

The real bottleneck in modern enterprise AI development is no longer cloud compute or neural network architecture. Without reliable annotation performance metrics, data preparation teams encounter significant obstacles long before a model reaches training. Effective annotation performance metrics provide the visibility needed to balance quality, consistency, and delivery speed. The real friction point starts much earlier — inside the data operations layer, long before model training begins, where machine learning models need more detailed, context-rich training data to work reliably in the real world.
Machine learning operations engineers and data managers face a continuous crisis. They must figure out how to evaluate and benchmark individual annotator performance with clinical precision, yet they cannot afford to build slow, bloated quality assurance checkpoints that paralyze dataset delivery timelines. When corporate AI training data quality schedules run on millions of dollars of hardware, a delay in data delivery cascades into immediate financial loss.
Historically, production teams managed this problem through an oversimplified, binary worldview. They treated data accuracy and pipeline throughput as two fundamentally opposing forces that could never coexist. The common belief was that an organization had to slow down its pipeline to a crawl and check every single asset by hand to get clean, production-ready labels.
On the other hand, meeting a tight deadline for deploying a model or launching a product meant using datasets that were full of human error and noise. This outdated tradeoff no longer works in modern AI development. Fast-moving AI teams cannot afford to keep senior engineers waiting on a slow data queue.
When an enterprise relies on weak or legacy benchmarking frameworks, the damage reaches far beyond the data team. Inconsistent datasets introduce silent corruption into model training, leading to erratic inference behavior that escapes early validation checks but fails in production. A lack of clear performance annotation quality metrics also causes severe reviewer overload.
Senior domain experts end up spending their valuable hours fixing basic, routine labels instead of addressing complex edge cases that actually dictate model edge performance. This unexpectedly drives up cloud compute costs, forcing engineering teams into unplanned, expensive retraining cycles to fix bugs caused by poor data foundations. Finally, these issues push back product launch dates, making the data team a bottleneck rather than a growth driver.
To break this cycle, mature AI organizations utilize an objective, infrastructure-wide scoring system built around annotation performance metrics. This operational framework evaluates labeling quality, systemic data labeling consistency, reviewer alignment, and team productivity across every pipeline stage. It turns reactive, ad-hoc checking into a predictable, numbers-driven process. Well-designed annotation performance metrics create a common operational language that aligns annotators, reviewers, and project stakeholders.
The core thesis of modern data operations is straightforward: sustainable annotator benchmarking does not require sacrificing delivery speed. Instead, it relies on an integrated architecture that balances real-time quality tracking, rigorous reviewer calibration, and dynamic pipeline velocity. By eliminating manual friction points and establishing clear statistical baselines, enterprise AI teams can continuously optimize both data fidelity and shipping speed.
Why Measuring Annotator Performance Is More Complex Than It Looks
Assessing high-throughput data labeling workers differs from auditing back-office data entry. Standard data entry uses explicit, binary rules with right and wrong answers. In contrast, data annotation requires managing human subjectivity, language nuance, and changing contextual patterns. Due to this volatility, using production speed to assess human workforce quality in an enterprise machine learning pipeline is risky. Volume alone cannot determine dataset quality because production operations face complex structural challenges. This is why modern annotation performance metrics must evaluate both productivity and labeling accuracy.
When high-resolution computer vision frames show ambiguous visual data, subjective edge cases disrupt automated evaluation models. An annotator may struggle to identify a dark, pixelated cluster in a night driving frame as a road shadow or a pothole. Task complexity varies greatly within the same dataset. Annotators may tag fifty simple, isolated bounding boxes in two minutes but spend forty minutes tracking a single occluded object across a complex 3D LiDAR point cloud.
Automated keyword tools miss local regional dialects, shifting slang, and evolving social intent in multilingual datasets used for content moderation and natural language processing. Senior data auditors often disagree on the same complex text or image block, worsening the issue. In medical imaging, financial compliance data, and legal document analysis, domain-specific labeling requires deep industry knowledge, not general intelligence.
