

Have you noticed how technology has changed the way we search for information? In the 1990s, researchers had to visit libraries, spend days in archives, and manually gather sources. Publication research today takes seconds. Just type a few words into Google Scholar, JSTOR, or PubMed, and you’ll get hundreds of thousands of results right away, including articles, reports, studies, statistics, and opinions.
But here is the paradox of modern scholarship – you find data in seconds, but its reliability is a big question. We live in an age of “information overload.” Some studies are outdated; others are biased or contradictory. Over 5 million scholarly articles enter the academic record each year, and a shocking number come from predatory journals that mimic legitimate outlets but skip peer review entirely. One weak source in a small project is manageable. In a systematic literature review of 500 sources, that same weak source can distort the entire conclusion.
Academic and publication research is the systematic gathering, verification, and synthesis of evidence to support scholarly work (journal articles, dissertations, or conference papers) or high-authority editorial content (industry white papers, government reports, or premium news analysis). Casual browsing is not sufficient. You must treat information as proof. That means you need to know where the information comes from, check that it is real and trustworthy, and clearly explain how you deal with different or conflicting sources.
Many people rely on technology. Of course, AI speeds up research. However, successful publication research still depends on human verification and critical analysis. AI tools sort data, summarize papers, and help researchers discover patterns. But they cannot replace human critical thinking or careful verification. Doing research at a large scale without losing quality requires both smart search tools and human judgment.
Evidence-based research requires a blend of advanced search techniques and human expertise. This article will show these best practices in a simple way, especially for teams and organizations that handle large amounts of research and need to keep it accurate and reliable.
Foundations of Rigorous Academic Research
Before you start a large publication research project, you need a strong foundation for evaluating and organizing evidence. In academic work, you should know how to judge sources properly. Some sources are very reliable and should be your main support. Others are weaker, and it’s better to use these as background or extra detail.
Primary vs. Secondary Sources: How to Build a Hierarchy of Evidence
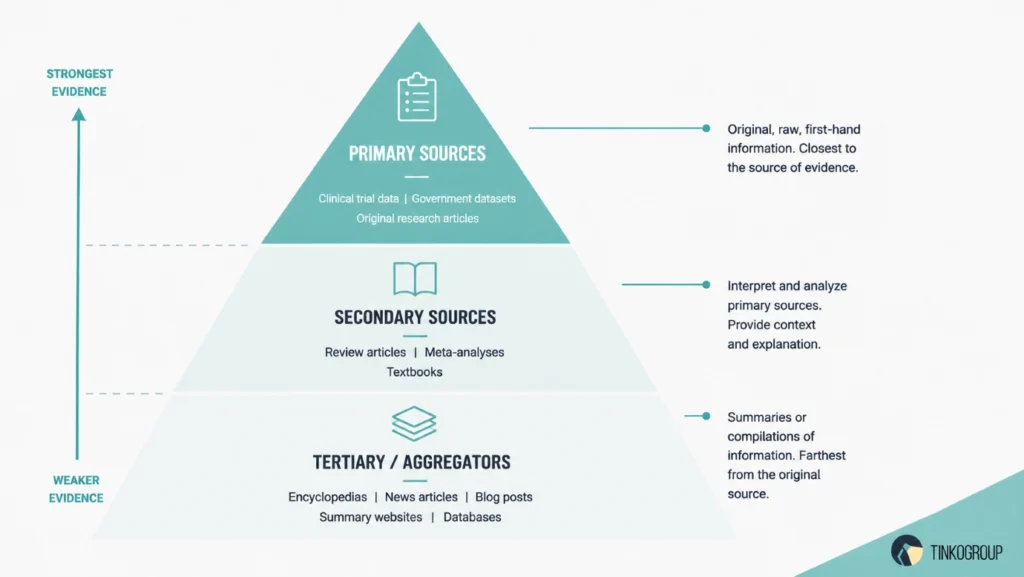
One of the most important skills in publication research is understanding the difference between primary and secondary sources. Imagine you are writing about the long-term health effects of a specific medication. You locate two sources. Source A is the original clinical trial data published by the research hospital in 2018. It includes patient records, dosage protocols, and statistical analyses. Source B is a 2023 news article that details that trial. Source A is more powerful here.
- Primary sources represent raw, uninterpreted evidence. These are original studies, lab data, court transcripts, historical letters, or eyewitness accounts. In simple words, these are the sources closest to the truth.
