

A silent operational crisis in commercial AI deployment threatens production pipelines. Machine learning (ML) engineering teams often discover that models trained on massive, expensive datasets underperform in live production. Engineering teams rarely identify broken model architectures or inadequate compute allocations when auditing these failures. Instead, the failure vector usually points to systemic noise in the training data.
Enterprise teams routinely spend weeks drafting exhaustive, 100-page instruction manuals for data labeling. They falsely assume a comprehensive PDF will guarantee pristine dataset quality. Yet when the final labels arrive, teams find the data full of contradictions. This pervasive mismatch proves that traditional annotation guideline management is fundamentally broken for modern AI development when teams treat it as a static, check-the-box documentation task.
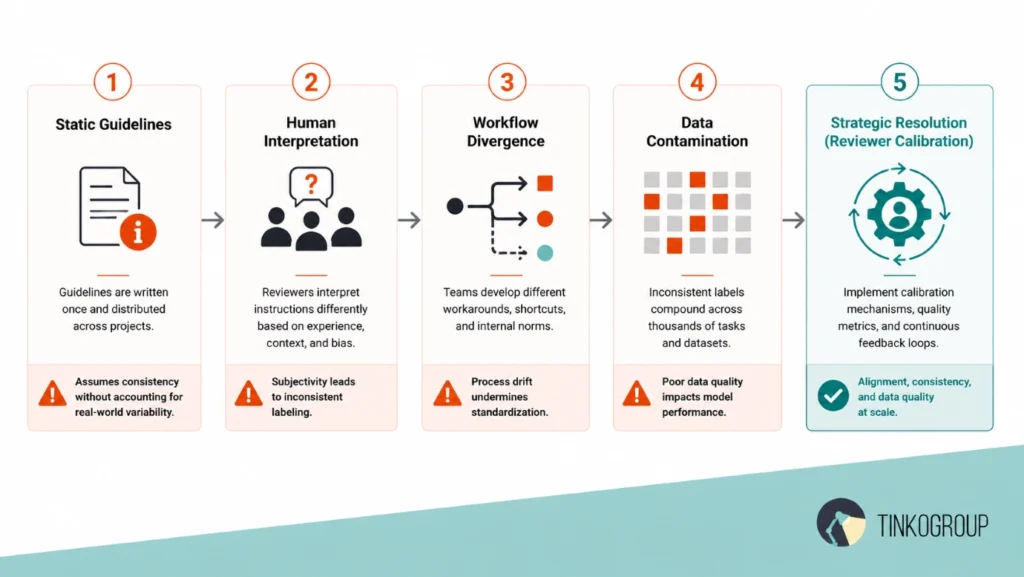
- Static guidelines. Engineering teams write detailed instruction manuals.
- Human interpretation. Distributed workers read the rules but understand them differently based on their personal bias.
- Workflow divergence. Reviewer A obeys the rule too strictly, while Reviewer B relies on intuition and changes it.
- Data contamination. These conflicting choices create hidden errors and noise inside the final dataset.
- Strategic resolution. The team implements continuous reviewer calibration to keep all human decisions aligned.
When data quality degrades, the downstream business costs accumulate exponentially. Inconsistent labels severely weaken model accuracy. Computer vision pipelines begin to misclassify edge-case objects, while large language models (LLMs) experience severe hallucinations due to conflicting human feedback during reinforcement learning (RLHF). For an enterprise, these annotation quality issues trigger long deployment delays, forcing data scientists to halt engineering pipelines to manually scrub poor-quality data.
The financial loss is substantial. Machine learning specialists waste up to 80% of their schedules cleaning dirty datasets. This burns thousands of costly GPU hours on wasted retraining runs. Ultimately, this administrative overhead ruins product launch timelines and degrades core enterprise AI reliability.
Fixing these issues requires a shift in focus from initial labeling rules to the evaluation phase. This is where reviewer calibration becomes essential. This is defined as the structured process of aligning annotators and quality assurance teams to ensure consistent decisions about label consistency in AI datasets. It moves data ops away from passive instructions and toward active alignment.