These variables make tracking simple labels per hour a flawed and ineffective operational benchmark. When a data team only focuses on raw speed, weekly production reports look great, but training data quietly deteriorates. A large-scale autonomous vehicle project has a real-world scenario that it must handle. Fast worker Annotator A clears 160 video frames per hour. They meet speed goals by quickly drawing bounding boxes around visible objects.
However, they consistently miss small, partially hidden vehicles and cut off the side mirrors on parked cars. Annotator B is a methodical, slower worker who processes only 55 frames per hour. They take the time to zoom in, verify obscured pixels, and map every vehicle boundary perfectly.
If data operations managers rely solely on traditional speed metrics, Annotator A receives bonuses and performance praise, while Annotator B is flagged for low annotator productivity and faces remediation. Weeks later, the engineering team discovers that Annotator A’s sloppy output has choked the validation pipeline with broken data, forcing the QA squad to waste days redoing the work.
This classic operational trap proves why comprehensive annotation performance metrics must track precision alongside raw volume to be effective. Quality assurance teams constantly struggle to balance throughput and accuracy when their management tools lack the sophistication to differentiate between a fast, sloppy worker and a precise, specialized domain expert.

Benchmarking Annotation Quality: Which Metrics Actually Matter
To break free from misleading speed metrics, enterprise data operations leaders build multi-dimensional annotation performance metrics frameworks. These frameworks look beyond simple task counts to measure the mathematical consistency of the data. By tracking specific, actionable indicators, engineering teams can spot pipeline defects before they corrupt model training cycles.
A robust annotation benchmarking architecture uses six main operational metrics: inter-annotator agreement, reviewer overlap rate, QA pass rates, escalation frequency, annotation throughput, and consistency scoring.

Inter-annotator agreement uses statistical formulas like Cohen’s Kappa, Fleiss’ Kappa, or intersection over union to measure how consistently different labelers tag the same data points. High agreement values confirm that your instructions are clear and interpreted the same way across the team.
The reviewer overlap rate measures how often different senior quality checkers audit the same batch of completed work, providing an internal check on auditor alignment. QA pass rates track the raw percentage of an individual annotator’s tasks that clear internal quality evaluations on the first attempt without requiring rework.
Escalation frequency monitors how often an annotator flags an asset because the documentation or edge-case guidelines are too ambiguous to make a clear decision. Annotation throughput measures how many verified, accepted labels an annotator delivers per unit of time, weighted against the documented difficulty tier of the specific task. Finally, consistency scoring monitors an annotator’s accuracy and stability across an eight-hour shift, identifying performance drops caused by fatigue or distraction.
Every metric provides specific operational value, but each also has distinct structural limitations that require careful management. Inter-annotator agreement is the most reliable way to uncover hidden bias and vague instructions, but running multiple people on identical tasks increases overall data ingestion costs. Together, these annotation performance metrics provide a balanced view of workforce quality and operational efficiency.
QA pass rates offer an excellent view of individual worker improvement over time, but their main weakness is that they fail if the reviewer scoring the work is careless or poorly trained. Annotation throughput remains vital for predicting final project delivery dates, but when used in isolation, it encourages the workforce to overlook complex details.
High production throughput numbers can easily hide a low-quality dataset if your internal reviewer team is out of sync. When quality checkers do not follow calibrated standards, they approve flawed batches. This creates false confidence within project leadership, who see high volume and assume the pipeline is healthy.
Poorly designed metrics ultimately cause hidden annotation drift, where the workforce’s understanding of the labeling rules changes over the course of a multi-month project. Without tight, metrics-driven control, this drift introduces noise into the dataset, undermining the entire value of your benchmarking annotation quality initiatives and leading to severe reviewer inconsistency.
How Poor QA Systems Slow Down Dataset Delivery
When enterprise data operations encounter systemic quality issues, the instinctive corporate reflex is almost always to erect more defensive barriers. Management teams routinely respond by demanding comprehensive, multi-layered audits, mandating that every single annotated asset undergo a full manual secondary review. While this total verification approach sounds reassuring in executive alignment meetings, it represents a profound operational failure.