- Secondary sources are review articles, textbooks, news reports, or blog summaries that interpret primary sources. They are useful for context, but they introduce the author’s bias, memory lapses, or oversimplifications.
There is one strict rule for academic research – use secondary sources only as maps to find primary sources. If a 2022 review paper cites a 1995 clinical trial, do not cite the review. You should find the 1995 trial. Many original documents sit in specialized databases or physical archives not indexed by standard search engines. That’s why you may need internet research services – experts have access to different databases, check what can be accessed legally, and quickly find the original documents you need.
The Role of Peer-Reviewed Journals and Official Repositories
Not all primary sources are equal. A PDF on a personal blog may contain original data, but without editorial scrutiny it has no verified credibility. That’s why peer-reviewed journals and official repositories are so critical.
Peer review means other experts in the same field have studied the methodology, results, and conclusions before publication. This is the best-quality filter, even if retractions do happen occasionally. When you collect large amounts of data, use only trusted repositories like PubMed Central (medicine), arXiv (physics), ERIC (education), or government portals (.gov). These platforms have already done the first round of vetting.
Methodology for Publication Research at Scale
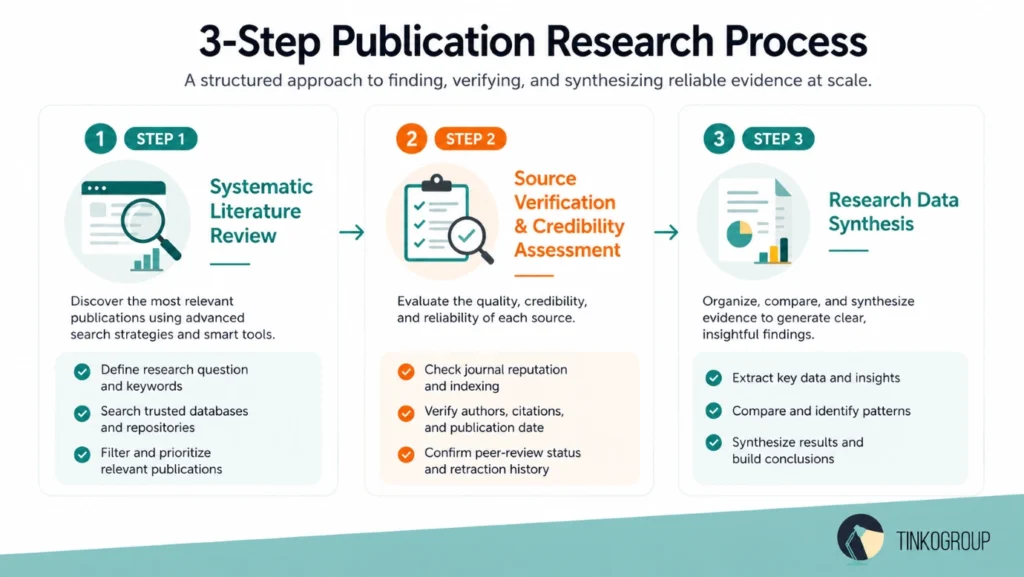
Scaling publication research without a clear process is like building a house without a plan – you may have all the materials, but nothing will fit together properly. To avoid such issues, you need a simple three-step approach that combines fast tools with careful human thinking.
Step 1: Systematic Literature Review – Automating Discovery Without Losing Focus
The Systematic Literature Review (SLR) was developed in medicine, but it has spread everywhere because it solves a core problem: how do you survey an entire body of evidence without unconsciously cherry‑picking studies that support what you already believe?
An SLR starts before you search. You write down your research question, your inclusion rules (e.g., only peer-reviewed, only 2015–2025), and your search terms. Occasionally, you may even pre-register this protocol online. Why? This way, later, no one can accuse you of changing the criteria if you find inconvenient results.
Then comes automation. Tools like Covidence, Rayyan, or even smart reference managers can ingest thousands of search results, remove duplicates, and use machine learning to suggest which papers are relevant. A systematic review that once took six months of manual screening can now take weeks.
But automation doesn’t replace human judgment. An AI screening tool with 95% accuracy sounds great until you realize that missing 5% across 5,000 records means 250 studies never reach human eyes. And one of those may contain the evidence that changes everything. Use automation to collect and narrow down a smaller set of useful papers, but always let humans make the final decision.