A static PDF cannot predict every messy, real-world data variation. Strong guidelines alone are insufficient without continuous reviewer calibration and structured QA governance. Without this active operational alignment, data quality becomes impossible to control at scale.
Why Good Annotation Guidelines Still Fail
The belief that detailed instruction manuals guarantee perfect data labeling consistency is a costly illusion in enterprise AI development, particularly when reviewer calibration processes are missing. Engineering leads often assume that if they write down a rule, human operators will execute it with algorithmic precision. However, when multi-vendor or distributed internal teams begin processing millions of data points, even the most meticulous documentation breaks down.
The core issue is that static manuals cannot eliminate human variance, contextual ambiguity, and linguistic shifts. To understand why data quality degrades despite rigorous documentation, enterprise operations must evaluate the primary operational blind spots where standard annotation guideline management fails.
When teams analyze why production data drifts so rapidly, they discover that written rules inevitably collide with the unpredictable complexity of the real world. A technical writer working in an isolated environment cannot predict every variable that a global workforce will encounter on a Tuesday afternoon.
Human language, visual scenes, and behavioral patterns are too fluid for rigid documentation. Because of this natural friction between static theory and dynamic reality, several structural catalysts consistently cause documentation pipelines to fail:
- The reality of edge cases. Real-world data presents complex scenarios that technical writers never anticipated during initial scoping phases. As a result, annotation staff must guess the correct classification without immediate supervisor guidance.
- Inherent semantic ambiguity. Words, phrases, and visual scenes naturally support multiple valid interpretations. A single word in an instruction manual can mean different things to different operators, depending on their training.
- Subjective interpretation. Abstract concepts such as “toxic text,” “high-quality imagery,” or “safe behavior” mean different things to different people. Individual workers rely on their values to interpret guidelines that lack exact metrics.
- Multilingual project complexities. Regional idioms, cultural nuances, and localized terminology rarely translate perfectly across global labeling teams. This lack of clear translation creates severe logical friction for international teams.
- Annotation drift over time. Human workers slowly forget the initial project training during six-month or year-long operations. They gradually invent unwritten shortcuts, causing the data standard to slowly drift away from the original documentation.
Label inconsistency multiplies as an annotation operation scales from a 5-person pilot team to 500 employees. Small-scale annotators can resolve ambiguous cases in informal chats or Slack messages. But enterprise communication silos keep teams apart across shifts and regions. Individual interpretation subcultures emerge among workers without an active alignment strategy. This fragmentation corrupts the entire dataset, leading to severe annotation quality issues that stall production pipelines and emphasize the necessity of continuous reviewer calibration.
To see why reviewer calibration is necessary in a live production environment, managers must look at how instructions translate to daily workflow choices. When abstract rules meet complex raw data, different workers naturally develop conflicting logical paths. This friction appears clearly when analyzing common production tasks across different AI disciplines:
- Computer vision (autonomous driving). The instruction manual states: “Label all vehicles used for commercial transport.” Reviewer A views a corporate shuttle van parked on a street and applies the label. Reviewer B, looking at the exact same frame, filters the vehicle out because it lacks public commercial branding. The model now receives two identical visual scenarios labeled in completely opposite ways.
- Natural language processing (content moderation). The rule says: “Flag any customer comment containing aggressive or threatening language.” A user posts: “If I don’t get my refund by Friday, you will lose me forever.” Reviewer A flags the comment as an explicit financial threat to the business. Reviewer B interprets it as normal customer frustration and marks it safe.
- E-commerce product classification. The guidelines require catalog teams to tag items as “Premium Luxury Items” if their market value exceeds a specific threshold. However, when evaluating rare collectibles or vintage apparel, regional reviewers calculate the base asset values differently. This regional difference breaks the core catalog categorization system.
