

Line annotation has become the backbone of modern computer vision — long before the industry moved beyond simple classification. In the early 2010s, the industry celebrated when a convolutional neural network (CNN) could distinguish a pedestrian from a lamppost. Today, that level of understanding is rudimentary. The modern requirement for machine perception is not just “what” an object is but “where” it exists within a complex, three-dimensional topological map.
That’s why the industry’s focus shifted to line annotation. Experts often describe line-based data as the “unsung hero” of the artificial intelligence revolution, as it provides the structural scaffolding for world-building in digital environments. While bounding boxes offer a coarse approximation of an object’s location, they fail to capture the nuance of boundaries, paths, and constraints.
Modern ML development has a clear thesis: accuracy thresholds define market position. The gap between a dangerous 90% model and a market-leading 99.9% one comes down to polyline annotation precision. For CTOs and Heads of Data, understanding the granular mechanics of this process is no longer optional. It is the primary lever for achieving safety and efficiency in autonomous driving datasets.
Deep Dive: The Technical Anatomy of Line Annotation
To understand the superiority of line annotation computer vision, one must examine the mathematical and geometric foundations that distinguish it from traditional labeling methods.
Technical Definition: Polylines vs. Splines vs. Keypoints
At its core, labeling lines involves the projection of human spatial intuition into machine-readable coordinates.
Annotation support
- Polylines: These consist of a series of connected (x, y) vertices. They are computationally efficient but require a high density of points to simulate smooth curves.
- Splines: These utilize mathematical functions (like B-splines) to create continuous paths. For high-speed lane detection, splines are superior because they more accurately reflect the physics of road engineering and vehicle steering geometry.
- Keypoints: These represent singular nodes of interest — such as the exact termination point of a guardrail. While not lines themselves, they serve as anchors for complex annotation line workflows.
The Mathematical Aspect: Vectors and Coordinate Systems
When a technician performs lane line annotation, they are essentially creating a vector map. Each vertex is a data point in a coordinate system that the AI model uses to calculate the trajectory. If annotators place vertices inconsistently, the resulting ”wobble” creates noise in the model’s loss function. High-quality ground truth data must maintain a consistent “vertex-per-meter” ratio to ensure the neural network perceives a smooth path rather than a jagged series of segments.
Comparison with Other Annotation Types
Traditional Bounding Boxes are insufficient for path planning because they include “background noise” — pixels that don’t belong to the line. Semantic Segmentation, while precise, is computationally expensive. Line annotation services provide the most efficient ratio of data density to computational overhead, allowing for real-time inference in edge devices. This efficiency is why lines remain the gold standard for boundary recognition.

Industry-Specific Applications
The demand for precision data annotation is expanding across diverse sectors, each with unique environmental constraints.

Autonomous Vehicles (AV)
In the AV sector, the primary challenge is the “long tail” of edge cases. Autonomous driving datasets must account for diverse road textures, from pristine asphalt to faded, peeling paint. Systems like Lane Departure Warning rely on lane line annotation to maintain vehicle centering. An error of just a few centimeters can lead to dangerous “ping-ponging” behavior within the lane.
Smart Cities and Infrastructure
Beyond the road, boundary recognition is critical for last-mile delivery robots. These machines operate on sidewalks without painted lines, where the transition from concrete to grass defines the boundaries. Engineers require specialized image annotation services to define these “soft” boundaries, ensuring robots do not obstruct pedestrians.
Agriculture 4.0: The Precision Farming Revolution
Autonomous tractors follow crop rows labeled through specialized line annotation computer vision. This is not merely a convenience; it is a necessity for precision spraying and harvesting. If the polyline annotation is inaccurate, the tractor may crush the very crops it is meant to protect. High-quality machine learning datasets in this sector can increase yield by up to 15% by reducing plant damage.
Industrial Automation and Warehouse Safety
In modern warehouses, Automated Guided Vehicles (AGVs) must operate in perfect synchronization. Line annotation services map out permanent safety zones on warehouse floors. These annotated datasets allow ceiling-mounted cameras to detect if a pallet has crossed a safety line, immediately halting machinery to prevent injury.