Overly dense, rigid quality assurance scalable data annotation workflows do not fix root-cause human errors; they merely hide them behind a massive operational wall. Often, poorly designed annotation performance metrics are the underlying cause of excessive review workloads. Instead of improving the dataset, uncalibrated review processes turn the quality assurance wing into a permanent project bottleneck that cripples delivery velocity and inflates engineering costs.
The structural inefficiencies of an over-engineered review framework show up across the entire data production line. First, indiscriminate auditing processes lead directly to severe reviewer bottlenecks, where small groups of senior specialists face thousands of pending tasks.
Second, when the original annotation instructions are vague, reviewers often spend their shifts completely redoing the work instead of checking it, creating massive duplicated effort.
Third, these operational delays cause missed product release cycles, keeping machine learning researchers waiting for essential training data. Finally, the financial overhead of maintaining an oversized, uncalibrated review team drains project budgets without delivering a measurable lift in final model performance.
These systemic failures are caused by a number of common operational problems that affect old data pipelines. The most frequent error is over-reviewing low-risk tasks, such as treating basic text categorization with the same intensity as complex medical pixel segmentation. Furthermore, relying on static QA sampling like checking exactly 10 percent of every batch regardless of an annotator’s past performance wastes critical reviewer hours on highly accurate workers while missing errors from struggling ones.
This inefficiency worsens when organizations operate with unclear escalation ownership, leaving reviewers to guess who makes the final call on highly ambiguous edge cases. When you combine this structural confusion with inconsistent reviewer decisions, the workforce receives conflicting feedback, causing frustration and a sharp drop in dataset reliability.
In practice, adding more QA steps rarely resolves the root problem. In fact, it often achieves the opposite. When a small team of reviewers must manually verify millions of routine labels, they quickly experience cognitive fatigue. Tired auditors begin glazing over obvious mistakes, approving flawed data just to clear their daily queues. This surge in manual oversight significantly reduces the throughput of the annotation QA workflow while providing a false sense of security to engineering leads.
To prevent these bottlenecks, mature enterprise operations replace rigid, linear audit paths with agile, risk-adjusted validation frameworks. These smarter workflows use dynamic sampling strategies, where the system tracks real-time accuracy trends and automatically reduces review rates to five percent for proven experts while increasing them to one hundred percent for new trainees.
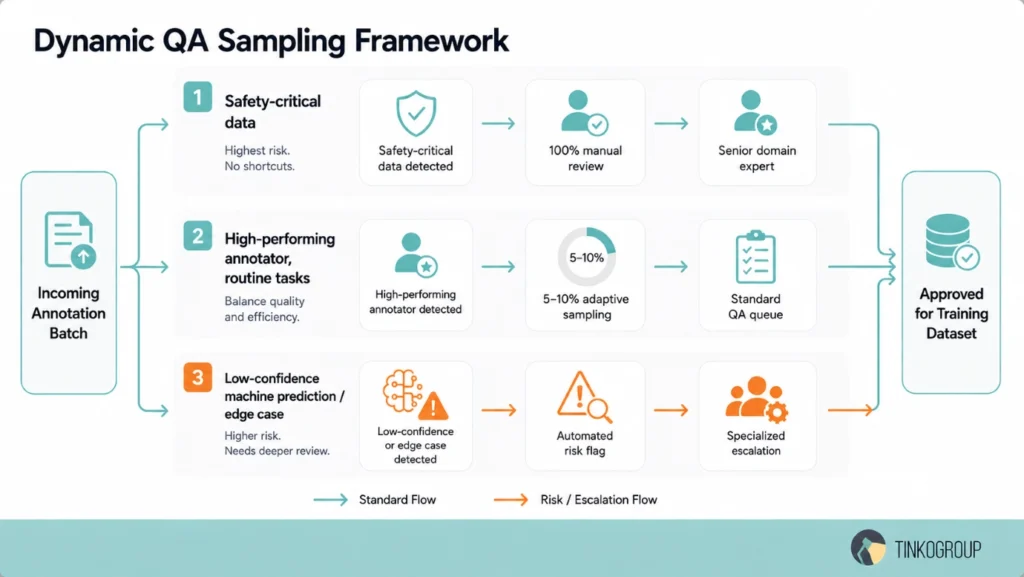
Risk-based QA validation automatically flags highly complex assets, such as low-contrast camera frames or dense text strings, for mandatory auditing while allowing routine, high-confidence labels to bypass the review queue entirely. Selective escalation workflows route highly ambiguous edge cases straight to specialized domain experts, preventing day-to-day work queues from stalling.