These real-world examples highlight why passive documentation cannot maintain data integrity. When different reviewers evaluate identical data samples using different logic, they introduce damaging noise into the machine learning pipeline. This operational gap shows why enterprise AI teams must move beyond static text documents and implement continuous reviewer calibration engines to synchronize human judgment in real time.
Human Factors, Reviewer Disagreement, and Annotation Metrics
Data annotation is a highly repetitive, mentally demanding task. Human operators aren’t software scripts; they do not process information with identical annotation consistency hour after hour. Cognitive fatigue, domain expertise, and hidden cultural biases affect performance. Reviewers starting their shifts at 9:00 AM analyze complex edge cases with a fresh perspective. By 5:00 PM, cognitive fatigue has set in for that worker. They may rush through difficult decisions and rely on quick intuitions to meet daily speed targets.
Furthermore, varying levels of domain expertise create wide gaps in quality. If a general copywriter is assigned to label a specialized legal contract or a medical dataset, they will naturally miss critical contextual clues that an experienced attorney or radiologist would catch instantly. This human variance introduces hidden errors that can easily bypass basic quality checks. Effective reviewer calibration programs are designed to detect and correct these variations before they affect the final dataset.
To monitor these human factors and track operational drift, data operations managers rely on mathematical quality metrics. These statistical frameworks are designed to pinpoint variance and provide a quantitative view of workforce alignment. In typical production environments, operations leads implement a combination of four core metrics and tracking strategies:

- Inter-annotator agreement (IAA). Statistical formulas like Cohen’s Kappa or Fleiss’ Kappa measure how often different human workers choose the exact same label for identical data samples. These metrics often serve as the foundation of a reviewer calibration strategy.
- Reviewer overlap strategy. A dedicated setup where a specific percentage of the total dataset (typically 10% to 20%) is secretly assigned to multiple workers to track decision variance.
- Consensus scoring. An automated voting system where the system accepts a label only if a majority of independent annotators select the exact same value.
- Disagreement escalation workflows. A programmatic path that automatically flags samples with low consensus scores and routes them to senior domain experts for final review.
While these statistical dashboards look impressive on manager reports, metrics alone cannot guarantee clean training data. In fact, relying too much on high inter-annotator agreement scores can create a dangerous false sense of security. High agreement scores show that workers match each other’s choices, but they do not prove that those choices match the actual ground truth.
If an entire group of annotators goes through a flawed onboarding process, they will all misunderstand a specific rule in the exact same way. They will consistently apply the wrong label to the same data types. Their mathematical agreement score will look flawless, but the entire dataset will contain systematic errors. The model will then train on a unified set of incorrect examples, leading to predictable failures in production.
When reviewer disagreement spikes on a production dashboard, project managers shouldn’t just blame the workforce. High disagreement rates are usually a symptom of deeper structural flaws in the data pipeline rather than simple human carelessness. Frequent mismatches between workers generally point to three systemic problems in the underlying operational design:
- Unclear ontology design. The data categories and label classes overlap too much, making it impossible for staff to make clear, distinct choices.
- Weak onboarding processes. New workers are pushed into live production tasks before they fully understand the project’s real-world complexities.
- Missing calibration processes. The operational framework fails to run regular sync sessions where human workers can talk through and resolve conflicting interpretations.
To build reliable enterprise AI models and maintain high AI training data quality, teams must look beyond passive, high-level dashboards. True data quality requires active, operational alignment strategies that address the root causes of human error before the data reaches the model training phase.
What Reviewer Calibration Looks Like in Enterprise Annotation Workflows
Moving from a reactive quality control model to a proactive reviewer calibration framework requires a fundamental shift in daily operations. Instead of checking data quality at the very end of a monthly delivery cycle, enterprise AI teams integrate alignment practices directly into their daily production schedules. These practical steps prevent different interpretation styles from hardening into permanent errors.
In a live enterprise environment, successful data managers rely on highly synchronized annotation reviewer workflows to identify and resolve decision variances before they can corrupt the larger training pool.