The Technical “Golden Rules” of Polyline Creation
In the world of high-stakes AI, a line is never “just a line.” It is a mathematical constraint that dictates the behavior of a multi-ton vehicle or a precision industrial robot. To build reliable computer vision training data, engineers must enforce a set of “Golden Rules” that bridge the gap between human visual perception and machine-readable vectors.
Rule 1: Directionality and the Vector Field Logic
In early line annotation computer vision projects, many teams made the mistake of treating lines as static shapes. However, for a machine learning model, a line represents a path.
- The Problem of Divergence: If Labeler A draws a lane boundary from bottom-to-top, and Labeler B draws the adjacent lane from top-to-bottom, the model’s weight updates become conflicted. The neural network struggles to learn a consistent “flow,” leading to jittery path planning.
- The Standard: All lane line annotations must follow the “Direction of Travel” (DoT) protocol. In a highway scenario, every annotation line must follow the direction that a vehicle moves.
- Mathematical Importance: By enforcing directionality, we are essentially building a Vector Field. This allows the model to predict the “next state” of the road more efficiently, as the sequence of points inherently encodes the forward momentum of the environment.
Rule 2: The “Inflection Point” Strategy and Vertex Optimization
One of the most common failures in polyline annotation is the “Over-fitting vs. Under-fitting” of vertices.
- Under-fitting (The Jagged Path): Placing too few points on a curved road turns a smooth turn into a series of harsh, angular segments. If the model follows this data, the autonomous vehicle will experience “steering oscillation.”
- Over-fitting (Data Noise): Placing a vertex on every single pixel is equally dangerous. It creates “handshake noise” where the line looks jagged at a microscopic level. This increases the computational load of the machine learning datasets without adding useful information.
- The Inflection Solution: Professional line annotation services use the “Inflection Point” strategy. Annotators place a vertex at the exact moment the radius of a curve changes. On a constant-radius curve, points are spaced evenly. As the curve sharpens, the density of points increases logarithmically. This ensures the line is as light as possible for the processor but as smooth as possible for the steering controller.
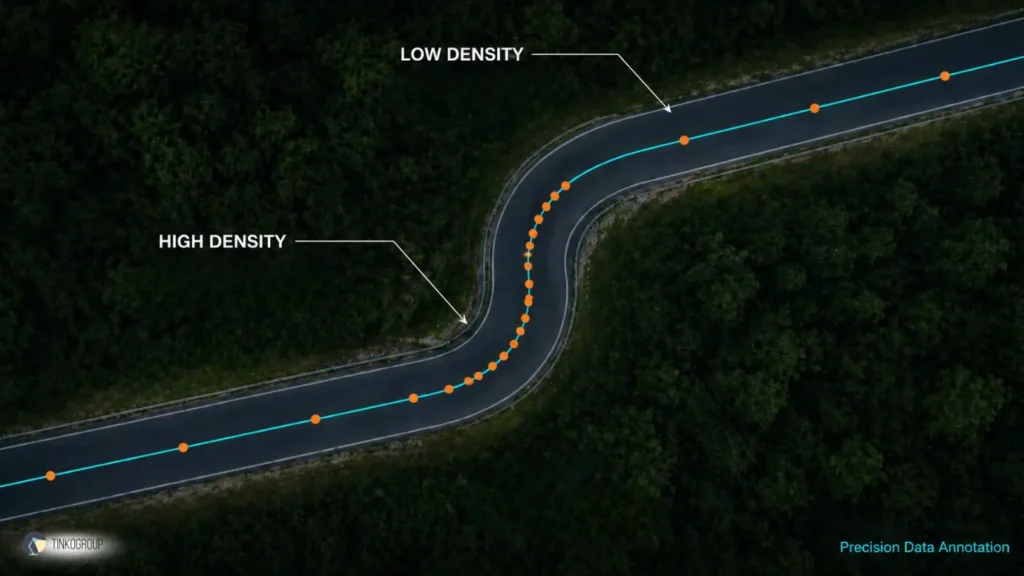
Rule 3: Handling Occlusion and the “Logic of Extrapolation”
In the real world, lines disappear. They are covered by puddles, obscured by passing trucks, or faded by decades of sun exposure.
- The Human-in-the-Loop Advantage: This is where automated image annotation services fail. An AI sees a gap and stops the line. A human expert, however, understands the Gestalt principles of continuity.