Step 2: Source Verification – Checking Impact Factor and Publisher Credibility
In any publication research workflow, source verification is one of the most important quality-control stages. Next, you should verify them. This sounds obvious, but it is the first step people skip under time pressure. At scale, if you don’t verify sources, you can end up using papers that were retracted or proven wrong.
Start with the Journal Impact Factor (JIF). It’s a metric that measures how frequently a journal’s articles are cited. While a JIF of 10 is generally stronger than a JIF of 1.5, this baseline varies by field (a JIF of 3 may be excellent in the humanities but mediocre in cell biology).
But the impact factor is not the whole story. High-impact journals have published retracted, flawed research (see the replication crisis in psychology). And important work in emerging fields often appears in newer, lower‑impact journals.
So your verification protocol should include three checks:
- Is the journal indexed in Scopus or Web of Science? That is a quality signal.
- Is the publisher reputable? Elsevier, Springer, Wiley, and established academic societies are safe. Predatory publishers, which charge fees without real peer review, are not. Check the DOAJ (Directory of Open Access Journals) for legitimate open-access outlets.
- Has the specific article been retracted? Search the Retraction Watch database. This is non-negotiable, especially in medicine and psychology.
Step 3: Data Synthesis – Turning Hundreds of Sources into a Cohesive Database
You have 300 verified papers. Now you need data synthesis services.
High-quality publication research depends on consistent data extraction and synthesis across all reviewed sources. No AI tool can reliably extract nuanced findings, understand methodological limits, or notice that two papers that seem to agree are actually measuring different things with incompatible instruments.
Build a structured extraction template. It will be your standard form that captures the same data from every study. For a clinical review, it will include study design, sample size, and effect sizes. For an economic review – data sources, country contexts, and findings. Then, human by human, paper by paper, you fill it out.
The process is slow, disciplined, and worth every hour. Researchers who rush the synthesis process are the ones who later discover that their meta-analysis has mixed apples and oranges. Take your time, and your future reputation will thank you.
Ethical Standards and Avoiding Bias
When you scale up publication research, even a tiny mistake can become a big problem. A small bias in one source may not matter much on its own, but if you repeat that mistake across hundreds of sources, you can seriously distort your results. Ethical standards mean more than honesty. They protect you from your own blind spots and keep your work fair and reliable.
How to Avoid Cherry-Picking in Publication Research
The most dangerous phrase in research is “I knew that already.” Confirmation bias is when people naturally search for information that supports what they already believe. It is a well-known human tendency. When research is done on a large scale, it can become a serious problem.
Imagine a situation – a company hires researchers to prove that their new software improves workplace productivity. An unethical researcher looks only for “productivity benefits of software X,” finds twelve case studies, and calls it a day. That is cherry‑picking – the fallacy of incomplete evidence.
The cure is active disconfirmation. For every search term you run, run its opposite. When you search for advantages, also look for disadvantages. Do not hide the results that hurt your argument. A credible publication acknowledges counterevidence and explains why it does not overturn the conclusion.
At scale, this means you should build a negative search protocol into your workflow. Ask your web research services team to provide a “null hypothesis” component for every query. It refers to automated scrapers or human researchers. If the service returns only supportive results, send it back and ask to explain what exactly they excluded and why.
Another practical tactic is to blind your reviewers. If possible, have one researcher extract data from sources, but don’t let them know which side of the argument the source supports. Only later does a second researcher map those findings to the thesis. This separation of duties is common in clinical trials but rare in literature reviews – which is exactly why it is so valuable.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

How to Avoid Plagiarism and Citation Errors
Plagiarism is easy to recognize because it directly copies someone else’s work. Data drift is harder to notice, but in large research projects, it can become an even bigger problem.
Data drift happens when you cite Source A for a fact, but Source A actually cited Source B, and Source B was speculation or a misinterpretation. By the time you cite it, the original meaning has “drifted” into something unrecognizable.
A classic example: a 1990s textbook claims that “humans use only 10% of their brains.” That claim first appeared as a loose metaphor in a 1907 self-help book, not a scientific study. Yet researchers who cited the textbook (which cited another book, which cited the 1907 source) perpetuated the myth for decades. That is data drift.