To keep large, distributed workforces fully aligned over long-term projects, enterprise operations rely on a specific sequence of production milestones. The process begins when project leaders inject a blind test batch of data, filled with known edge cases, into the active production lines. Every reviewer and quality assurance lead evaluates these identical samples completely independently, without consulting one another.
Once the initial marks are submitted, data managers run automated disagreement reviews to find the exact mathematical variance between the workers’ choices. Instead of letting these mismatches sit in a database, the entire team meets during live reviewer sync sessions to debate the conflicting logic on screen. This collaborative review ensures the team reaches a single source of truth, which they immediately document as an official update in the master instruction manual.
When a data point proves too complex for the standard review team, it triggers a structured QA escalation workflow that routes the sample to senior domain experts, preventing operational bottlenecks.
The team uses the data collected from these calibration sessions to maintain a dynamic infrastructure that supports the entire project lifecycle. Without these constant adjustments, even the best teams will naturally drift apart over time. A balanced, high-precision data factory relies heavily on four core management tools to lock in long-term alignment:
- Gold-standard datasets. Managers curate a master set of perfect data samples verified by top-tier domain experts. These gold samples are secretly mixed into the daily production queues of ordinary reviewers to continuously test their accuracy and spot individual quality drops.
- Continuous feedback loops. When a reviewer makes an error on a hidden gold sample or deviates during a calibration round, the platform sends a targeted feedback alert. This alert shows the worker exactly what they missed and how to correct their logic on the next task.
- Ongoing guideline updates. Instruction manuals are treated as living digital documents rather than static text files. Every time a live sync session resolves an ambiguous edge case, the team adds the decision to a searchable logbook, keeping the core documentation aligned with real-world data.
- Active reviewer alignment tracking. Operations managers track individual agreement trends over time. If a worker’s alignment score slips below a strict quality threshold, the system temporarily removes them from production tasks and routes them back to targeted training sandboxes.
By running these scalable data annotation workflows every single week, enterprise teams build a reliable, self-correcting human engine. This continuous operational alignment ensures that as the dataset grows, the labeling decisions remain uniform, protecting the downstream machine learning pipeline from systemic noise.
Why Human-in-the-Loop QA Still Matters in AI-Assisted Annotation Pipelines
The widespread adoption of foundation models has changed how enterprises handle large-scale data engineering. Modern teams rarely start projects with completely raw, unannotated data. Instead, they use advanced machine-assisted labeling pipelines to manage the workload. By leveraging AI to process the initial data pass, companies can scale up their operations while reducing the manual labor traditionally required by human annotators.
In modern enterprise production, data managers generally rely on two primary automated workflows to speed up their pipelines:
- AI-assisted pre-annotation systems. Specialized computer vision or natural language processing models process raw files first, drawing initial bounding boxes or tagging basic parts of speech before a human ever sees the asset.
- LLM-supported labeling workflows. Large language models evaluate text data to perform initial sentiment analysis, category classification, or entity extraction, transforming messy, unorganized text into a structured draft format.
While these automated methods drastically reduce manual clicking and typing, they introduce new risks to data integrity. Automated models are excellent at recognizing clear, predictable patterns, but they lack true semantic understanding. If an enterprise relies entirely on machine-generated output without a rigorous validation layer, the dataset quickly suffers from systemic bias. Automated systems can easily miss subtle contextual clues, leading to repetitive, hidden errors that damage quality control in data annotation.
This specific vulnerability is why human-in-the-loop quality control (HITL QA) and reviewer calibration remain essential requirements for modern machine learning pipelines. Human specialists act as a critical validation filter, identifying and correcting the nuanced errors that automated algorithms routinely miss. Automated labeling workflows frequently break down in several key areas that require human intervention:
- Ambiguous edge cases. Machine models struggle with data points that do not fit neatly into their pre-trained categories, often making highly confident but completely incorrect guesses.
- Deep contextual interpretation. Automated tools regularly misinterpret human sarcasm, cultural humor, or historical metaphors in text, and they often misidentify unusual lighting or occluded objects in imagery.
