

Annotation adjudication has become one of the most critical operational disciplines in modern AI data production. The commercial race for dominance in artificial intelligence is fought not on the pages of academic journals but on the invisible assembly lines of global data factories. While venture capital firms and tech executives debate model architectures, cluster sizing, and parameter counts, machine learning operations (MLOps) leaders spend their days fighting a less glamorous reality. The primary obstacle stalling enterprise-level model deployment is the poor, contradictory quality of human-labeled data.
At a small scale, managing a data labeling pipeline seems straightforward. A company hires a handful of contractors, hands them a set of instructions, and asks them to draw boxes or categorize customer reviews. However, when an enterprise scales its operations to train foundation models, large language models (LLMs), or safety-critical computer vision systems, this simplistic view breaks down completely.
The hidden challenge stalling enterprise data production is not finding people to label information; it is figuring out how to handle the inevitable conflicts when those people disagree, without creating massive quality assurance (QA) bottlenecks that delay product launches.
Labeling conflicts do not disappear when an organization hires more experienced workers or writes longer guidelines. Instead, as the complexity of the data increases, the variance in human interpretation grows exponentially. This structural friction occurs across all major data domains:
- Natural language processing (NLP) projects. Human language relies heavily on context, culture, and subtle emotional cues. A single paragraph can contain sarcasm, regional idioms, and double meanings. If an enterprise team builds a financial sentiment model, one expert reviewer might flag a CEO’s public statement as “cautiously optimistic,” while another codes it as “neutral” based on the exact same text.
- Computer vision datasets. Training autonomous driving networks or warehouse robotics requires precise semantic segmentation and pixel-perfect bounding boxes. In real-world environments, cameras capture frames through heavy rain, lens glare, and thick shadows. When a pedestrian stands behind a semi-transparent plastic barrier, annotators will consistently draw conflicting boundaries, debating exactly where the human figure ends and the static environment begins.
- Content moderation workflows. Global web platforms must filter out harmful material while protecting free speech. This requires navigating gray areas where political commentary, dark humor, and targeted harassment overlap. Labeling instructions can never cover every evolving real-world internet trend, leading to constant reviewer disagreement among safety staff.
- Edge-case-heavy annotation tasks. High-stakes industries like medical imaging or aerospace manufacturing deal with datasets where 99% of the assets are standard, but the remaining 1% contains highly confusing edge cases. When analyzing a rare mechanical fault or a subtle clinical anomaly, even top-tier subject matter experts will interpret the visual evidence differently.
Without an efficient framework to resolve these conflicting decisions, enterprises quickly incur operational and financial damages. First, the pipeline produces inconsistent datasets. If contradictory labels flow into a machine learning model during the training phase, the model fails to converge efficiently, leading to unstable predictions. Second, the lack of a clear escalation overloads reviewers. Senior machine learning engineers and QA leads manually check minor text variations instead of model architecture due to thousands of open tickets.
This operational drag leads directly to delayed delivery schedules. Engineering teams miss critical deployment windows, giving competitors a chance to capture market share. Furthermore, if teams do not catch these errors early, they incur massive retraining costs. Discovering that a dataset is fundamentally corrupted after spending hundreds of thousands of dollars on cloud compute power to train a model is a financial disaster. The resulting operational inefficiency can derail an entire company’s AI product roadmap.
Modern data factories need a formal data conflict mechanism to break this cycle. Annotation adjudication is used to resolve disagreements between annotators and reviewers. This process is not a simple administrative task; it is a core operational discipline. Implementing effective adjudication workflows allows enterprise organizations to protect and improve overall AI training data quality while maintaining the fast, predictable, and scalable delivery schedules required by modern market conditions.
Why Disagreement Is Unavoidable in Complex Annotation Projects
Many engineering managers look at a high rate of labeling conflict and assume it stems from a weak workforce. They believe that if they fire low-performing contractors, rewrite the documentation, or create tougher training quizzes, their workers will suddenly produce identical, perfect labels. This view reflects a basic misunderstanding of human linguistics and cognitive psychology.
In real-world enterprise environments, even highly trained, carefully vetted annotators with deep domain knowledge will interpret the exact same data point differently. Disagreement is an inherent feature of complex datasets, not an error caused by human negligence. Understanding this reality is the foundation of effective Annotation Adjudication strategies in enterprise data operations.