- Extrapolation Rules: When a line is occluded, the labeler must continue the annotation line through the obstacle. The industry calls this ”Virtual Labeling.”
- Linear Extrapolation: If the road is straight, the line continues in a direct vector.
- Contextual Extrapolation: If the road is curving, the labeler must follow the arc established before the occlusion.
- Why it matters: This teaches the AI “Object Permanence.” It ensures that if a car’s camera is momentarily blinded by a splash of mud, the system doesn’t “forget” that the lane boundary exists. This is the cornerstone of precision data annotation.
Rule 4: Critical Attribute Tagging (The Metadata Layer)
A line without attributes is a “dumb” line. To reach 99% AI model accuracy, the model must know the meaning of the boundary.
- Semantic Layering: Every polyline annotation must carry a classification tag.
- Dashed vs. Solid: This defines “Legal vs. Illegal” maneuvers. A dashed line allows for lane changes; a solid line is a hard constraint.
- Double Lines: In autonomous driving datasets, a double-solid line is a high-priority “No-Cross” zone.
- Materiality: Is it a painted line, a physical curb, or a guardrail? This helps the model understand the physical consequences of a collision (e.g., hitting a curb vs. crossing a painted line).
- Color Sensitivity: We must distinguish between white, yellow, and blue. Blue lines often indicate handicap zones or EV charging lanes, requiring the vehicle to change its parking logic.
Data Quality Challenges & Edge Cases
The true test of line annotation computer vision does not happen in a lab; it happens in the chaos of a highway during a November sleet storm or at a five-way roundabout with fading paint. These “edge cases” are where standard algorithms fail and where precision data annotation becomes a strategic asset.
Adverse Weather: Annotating Through the Veil
Weather is the primary disruptor of autonomous driving datasets. When the environment becomes hostile, the visual fidelity of the annotation line degrades, forcing labelers to transition from simple tracing to complex contextual reasoning.
- Rain and Wet Asphalt: Rain creates two distinct problems: occlusion from droplets and false positives from reflections. Wet roads act like mirrors, reflecting overhead lights or adjacent car headlights, which the AI might mistake for a lane line annotation. Expert labelers must distinguish between the “specular highlight” of a puddle and the “diffuse reflectance” of actual road paint.
- Snow and Accumulation: Snow is the ultimate “occlusion” event. It can completely hide the ground truth data. In these scenarios, data annotation for AI relies on “landmark referencing.” If the line is invisible, labelers look for the guardrail, the curb, or the tracks of the vehicle ahead to interpolate the most likely position of the boundary.
- Lens Flare and Overexposure: High-angle sunlight or direct high beams can cause “sensor blooming,” where large sections of the image become pure white. Annotators must use previous frames (temporal context) to maintain the continuity of the polyline annotation through the “blind spot.”

Complex Intersections: The Architectural Nightmare
Urban environments rarely follow straight lines. They are a mess of overlapping geometries that require sophisticated line annotation services to decipher.
- Roundabouts: Roundabouts are geometric puzzles for AI systems. A roundabout involves constant curvature changes and intersecting exit paths. Labelers must use a higher density of vertices to capture the tight radius of the inner curb while simultaneously labeling lines for the tangential exit lanes.
- Multi-Lane Highways and Merges: At high speeds, the “merging zone” is where models often fail. Annotators must clearly mark where a dashed line terminates and becomes a solid “gore” area. Failure to do so leads to “lane indecision” in the model, where the car oscillates between two merging paths.
- Ghost Markings (Legacy Paint): Construction zones and old cities often shift road markings without fully erasing them. These “ghost lines” have similar reflective properties to active lines. Human-in-the-loop image annotation services are essential here; a human can see the texture difference between “ground-off” paint and “fresh” thermoplastic, whereas a machine might see two equally valid paths.
Low-Light Conditions: The Infrared vs. RGB Battle
At night, the physics of light changes, and so does the strategy for creating annotated datasets.
- RGB Limitations: In standard color (RGB) images, nighttime data is often “noisy” or underexposed. The lane line annotation becomes a series of disconnected fragments visible only in the car’s headlight cone.
- Infrared (IR) and Thermal Data: Many machine learning datasets now include IR or Thermal channels. IR can see through fog and detect the heat signature of road materials. However, IR data often lacks the contrast of RGB.