- Long-tail inconsistencies. Rare, unusual events that appear infrequently in real-world data are often mislabeled by pre-annotation tools because those models have not seen enough similar examples during their training.
- Domain-specific labeling complexity. Automated models lack the nuanced understanding required for highly specialized fields, such as identifying complex anomalies on medical scans or parsing dense compliance clauses in corporate legal contracts.
Furthermore, human reviewers prevent the dangerous phenomenon of automated data drift. When a human operator reviews machine-generated labels, they often become tired and passively accept the model’s suggestions without checking them carefully. Calibrated human validation ensures that reviewers actively challenge automated tags rather than rubber-stamping them. By combining machine speed with human precision, enterprises secure a reliable data foundation for their production models.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

Scaling Annotation Quality Across Large Enterprise Datasets
Scaling a data pipeline to millions of annotations introduces severe operational friction. At high volumes, distributed teams naturally create isolated habits of interpretation, which quickly corrupts the broader training pool. To prevent these issues, mature data production facilities rely on highly structured, scalable annotation operations. These frameworks replace informal communication with explicit operational controls designed to keep large workforces uniform. Successful enterprise scale-up strategies focus on five core operational pillars:
- Tiered reviewer onboarding. New operators must clear localized sandbox testing environments that mirror real project complexities before joining active teams.
- Decentralized QA leadership. Workforces are divided into small squads overseen by a dedicated quality assurance lead who maintains a tight ten-to-one ratio with core annotators.
- Increased reviewer calibration frequency. As data volume expands, calibration sessions accelerate to mandatory weekly milestones to catch interpretive drift early.
- Data-driven workforce management. Management software tracks individual accuracy scores in real time, automatically assigning highly complex edge cases to top-performing specialists.
- Rigorous escalation structures. Reviewers route confusing files through a formalized ticketing system directly to senior domain experts, avoiding individual guesswork.
Implementing these industrial-scale workflows significantly reduces downstream engineering friction across four critical corporate metrics:
- Minimized annotation inconsistency. Uniform management ensures that data generated in separate global facilities carries identical labels.
- Reduced rework costs. Catching interpretive errors within hours prevents teams from having to scrap and manually re-label massive blocks of completed work.
- Decreased retraining requirements. Clean datasets allow machine learning models to converge predictably, saving costly GPU hours on repeated corrective cycles.
- Eliminated deployment delays. Eliminating data corruption allows engineering teams to hit their launch milestones on time without sudden dataset audits.
True operational scale means maintaining pristine, predictable data quality even as the underlying production volume multiplies exponentially.
Common Calibration Failures That Damage AI Models
When data operations teams treat quality management as a static milestone rather than a continuous process, validation pipelines break down. Many organizations establish detailed instructions initially but fail to actively maintain human alignment as new data streams enter the system. This operational neglect creates severe structural blind spots that allow corrupted information to slip directly into the core machine learning pipeline. The most frequent operational pitfalls that sabotage quality control systems include:
- Static guidelines. Leaving instruction manuals completely unchanged for months while the incoming real-world data distribution naturally evolves.
- Weak onboarding. Pushing new personnel into live production queues after a brief reading session without verifying comprehension through testing.
- Inconsistent reviewer escalation. Failing to provide a clear, rapid path for reporting ambiguous samples, forcing tired workers to guess to hit speed targets.
- Overreliance on automated QA. This means trusting simplistic, programmatic validation scripts to catch deep semantic errors that require nuanced human understanding.
- Insufficient edge-case documentation. Resolving complex disagreements during isolated meetings but failing to log decisions in a centralized, searchable repository.
When operational checks fail, dataset corruption causes a domino effect across the technical architecture. The database quickly becomes cluttered with contradictory labels from static guidelines. This data corruption directly causes model hallucinations during training as the algorithm searches for logical patterns in conflicting human signals. These erratic predictions destroy production reliability, causing a business crisis where users lose trust in the enterprise AI application.