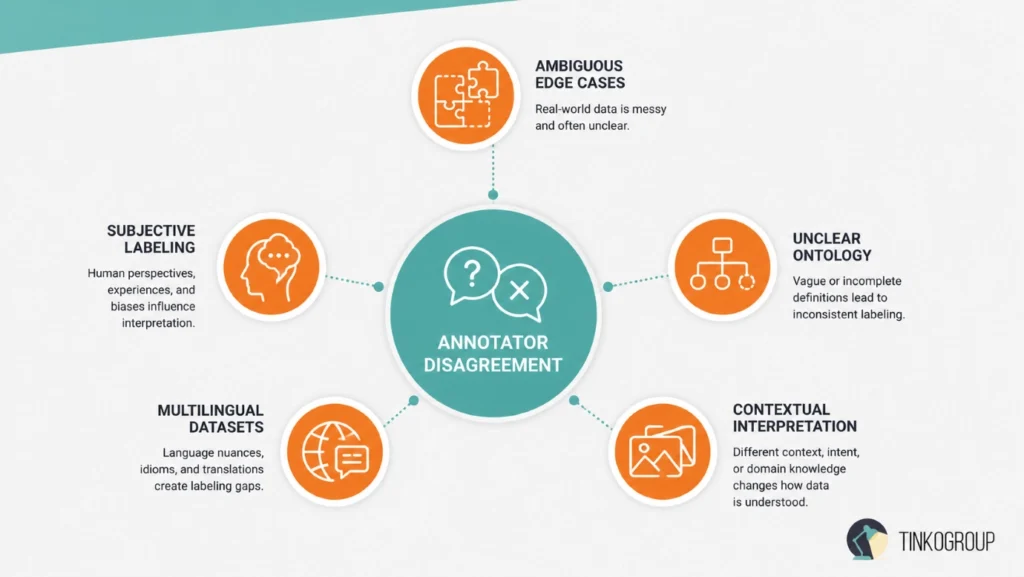
To manage an operation smoothly, data leaders must accept that human beings approach data from diverse mental perspectives. Several core operational forces drive these differences:
- Ambiguous edge cases. Real-world data is naturally messy. A camera frame from a delivery drone might capture an object that tree branches obscure by 60%. Is it a wild animal or a garden statue? The raw image does not contain enough pixels to provide an absolute answer.
- Subjective labeling requirements. E-commerce search optimization tasks often ask workers to evaluate if an item is a “relevant” alternative for a missing product. “Relevance” is a personal opinion that changes based on a person’s age, income level, and regional habits.
- Unclear ontology definitions. Data taxonomies must adapt quickly to shifting market needs. If an enterprise company modifies a category label from compact_car to urban_mobility_vehicle, workers will naturally disagree on how to categorize small delivery vans until the new rule is fully clarified across the entire team.
- Multilingual datasets. Translating and labeling emotional intent across local dialects introduces deep cultural variance. A phrase that sounds completely polite in one city might feel passive-aggressive or insulting to a reviewer living in another region.
- Contextual interpretation differences. Financial compliance projects require analysts to flag high-risk transactions. A reviewer with a legal background looks at the text through a strict regulatory framework. A reviewer with an accounting background focuses on cash-flow anomalies. Both viewpoints are intelligent, yet they produce completely different labels.
Let us look closely at how these drivers impact production lines across specialized industries. In NLP tasks like LLM safety benchmarking, context is everything. Consider the phrase: “That movie was sick!” In youth slang, the phrase is a highly positive review. In a medical or classic content moderation setup, it indicates something negative or disturbing. When your global workforce spans multiple generations or geographies, you will see massive variance in your raw data metrics.
The situation becomes even sharper in medical annotation, such as segmenting CT scans to identify early-stage oncology. Studies regularly published in prominent radiological journals demonstrate that inter-observer variability among senior practicing clinicians remains high. If medical doctors with decades of experience cannot reach immediate consensus on the boundaries of a complex lesion, it is operationally unrealistic to expect automated consensus from a standard, linear labeling workforce.
The primary takeaway for an AI Operations Manager is clear: do not penalize your team for showing low inter-annotator agreement metrics on complex tasks. Instead, look at these moments as natural outcomes of handling highly sophisticated information. The goal of your data operation should not be the impossible elimination of all human variance. The goal must be creating a structured operational resolution path using dedicated annotation adjudication strategies.
The Role of Adjudication in Annotation Quality Assurance
Annotation adjudication workflows systematically resolve label conflicts. This approach prevents errors from entering training sets, maximizes operational efficiency, and ensures high annotation consistency.
Core Conflict Resolution Methods
Enterprise data teams route conflicting labels through four standard operational paths:
- Tie-break reviews. A third independent annotator quickly breaks deadlocks on low-complexity tasks.
- Senior escalation. Dedicated QA leads manually evaluate highly complex, high-risk assets.
- Consensus review. Small groups debate edge cases to establish unified guidelines.
- Gold-standard benchmarks. Automated systems favor workers with higher historical accuracy scores.
Three Pillars of Adjudication Governance
A professional annotation quality assurance framework relies on strict infrastructure:
- Escalation logic. Conditional routing rules automatically move high-disagreement assets to senior queues.
- Documented decisions. Reviewers log their reasoning to build a central operational encyclopedia.
- Edge-case governance. Committees audit weekly logs to update broken ontology definitions.
Why Majority Voting Fails
Simple majority voting embeds systematic errors into complex datasets. Rushed or inexperienced workers frequently choose the easiest wrong label, outvoting the single expert who understands the nuance. Reliable data operations require structured conflict resolution led by specialists, not popularity contests.