- The Fusion Challenge: The gold standard for computer vision training data is Sensor Fusion Annotation. Labelers look at the RGB and IR frames side-by-side. If the RGB is too dark, they use the IR to find the “heat contrast” of the lane marker and then project that line back into the RGB coordinate system. This ensures the model learns to navigate safely even when the human eye (and standard camera) would be blind.
Building a Scalable QA Pipeline
The creation of a scalable quality assurance pipeline for line annotation represents the most significant operational hurdle for any machine learning department. While many organizations attempt to rely on automated scripts to validate their annotated datasets, these programmatic checks frequently fail due to the subtle geometric nuances inherent in path-based data.
The primary reason automated QA falls short is a phenomenon known as the “Wobble” effect. Automated scripts are excellent at identifying missing labels or incorrect classifications, but they lack the visual sensitivity to detect microscopic oscillations in a polyline. A script might confirm that an annotation line exists between two points, but it cannot easily discern if the labeler’s hand-eye coordination faltered, creating a jagged, “sawtooth” pattern that deviates from the actual road curvature by only a few pixels.
A neural network views these tiny wobbles as more than aesthetic flaws; it interprets them as high-frequency noise in the ground truth data. Training a model on ‘wobbly’ lines often creates an unstable steering policy, leading to a vehicle that oscillates within its lane because it literally tries to follow the jagged path contained in its machine learning datasets.
To mitigate these risks, a sophisticated data annotation for AI pipelines must employ a rigorous, multi-stage human review architecture. This process begins with the initial labeler, who is responsible for the primary drafting of the polyline annotation. However, even the most skilled labeler is prone to fatigue or misinterpretation in complex scenes.
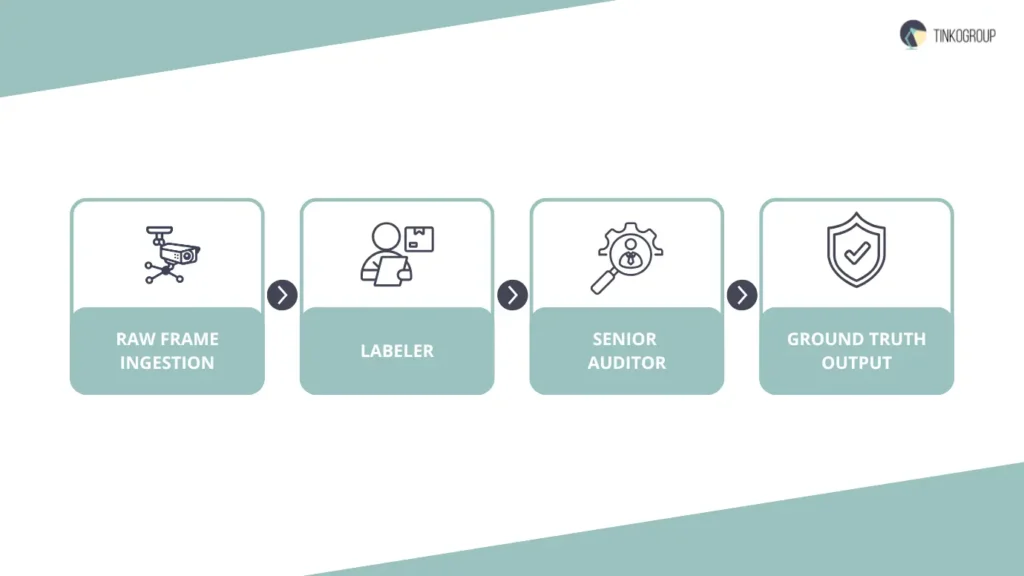
Therefore, the data immediately pass to a senior labeler. This individual does not merely “check” the work but actively refines the vertex placement, ensuring that every point sits exactly at the center of the visible road marking and adheres to the “Inflection Point” strategy discussed earlier. The Senior Labeler also audits the attribute tagging, verifying that a dashed line has not been incorrectly labeled as solid.
The final layer of defense is the QA Specialist, who operates as an impartial auditor. This specialist uses specialized magnification tools to inspect the lane line annotation at a sub-pixel level. Their role is to ensure absolute consistency across thousands of frames, preventing the “temporal drift” where a line might appear to jump or jitter when the video is played back at full speed.