Additionally, benchmark-triggered reviews automatically quarantine an annotator’s entire daily batch the moment their individual accuracy score dips below a set statistical threshold.
A sophisticated data operation balances speed, scalability, reviewer workload, and dataset quality without creating unnecessary delivery friction. For example, full manual verification remains essential when handling safety-critical data, such as training autonomous vehicles to spot pedestrians in heavy rain or calibrating medical diagnostic tools.
However, adaptive QA sampling is far more efficient for routine work, such as classifying thousands of e-commerce product images. By deploying a numbers-driven benchmarking framework, operations leaders can precisely focus their reviewers’ limited attention where it matters most, keeping dataset delivery predictable, cost-effective, and fast.
| QA Strategy | Operational Trigger | Workflow Routing | Downstream Impact |
| Full Manual Review | Safety-critical data (Medical, Autonomous Vehicles) | 100% of tasks routed to senior domain expert | Maximum precision, slower turnaround times |
| Adaptive Sampling | High performance baseline on routine tasks | 5-10% random audits based on worker history | Maintained quality, maximized throughput speed |
| Risk-Based Validation | Machine learning prediction low-confidence scores | Automated routing of complex or edge-case frames | Targeted use of manual QA budget where needed |
Benchmarking Annotators in AI-Assisted Annotation Pipelines
The widespread use of large language models and advanced foundational architectures has transformed data labeling. An employee rarely has to create each tag from scratch on a blank digital canvas in modern enterprise workflows. Production teams use advanced AI-assisted annotation environments. These hybrid systems use auto-labeling, model-assisted pre-annotation, and LLM-assisted review workflows to automate the initial classification.
In practice, data teams often integrate these automated capabilities into established platforms. For instance, teams utilize Label Studio AI-assisted workflows or Scale AI auto-labeling to pre-tag millions of records before a human ever sees them.
Human annotators no longer act as raw creators; instead, they function as editors, auditors, and adjusters who refine machine-generated outputs. While this approach dramatically accelerates raw production velocity, it introduces complex challenges for tracking individual annotator capabilities and performance. As automation adoption grows, annotation performance metrics become even more important for identifying human oversight gaps and automation bias.
The primary issue is that automation frequently distorts traditional performance evaluation frameworks, introducing three major systemic risks:
- Automation bias. Human reviewers place too much trust in machine-generated labels. They assume the model is correct and click through complex tasks without checking subtle details.
- False confidence. Managers see a massive spike in weekly task completion rates and assume production is healthy, while systemic machine errors slip into the training set uncorrected.
- Inconsistent correction behavior. Without clear, calibrated guidelines, some annotators will spend hours rebuilding a slightly imperfect machine bounding box, while others will approve the flawed shape as-is.
These behavioral variances entirely ruin standard throughput and accuracy benchmarks. If an operations manager only evaluates speed, the most careless worker who blindly approves every flawed machine label will look great. Meanwhile, the careful, detail-oriented worker who systematically fixes subtle model biases will face reprimands for low production volume.
Because of these dynamics, rigorous human-in-the-loop quality control remains absolutely vital for modern enterprise data engineering. Human intelligence is required to spot compounding model drift, fix systematic machine biases, and maintain the underlying consistency of the dataset. To counter automation bias, advanced data operations track how often an annotator modifies machine tags.
If a worker accepts thousands of intricate pre-labels without making a single adjustment, it serves as an immediate behavioral flag that they are rushing. Tracking these editing patterns allows engineering leads to preserve the integrity of their datasets, ensuring the final training data actually improves downstream model accuracy.