Beyond the immediate technical damage, these quality blind spots introduce massive, hidden operational costs. When a model underperforms, the engineering team must launch emergency dataset audits, triggering substantial retraining expenses as teams burn thousands of GPU hours.
Furthermore, internal QA overhead multiplies, and in severe cases, companies face complete dataset rebuilding from scratch. These corrective actions lead to prolonged delayed releases, causing companies to miss market opportunities and cede their competitive advantage. Prioritizing proactive annotation error reduction through continuous reviewer calibration is a critical requirement for protecting enterprise product timelines and corporate budgets.
Tinkogroup’s Approach to Reviewer Calibration and QA
Managing annotation quality for machine learning operations requires structured human systems rather than simple technical scripts. Tinkogroup addresses this operational challenge by providing specialized, multi-stage validation pipelines built for leading US and European AI companies. The operational model replaces traditional peer review with an active infrastructure designed to maintain strict annotation quality assurance baselines across complex, enterprise-scale projects.
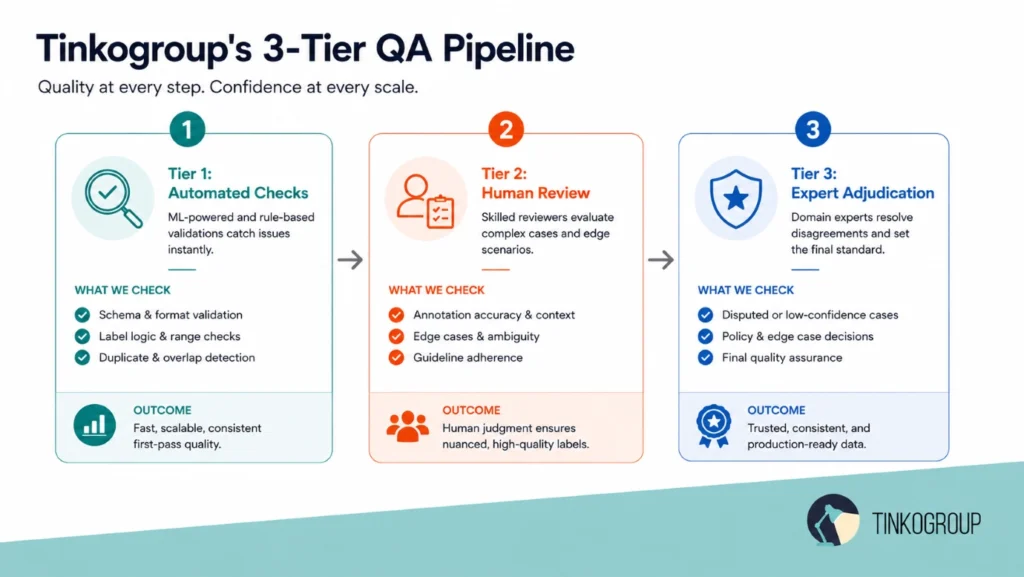
Instead of treating workforce alignment as a high-level goal, the production team uses a strict three-tier processing structure to handle incoming source data:
- Tier 1: Specialized labeling. Tasks route exclusively to dedicated reviewer teams who have cleared rigorous background screening and language testing for specific data types.
- Tier 2: Blind quality auditing. Internal software mirrors 15% of all active production tasks, distributing identical data samples to independent validators to flag interpretative variance.
- Tier 3: Senior expert arbitration. Any sample that falls below strict consensus thresholds routes directly to a specialized arbitration board for final, definitive review.
To eliminate human variance under heavy production pressure, the validation infrastructure operates as a strict progressive pipeline. The workflow begins with raw production ingestion, where incoming assets route exclusively to dedicated reviewer teams for initial classification. To catch localized errors, the system triggers an automated task mirroring protocol, secretly duplicating fifteen percent of all active tasks and distributing them to independent validators.
When the software detects an interpretive variance between these workers, it automatically generates a variance flag. This alert isolates the sample and routes it directly to senior arbitration leads, who execute a final consensus update. Once resolved, the verified assets pass through a final check, ensuring pristine export validation before the data ever reaches the client’s training servers.