The rule is very simple – you should never cite a citation. Always find the original source. If the original is behind a paywall, in a dead link, or in a physical archive you cannot access, mark it as “unverifiable” and do not use it.
Research services that focus only on speed can easily spread incorrect information. If a tool simply collects the first few search results and copies their references, it can also repeat mistakes, weak sources, or inaccurate citations. That’s why good publication research still needs people to carefully check where information originally came from. It takes more time but excludes mistakes.
Tools and Technologies for Research Automation
Automation is not the enemy of good research. When researchers use it correctly, they save time on what humans do best: making judgments and analyzing complex information. But automation is still just a tool. It should support the research process, not control it. Researchers should know how to use technology wisely without depending on it completely.
AI Can Summarize, but Humans Must Verify
LLMs simplify many things for researchers and speed up scholarly data collection. Feed them a 50-page paper, and they will produce a tidy, laconic summary in seconds. They can extract key variables, list methodologies, and even format citations. This feature is excellent when you are working with hundreds of papers. This is one of the reasons why human oversight remains essential in modern publication research.
But AI hallucinates. It predicts words but does not always understand truth and can seriously misinterpret some content. If you use AI models, here’s the safe workflow:
- Use AI for exclusion, not inclusion. Let the AI discard papers that are clearly irrelevant (e.g., wrong species, wrong time, wrong language). But never let AI make the final decision.
- Use AI for extraction, not interpretation. AI can take data from tables and turn it into neat files like CSVs. But a person still needs to check that the data is correct and makes sense.
- Always fact-check the summary against the original abstract and conclusion. This takes two minutes per paper. It is the difference between confident citation and embarrassing retraction.
At scale, this hybrid workflow, where AI provides speed and humans verify everything, is the only way to accuracy.
Working with Big Bibliographies and Datasets
When your project grows beyond fifty sources, spreadsheets don’t work. You need dedicated tools. You may consider reference managers like Zotero, Mendeley, and EndNote – these are excellent for large-scale work. They store PDFs, capture metadata, and generate citations in any format. But they are not databases – they are libraries.
You need to build a system in Airtable, Notion, or a custom SQL database with separate tables for:
- Sources (author, year, DOI, tier, retraction status).
- Extracts (specific quotes, statistics, and page numbers linked to a source).
- Conflicts (notes on disagreements between sources).
For data quality assurance, you should deduplicate entries, verify DOIs resolve correctly, and run periodic checks against Retraction Watch. Automation can flag issues, but a human must review every flag. A false positive (two different papers with similar titles) is rare but costly. Follow the rule: garbage in, garbage out. Tools only work when you use them correctly. Automate the boring stuff, but keep the important stuff under human control.
Why Human Expertise is the “Gold Standard” for Publications
Automation and AI can make research much faster. But faster does not mean more trustworthy. When you are working on a journal article, a policy paper, or an academic book, human expertise is still essential. Human experts bring accuracy and authority.
Why AI research often lacks nuance and context
AI lives in a world of probabilities. It looks at billions of sentences and guesses the next most likely word. That is not the same as how humans do it.
Here is an example of how it happens. Imagine an AI reads a 2000s engineering report that says: “The bridge showed minor cracks, but based on the materials available at the time, this was considered acceptable.” The AI summarizes it as: “Cracks were acceptable.” But a human engineer notices the phrase “at the time” and further finds that those “acceptable cracks” later caused a collapse. The AI will not investigate that connection.
Or take a political science paper. A sentence says: “The policy reduced crime, according to police department records.” AI stops there. A human will have further questions about those records. That is not nitpicking. That is the difference between citing a fact and citing an illusion.
Human experts bring skepticism as a reflex. They read between the lines. They smell something fishy even when the words look clean. AI cannot do it.
The Value of Manual Data Collection
One of the biggest advantages of experienced human researchers is that they can find information that is not easy to find online. A lot of academic material is available on the internet, but it is still not complete. Many important sources are not properly digitized or indexed. Important sources exist in physical libraries or archives. Others are in languages that English search tools do not cover well.
Some information exists only in “gray literature,” like reports or papers that were never officially published. And some data is kept in private databases that you can only access by asking for permission or building connections.
B2B data collection at the research level almost always requires a combination of tools and human outreach. The automated part is faster. The human part is where the most valuable material is found.
