segmentation. We don’t just dump files onto a server. We utilize an elastic, cloud-native architecture that allows for rapid decoding and high-speed streaming of HD footage to distributed teams of annotators without latency.
In my experience at Google, latency is the silent killer of quality. If an annotator has to wait three seconds for a frame to load, they lose their “rhythm,” and their temporal accuracy drops. Tinkogroup eliminates this. We manage the massive weight of training data for video models by using smart-sharding and specialized video codecs that preserve the metadata required for frame-level annotation while keeping the workflow fluid.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

The Human-in-the-loop: Refining Temporal Proposals
There is a dangerous myth that AI can label itself. While we use advanced models to generate “temporal proposals” — the rough [start_time, end_time] of an action — we know that these models often hallucinate or “smear” the boundaries. This is where Tinkogroup’s Human-in-the-loop (HITL) system becomes critical.
Our process doesn’t start with a blank timeline. It starts with an AI-generated draft of temporal action localization. Then, our expert human annotators — specialists in domains like surgery or sports — review and ‘snap’ those boundaries into place.
This hybrid approach allows us to achieve a scale that is impossible with manual labeling alone, while maintaining a level of precision that “fully automated” systems can only dream of. We use the AI for the heavy lifting and the human for the final 1% of truth that defines a high-performing action recognition model.
Eliminating “Label Noise” in Complex Sequences
If you’ve ever looked at a raw dataset for temporal action segmentation, you’ve seen the “noise” — clashing labels, overlapping timestamps, and logical inconsistencies. At Tinkogroup, we view label noise as a systemic disease. To cure it, we’ve implemented a three-tier Quality Control (QC) protocol that is unique in the industry.
First, automated sanity checks prevent physically impossible action overlaps. Second, our double-blind review process for temporal task segmentation requires two experts to label segments independently; if boundaries miss a three-frame tolerance, the system flags them for senior arbitration. Finally, statistical noise filters catch annotators deviating from the ground truth. This strict rigor ensures our activity recognition datasets remain the cleanest in the industry.
Conclusion & The Future of Video AI
As we look toward the horizon of computer vision for video, the industry is moving away from the “brute force” method of labeling millions of specific examples. We are entering the era of generalized intelligence, but ironically, this makes the foundational work of temporal segmentation more important than ever, not less.
The Rise of Zero-Shot Action Recognition
The most exciting frontier in action recognition today is zero-shot learning. This is the ability of a model to identify an action it has never seen in its training set. Imagine an AI that can recognize a “robbery” or a “surgical complication” simply because it understands the underlying concepts of “force,” “concealment,” or “vessel rupture” described in natural language.
However, zero-shot models are only as good as their temporal resolution. To understand a novel action, the AI must still be able to parse the video into logical segments. It needs to know where one motion ends, and the next begins, to compare those “motion primitives” against its internal knowledge base. Without high-quality temporal action localization to define these primitives, zero-shot models become lost in the visual noise.
Why Temporal Segmentation is Key to “Reasoning AI”
The long-term goal for the industry is “Reasoning AI” — a system that doesn’t just flag an event but understands why it happened and what is likely to happen next. This requires a transition from temporal action segmentation vs task segmentation to a unified “Temporal Logic.”
When AI segments video into tasks, it begins to understand causality. If a model sees a “liquid spill” followed by a “person slipping” after learning from a temporal video segmentation dataset that emphasizes their link, it grasps physical laws. This forms the foundation of “World Models”—AI capable of simulating reality. For autonomous vehicles and robotics, this temporal reasoning separates a machine blindly following a script from one that truly understands its environment.
Final Thoughts for the Data-Driven Leader
If you are a data scientist or a Tech Lead, don’t be fooled by the hype of “unsupervised learning.” The most advanced models in the world — from OpenAI’s Sora to the latest surgical robots — rely on meticulously curated training data for video models. The precision of your frame-level annotation today determines the “IQ” of your model tomorrow.
In the end, the video is just a series of moments. How you choose to segment, label, and understand those moments will define your competitive edge in the decade of video AI.
Ready to build a video AI that actually understands movement? Contact Tinkogroup and get a custom annotation strategy for your project.
What is temporal segmentation in video AI?
Temporal segmentation is the process of dividing a video into meaningful action-based segments over time. It helps AI systems understand not only what appears in a frame, but also what is happening and when an action starts or ends.
What is the difference between temporal segmentation and spatial segmentation?
Spatial segmentation focuses on identifying objects within a single frame, while temporal segmentation analyzes actions and event transitions across multiple frames in a video sequence. In simple terms, spatial segmentation understands “where,” and temporal segmentation understands “when.”
Why is temporal segmentation important for AI models?
Temporal segmentation improves the accuracy of action recognition, behavioral analysis, surveillance systems, sports analytics, healthcare AI, and autonomous driving models. It allows AI to understand sequences of events instead of isolated images, making predictions and decision-making more reliable.