When a reviewer deviated from a calibrated standard during a recent multilingual NLP project, the system triggered an automated feedback loop. This alert sent the error back to the worker’s queue along with a detailed explanation of the required logic. To handle changing data distributions, supervisors conducted weekly alignment sessions. During these meetings, validators reviewed flagged edge cases live on screen to resolve conflicting viewpoints.
Once the team reached a consensus, managers updated a living edge-case logbook, converting individual human insights into systematic rules across the entire workforce. This discipline keeps quality consistent as the operation grows. By using human-in-the-loop oversight at every stage, the validation process prevents individual reviewer fatigue from compromising dataset integrity, allowing internal machine learning engineers to focus on architecture while knowing their training data is mathematically clean.
Conclusion
Building reliable, high-performance artificial intelligence applications requires much more than comprehensive instruction manuals. While detailed documentation provides a baseline, true dataset consistency depends on aligned human judgment, structured reviewer calibration workflows, and scalable QA systems.
Static guidelines cannot anticipate the complex edge cases found in real-world environments. Without continuous operational alignment, distributed human groups will naturally interpret instructions differently, creating conflicting data labels that compromise the entire machine learning model.
Ignoring human variance carries real business costs. Failing to maintain a rigorous quality control process introduces hidden noise into data pipelines, leading to significant corporate liabilities:
- Increased retraining costs. Forcing machine learning models to train on contradictory examples requires multiple corrective computing cycles, wasting valuable engineering hours and burning expensive GPU resources.
- Extensive annotation rework. Detecting systematic data errors late in the development cycle forces project teams to scrap and re-annotate massive blocks of completed data.
- Prolonged deployment delays. Resolving data quality issues near release deadlines stalls product launches, allowing faster competitors to capture the market first.
- Severe model reliability risks. Training pipelines on noisy data leads directly to high hallucination rates and unpredictable predictions in production, destroying user trust in high-stakes environments.
To protect product timelines and corporate budgets, modern AI enterprises must treat reviewer calibration and quality control as active, continuous management processes. Proactive alignment prevents downstream data failures, converting raw, inconsistent data into reliable training material.
Optimize Your Data Engineering Pipelines
Don’t allow hidden data drift to slow down your production releases. Partner with an experienced team that knows how to deliver quality at scale.
- Discuss data annotation QA workflows. Set up QA workflows for data annotation and an operational consultation with our data experts to audit your current AI dataset validation processes.
- Improve dataset consistency. Find out how our structured alignment methods eliminate edge-case ambiguity from your training pools.
- Evaluate reviewer calibration processes. Discover how our dedicated teams can optimize your quality metrics and reduce model error rates.
Explore our enterprise data processing solutions and find out how we can streamline your production pipelines by visiting the Tinkogroup data labeling services page today.
What is reviewer calibration in data annotation?
Reviewer calibration is the process of making sure that annotators, reviewers, and QA specialists all follow the same labeling guidelines consistently across a dataset. Rather than relying solely on written instructions, calibration uses overlap reviews, consensus scoring, feedback loops, and regular alignment sessions to reduce interpretation differences and improve annotation quality at scale.
How often should annotation teams conduct reviewer calibration sessions?
The ideal frequency depends on project size and complexity. Small teams may conduct calibration sessions monthly, while large enterprise annotation programs often run them weekly. Calibration should also be performed whenever new guidelines are introduced, new reviewers join the project, or disagreement rates begin to increase. Regular calibration helps prevent annotation drift and maintains long-term consistency.
Is inter-annotator agreement enough to measure annotation quality?
No. Inter-annotator agreement measures how often reviewers select the same label, but it does not guarantee that the label is correct. A team can achieve high agreement while consistently applying the wrong interpretation of a guideline. For this reason, organizations typically combine agreement metrics with reviewer calibration, expert adjudication, gold-standard datasets, and ongoing QA audits to ensure both consistency and accuracy.