A researcher who calls a government statistical office to ask about unpublished datasets, or who contacts the authors of a ten-year-old study to ask whether the underlying data is still available, or who visits a physical archive to photograph records that have never been digitized – that researcher is doing something no AI can currently replicate. Often, those are precisely the sources that distinguish a genuinely thorough piece of scholarship from one that merely assembles the most accessible material.
Building Custom Databases for Large-Scale Studies
After you collect studies, check sources, and put the findings together, you have hundreds of PDFs, spreadsheets, and notes full of useful insights. The research doesn’t end there. Later, you may need to quickly find a specific quote or trace a number back to its original source. If you do not build a custom database, your data slowly turns into digital dust.
Structuring Academic Data for the Long Haul
A custom database can be compared with a well‑organized toolbox. All the tools are clearly sorted and labeled. You know exactly where to reach when you need a specific size. The same logic applies to research data. A good structure has three layers.
Layer 1: the raw vault. Here you keep original PDFs, scanned documents, and downloaded HTML snapshots. You don’t edit or delete anything here. It’s your digital evidence locker. If someone challenges a claim six months from now, you can find the exact original file.
Layer 2: the metadata table. This is a spreadsheet or database table with one row per source. Columns include author, year, title, DOI, journal, impact factor tier, retraction status, and a short human‑written summary. This layer turns a pile of files into a searchable collection. You can filter by year, by methodology, or by author.
Layer 3: the extract table. Here, every important quote, statistic, or finding gets its own row, linked back to the source. This layer allows you to quickly pull evidence for any argument without re-reading hundreds of papers.
Custom Database Building in Practice
Let’s modify how it works in this situation. A client needed to track changing consumer sentiment about electric vehicles across five years of news articles, academic papers, and industry reports. They started with scattered files on three different laptops.
An expert built a custom database using Airtable. The raw vault lived in cloud storage. The metadata table tracked 1,200 sources. The extract table stored 3,500 annotated quotes with sentiment tags (positive, negative, neutral). Six months later, when the client needed to write a white paper on charging infrastructure, they did not do research. They just opened the database, filtered by “infrastructure” and “negative sentiment,” and had their evidence in five minutes.
That is the power of custom database building. It transforms a one‑time research project into a lasting asset. The next white paper, the next journal article, and the next book chapter – all of them start from a place of ready‑to‑use evidence, not from scratch.
Conclusion
We have covered a lot of ground, from systematic literature reviews and source verification to ethical bias prevention and custom database structures. Successful publication research requires a balance between automation, verification, and expert judgment. But if you take away only one thing, let it be this: scaling research is not about working faster. It is about working with discipline and the right methodology.
Researchers who succeed at scale are not the ones with the most expensive AI subscriptions. They only knew when to automate, when to verify, and when to bring in human expertise. They build hierarchies of evidence. They check every source. They document every decision. And they never, ever trust a single citation without tracing it back to its origin.
We also know that doing all of these tasks alone is hard. That is why Tinkogroup exists. We provide structured, verified, and audit-ready data for high-authority publications and academic projects. Our Internet research services combine deep-dive searching with 100% manual verification – a human analyst checks every piece of information before it reaches you. We deliver clean, organized data in your preferred format (CSV, JSON, or CRM-ready), complete with source transparency so you can validate every claim yourself.
Ready to Scale Your Research? Talk to our team about your next project. Let’s have an honest conversation about how we can save you weeks of manual searching and help you build faster, more organized, and more reliable research processes at scale.
What is publication research, and how is it different from a standard online search?
Publication research is a structured process of collecting, verifying, and synthesizing information from credible sources such as peer-reviewed journals, official repositories, government datasets, and original studies. Unlike a standard online search, publication research requires source validation, evidence hierarchy assessment, and documented methodologies to ensure accuracy and reliability.
How can researchers verify whether a source is trustworthy?
A reliable publication research workflow includes several verification steps. Researchers should confirm that a source comes from a reputable publisher, check whether the journal is indexed in recognized databases such as Scopus or Web of Science, review citation metrics when relevant, and verify that the article has not been retracted. Primary sources and peer-reviewed publications generally provide the strongest evidence.
Can AI replace human researchers in publication research?
No. AI can speed up publication research by helping find sources, summarize papers, and organize information, but it cannot reliably evaluate context, identify subtle methodological flaws, or verify the accuracy of complex claims. The most effective approach combines AI-powered automation with human expertise and manual source verification.