Building Scalable Annotator Benchmarking Systems
As dataset volumes scale from thousands of samples to millions of complex records, informal tracking sheets and ad-hoc supervisor check-ins fail completely. Large data teams need a structured, scalable system built around reliable annotation performance metrics, not informal check-ins. This framework must show performance across large reviewer groups, multilingual projects, and long-term data ingestion pipelines. Strong annotator benchmarking relies on five operational foundations.
First, rigorous reviewer calibration must be established. If your internal quality auditors do not agree on the labeling rules, your main workforce cannot either. Operations managers must run weekly calibration sessions where separate reviewers score the exact same sample data. Any differences in their scores must be debated and resolved to update the core documentation.
Second, organizations must deploy sandboxed onboarding systems. New annotators should never work on live production datasets. Instead, they must prove their skills inside an automated training sandbox, labeling historical data with a verified ground-truth score. A trainee can only join the main production line once they meet strict accuracy targets within this controlled environment.
Third, empowered QA leadership is essential. Quality teams need independent management separate from production targets. When QA leads report directly to operations managers, who judge them solely on meeting tight deadlines, they often compromise quality metrics to ship data faster. Separating these roles protects the integrity of the data. Fourth, teams require standardized escalation workflows. When an annotator encounters a highly ambiguous edge case, they should not guess.
The platform must feature an integrated escalation path that routes the confusing asset to a senior team leader, ensuring the worker can move on to the next task without stalling. Finally, automated systems must support balanced sampling strategies. The underlying software infrastructure must automatically mix hidden test items into daily workflows. These blind performance tests allow management to gather true accuracy data and prevent workers from changing their behavior only when they know they are being audited.
Investing heavily in a scalable annotator benchmarking system gives enterprise teams a measurable return on QA investment. By catching human errors early, organizations achieve a significant annotation error reduction in dataset rework, eliminate unnecessary model retraining costs, and prevent downstream delivery delays. This systematic approach ensures that high-volume data operations run with the predictability and precision of an automated assembly line.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Common Benchmarking Mistakes That Damage AI Models
Poorly designed annotation performance metrics hurt far more than project management spreadsheets. Operational errors actively degrade AI model capabilities. When an organization uses an unbalanced annotation performance evaluation system, it creates a compromised foundation for model training. The workforce responds directly to how they are measured; if metrics are poorly designed, annotators change their behavior to hit superficial targets at the expense of data quality.
Enterprise operations often get caught in a few specific tracking traps:
- Rewarding speed over accuracy. Offering financial incentives or performance praise based solely on raw task volume, which encourages workers to skip difficult details.
- Relying solely on throughput metrics. Evaluating team health by daily task completions while ignoring long-term precision and systemic error spikes.
- Inconsistent QA scoring. This inconsistency allows different quality auditors to grade identical work batches using separate personal standards.
- Weak reviewer calibration. Failing to run regular alignment checks between separate reviewer cohorts, letting subjective definitions drift over time.
- Insufficient edge-case documentation. Letting annotators make independent guesses on unusual or ambiguous data points instead of writing down a clear team rule.
Data failures hurt downstream machine learning. Adding noisy, mislabeled data to a training pipeline limits model performance. Poor data quality causes severe model hallucinations in large language models, where systems confidently output falsehoods due to human contradictions in their fine-tuning data. Poor labels cause inconsistent computer vision predictions; an autonomous vehicle may hesitate or misidentify objects due to loose or misaligned bounding box edges.
Ultimately, these defects destroy deployment reliability, making models fail in chaotic, real-world environments and damaging overall enterprise AI trustworthiness with enterprise clients.
| Operational Defect | Direct Model Consequence | Downstream Business Impact |
| Speed Over Accuracy Bias | Structural label noise and boundary misalignment | High error rates in production models |
| Out-of-Sync Reviewer Teams | Shifting, inconsistent training targets | Poor model generalization on new data |
| Missing Edge-Case Documentation | Inconsistent handling of unusual data inputs | Systemic hallucinations and system failures |
The hidden business costs of these errors are high. When noisy data fails model validation, development teams must retrain repeatedly, forcing expensive cloud compute clusters to rerun identical workloads. If data is corrupted, organizations must spend weeks rebuilding it. Overlapping issues delay launches, allowing more agile competitors to beat the company to market. Managing a massive manual verification team to fix bad work increases QA overhead, making the data operation a major financial drain.