The success of this labor-intensive pipeline team measures success through traditional and specialized metrics. The most fundamental metric is pixel-perfect accuracy, which calculates the Euclidean distance between the annotated line and the center of the physical road marking. In high-precision line annotation computer vision, the acceptable margin of error is often less than two pixels at a standard 1080p resolution.
Beyond simple pixel distance, the industry relies on Mean Average Precision (mAP) to evaluate the model’s ability to correctly identify and localize every annotation line in a frame. However, for line-specific tasks, mAP is often supplemented by “Curvature Deviation” metrics, which penalize any annotation that does not mathematically match the physical arc of the road.
By achieving high scores across these metrics, line annotation services like those provided by Tinkogroup ensure that the resulting computer vision training data is not just a collection of coordinates, but a mathematically sound blueprint for safe autonomous navigation. This multi-layered approach to precision data annotation is what ultimately enables a model to transcend the 90% accuracy plateau and reach the level of reliability required for public road deployment.
Why Outsource to Tinkogroup?
In today’s ML market, the bottleneck is rarely the algorithm itself. Most modern neural network architectures are open-source or well-understood. What separates the leaders is the data pipeline. For a CTO or Head of Data, the decision to build an internal labeling department versus partnering with specialized line annotation services like Tinkogroup is a strategic crossroads.
Managing an in-house team requires massive investments in HR, specialized software development, and quality control management, which often distracts from the core mission of model development. Tinkogroup offers a plug-and-play solution that transforms raw data into high-fidelity computer vision training data with industrial-grade reliability.
Operational Efficiency and the “Time-to-Market” Advantage
In the AI race, time is everything. A delay of three months in your data pipeline can mean the difference between being a first mover or a late entrant in the autonomous vehicle market. Tinkogroup accelerates this timeline by deploying pre-trained, specialized teams that understand the nuances of lane line annotation from day one.
Unlike generalist crowdsourcing platforms, where quality is erratic, Tinkogroup’s workflow is optimized for speed without sacrificing precision. By utilizing proprietary pre-labeling algorithms, the team can automate the “easy” 80% of a dataset, allowing human experts to focus exclusively on the complex 20% that actually drives AI model accuracy. This hybrid approach significantly reduces the “Lead Time” from raw sensor ingestion to the delivery of ready-to-train annotated datasets.
Furthermore, our infrastructure handles massive horizontal scaling; whether a project requires 10,000 or 10,000,000 frames, the turnaround time remains predictable, allowing product owners to meet their quarterly deployment milestones with confidence.
The Strategic “Human-in-the-loop” Advantage for AI
While fully automated labeling is a common industry dream, the reality of data annotation for AI is that machines cannot yet grade their own homework. This is where Tinkogroup’s “Human-in-the-loop” (HITL) philosophy becomes a critical safety net. In scenarios involving boundary recognition, an AI might struggle with a line that is partially obscured by a shadow or a splash of mud. A human expert, however, uses everyday driving experience and spatial awareness to naturally fill in the missing line.
Tinkogroup’s HITL model injects human judgment at the most critical points of the pipeline. Our experts act as the “Ground Truth” validators, correcting the “hallucinations” of automated tools. This is particularly vital in line annotation computer vision, where a single misplaced vertex in a training frame can lead to a “steering bias” in the final model.
By keeping humans in the loop, we provide a layer of semantic understanding — distinguishing between a permanent road boundary and temporary construction tape — that current automated systems simply cannot replicate. This results in machine learning datasets that are more robust, ethical, and safer for real-world deployment.
Technical Case Study: Achieving 1% Error Rates Through Expert Intervention
To illustrate the impact of expert-led precision data annotation, consider a recent project involving a high-speed highway lane detection system. The client initially utilized a low-cost, automated labeling service that promised rapid results. However, upon testing, the model exhibited a 15% error rate in “Complex Merging Zones” and “Low-Light Tunnels.” The automated lines were jittery, often ‘jumping’ between the actual lane marker and its shadow on the pavement.
Tinkogroup stepped in to perform a comprehensive “Data Rescue” operation. Our specialists implemented a three-tier polyline annotation review process, focusing on temporal consistency across video frames. We corrected the “Wobble” effect by applying strict inflection point rules and used infrared data to verify boundaries in the dark tunnel segments.
By replacing the noisy, automated labels with expert-verified ground truth data, the client’s AI model accuracy saw a dramatic shift. The error rate dropped from 15% to less than 1%, and the model’s confidence score in edge cases improved by 40%. This transition from “cheap” data to “expert” data allowed the client to pass their safety audits months ahead of schedule, proving that high-quality image annotation services are an investment that pays for itself in reduced R&D cycles.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Conclusion & Future Outlook
Artificial intelligence is shifting from “architectural discovery” to “data refinement.” After a decade of building massive neural networks, developers now realize that even the most sophisticated models rely entirely on the annotated datasets that train them. As we enter the next decade of line annotation computer vision, the industry will prioritize the structural integrity and semantic depth of every single annotation line over sheer data quantity.
The Future of Annotation: The Rise of Hybrid AI-Assisted Labeling
The next frontier in data annotation for AI is not the total replacement of humans by machines, but the perfection of the “Centaur” model — the seamless integration of human intuition with algorithmic speed. The industry calls this Hybrid AI-Assisted Labeling. In this upcoming paradigm, a pre-trained model will perform the “heavy lifting,” generating a first-pass polyline annotation with approximately 85-90% accuracy.
However, the “Final Mile” of data quality will remain a human domain. As road environments become more complex — with the rise of smart infrastructure and V2X (Vehicle-to-Everything) communication — the context required for precision data annotation will exceed what a pure algorithm can understand.
Hybrid systems will allow human experts to act as “Supervisors,” focusing their energy on the most difficult 10% of frames: the blinding lens flares, the confusing construction zones, and the “ghost markings” of ancient city streets. This evolution will allow line annotation services to scale to the petabyte level while maintaining a ground truth data standard that automated tools simply cannot reach alone.
Final Thought: High-Quality Data is an Investment, Not an Expense
This analysis repeatedly highlights the hidden cost of “cheap” data. While CTOs often view image annotation services as a cheap commodity, the technical reality of AI model accuracy tells a different story. Inaccurate lane line annotation creates “Technical Debt” that engineering teams must eventually pay. This debt manifests as failed safety tests, jittery vehicle behavior, and months of wasted engineering time debugging a model that learned the wrong “truth.”
High-quality machine learning datasets represent a capital investment. Get boundary recognition right from day one, and an organization is effectively building a “Safety Moat” around its technology. This precision accelerates the transition from R&D to commercial deployment, reducing the total “Cost per Mile” of autonomous system development. In the world of autonomous driving datasets, there is no substitute for the truth.
Elevate Your Model with Tinkogroup
Precision paves the journey toward 99.9% model reliability. Tinkogroup stands at the intersection of human expertise and technical innovation, providing the line annotation services that power the next generation of autonomous machines. Our specialized teams do not just draw lines; they build the mathematical foundations of the future.
Whether you are developing long-haul trucking solutions, urban delivery robots, or precision agriculture platforms, your success depends on the quality of your computer vision training data. Do not leave your model’s accuracy to chance or to unverified automated tools. Partner with a team that understands the weight of every vertex.
Ready to see the difference that expert intervention can make? Contact Tinkogroup today for a pilot project and take the first step toward achieving industrial-grade AI model accuracy. Let us handle the complexity of the pixels so you can focus on the future of your product.
What is the difference between line annotation and bounding box annotation?
Line annotation focuses on mapping precise paths, edges, and boundaries using connected vectors or splines, while bounding boxes only approximate object locations with rectangular shapes. In autonomous driving and robotics, line annotation provides significantly higher spatial accuracy for lane detection, path planning, and boundary recognition.
Why is human review still necessary in AI-assisted line annotation?
Automated systems can accelerate annotation workflows, but they still struggle with edge cases such as faded lane markings, rain reflections, snow coverage, or complex intersections. Human reviewers ensure contextual consistency, correct vertex placement, and accurate extrapolation when boundaries become partially invisible.
Which industries benefit the most from line annotation services?
Line annotation is widely used in autonomous vehicles, smart city infrastructure, warehouse automation, agriculture, and delivery robotics. These industries rely on high-precision computer vision training data to improve navigation accuracy, operational safety, and real-time decision-making.