Tinkogroup’s Approach to Annotator Benchmarking and QA
At Tinkogroup, we manage data preparation through a rigorous engineering pipeline supported by real-time annotation performance metrics and structured quality assurance controls. To deliver the predictable data streams required by enterprise AI teams in the US and Europe, the operational framework relies on a streamlined, four-stage approach:
- Isolated production line. Tinkogroup splits workloads between core annotators focused on velocity and a completely separate team of senior QA reviewers. This prevents individual speed targets from compromising independent AI dataset validation.
- Continuous calibration. The platform automatically inserts hidden ground-truth tasks into active queues. This blind testing tracks real-time accuracy and catches individual quality drift instantly.
- Centralized edge-case logs. Instead of guessing on ambiguous data, workers use a structured escalation path. These assets route to a central log, which the team leads use during weekly syncs to update documentation with clear rules.
- Dynamic review tuning. Moving away from static checks, the system continuously tracks individual performance. Verified experts drop to a five percent audit rate, while new trainees remain on full review until their output stabilizes.
This approach keeps data operations scalable, cost-effective, and consistently high in quality.
Conclusion
To build dependable, production-ready artificial intelligence models, you need structured annotation benchmarking methods that balance delivery speed, reviewer consistency, and scalable QA governance. Relying on simple throughput tallies or rigid, manual reviews creates massive operational bottlenecks. These problems slow down important product releases, raise the cost of cloud computing, and lower the accuracy of the final model. Modern annotation performance metrics help enterprise teams improve data quality, reduce rework, and maintain predictable delivery schedules without sacrificing scale.
When an organization runs a weak reviewer performance evaluation, the downstream business costs accumulate rapidly. The business suffers from continuous dataset rework, expensive model retraining cycles, and missed market launch windows. Most importantly, inconsistent training data introduces systemic noise that causes model hallucinations and erratic behavior, directly damaging user trust.
To protect production timelines and maintain high data fidelity, enterprise teams must implement multi-dimensional performance tracking. By prioritizing inter-annotator agreement, dynamic sampling, and continuous reviewer calibration, operations leaders build highly predictable data pipelines that scale effortlessly alongside their compute infrastructure.
Are you ready to optimize your data preparation pipelines and eliminate operational bottlenecks? We can help you analyze your workflows, improve reviewer calibration, and streamline dataset delivery. Work with our data operations experts today at Tinkogroup to evaluate your annotation operations and build a cleaner, faster pipeline for your machine learning models.
Which annotation performance metrics are the most important for measuring annotator quality?
There is no single metric that provides a complete picture of annotator performance. The most effective benchmarking frameworks combine multiple indicators, including inter-annotator agreement, QA pass rates, annotation throughput, escalation frequency, reviewer overlap rate, and consistency scoring. Together, these annotation performance metrics help organizations evaluate both labeling accuracy and operational efficiency without relying on a single data point.
How can companies benchmark annotators without creating QA bottlenecks?
The key is to use risk-based quality assurance instead of reviewing every task manually. High-performing annotators can be evaluated through adaptive sampling, while new workers, low-confidence outputs, and complex edge cases receive additional review. This approach allows teams to maintain high data quality standards while keeping annotation workflows scalable and delivery timelines predictable.
Why is measuring annotation speed alone a poor performance benchmark?
Speed metrics only show how much work an annotator completes, not whether the work is accurate. Fast annotators may overlook edge cases, miss small objects, or introduce inconsistent labels that require costly rework later. Effective annotation performance metrics balance throughput with accuracy, consistency, and QA outcomes to ensure that productivity gains do not come at the expense of dataset quality and model performance.