How Poor Adjudication Systems Create QA Bottlenecks
When data operations leaders fail to design efficient escalation structures, their production pipelines inevitably suffer from severe friction points. A bottleneck occurs when the incoming volume of disputed labels far exceeds the team’s operational capacity to resolve them. This issue stalls the entire machine learning pipeline, leaving data scientists waiting for training assets.
Structural Failures That Stall Operations
Several common operational mistakes lead directly to massive bottlenecks in enterprise data pipelines:
- Unclear reviewer ownership. When labels clash, the system puts a warning flag on the asset but does not assign it to a specific person. The item sits in a general queue. Everyone assumes someone else will fix it.
- Excessive escalation. This is the “safe manager” trap. To ensure perfect quality, operations rules state that every single label disagreement must be reviewed by the lead AI engineer. The engineer gets buried under 5,000 basic text variations, stopping all development work.
- Static review policies. Treating all data variations with the same level of intensity creates massive waste. A minor 2-pixel difference in a bounding box corner gets the same complex escalation treatment as a completely missing box.
- Inconsistent final decisions. Two different QA leads resolve identical label conflicts in opposite ways because they do not communicate. This inconsistency creates confusion among the primary annotators, leading to even more errors and more disputes.
- Unresolved edge-case documentation. When an edge case gets resolved, the answer stays inside the reviewer’s head. The global guidelines are never updated. As a result, the annotators make the exact same mistake tomorrow, forcing the team to repeat the entire review process.
Most of these issues can be traced back to weak or poorly designed Annotation adjudication processes.
The Impact on Operations
These structural failures cause immediate, measurable damage to project timelines. Complex annotation escalation workflows that lack clear routing cause senior reviewers to check identical data points multiple times. This duplication burns out your most expensive specialists and skyrockets your overall cost per labeled asset.
As the unresolved queue grows, delivery dates shift backward. Annotation teams miss their milestones, and the enterprise company loses its competitive edge in the fast-moving AI market.
Smarter Operational Frameworks
To prevent these damaging bottlenecks, mature operations leaders replace static, rigid rules with dynamic, intelligent escalation workflows:
- Risk-based escalation. Not all label conflicts carry the same weight. If a disagreement happens on a high-risk data class (like a pedestrian in an autonomous driving dataset), route it to maximum human review. If the conflict happens in a low-risk class (like a cloud in the sky), let an automated script pick the majority vote.
- Selective adjudication. Track the real-time confidence scores of your annotators. If two highly accurate workers with long histories of clean work agree on a label, skip the review phase entirely. Only trigger formal adjudication when low-performing or newly onboarded workers disagree.
- Dynamic QA sampling. Instead of forcing a human to look at 100% of the disputed items in a clean batch, use statistical sampling. If a random check of 10% of the resolved conflicts shows an accuracy rate above 98%, trust the batch and push it directly into the production delivery queue.
- Benchmark-triggered review escalation. Set clear limits on your annotation quality metrics. If a worker’s daily agreement rate drops below a set threshold (e.g., 85%), the platform should automatically route their work into the senior review queue. This helps catch systemic issues before they corrupt a large portion of the dataset.
Balancing Quality, Speed, and Scale
The ultimate goal for an operations team is to find a healthy balance between dataset quality, reviewer workload, delivery speed, and overall scalability. By deploying intelligent, automated routing systems, enterprise data operations can scale up their production volume by 10x without needing to expand their expensive senior internal QA teams.
Adjudication in AI-Assisted Annotation Pipelines
The integration of artificial intelligence into data preparation pipelines has completely changed the field of data operations. Today, modern enterprise pipelines rarely rely on human effort alone. Instead, teams deploy complex, automated multi-stage systems to speed up the process.
The Architecture of AI-Assisted Pipelines
A modern automated labeling operation generally uses three primary technological layers:
- Auto-labeling systems. High-speed models process raw data batches first, automatically drawing bounding boxes or generating initial text descriptions. The system handles up to 75% of the simple work before a human ever logs into the platform.
- LLM-assisted pre-annotation. Large language models read complex corporate documents, pre-highlighting key legal clauses, entities, or emotional tones according to the project’s data schema.
- Model-assisted QA. Background validation models scan human-labeled data in real time. If a human worker applies a label that challenges the model’s high-confidence predictions, the system flags that specific point for extra review.
The New Disagreement Challenges
While automation cuts production time significantly, it introduces hidden operational risks that can quietly corrupt dataset quality:
- Automation bias. Human reviewers become lazy when looking at pre-labeled data. If an AI auto-labeler places an incorrect bounding box on an image, a tired human worker will often click “approve” without double-checking the boundaries.
- Inconsistent correction behavior. Different human reviewers handle AI errors in vastly different ways. If an LLM generates a slightly imperfect text summary, Reviewer A might rewrite the entire paragraph, while Reviewer B leaves it exactly as it is. This variation hurts your overall annotation consistency.
- False reviewer confidence. Because the pre-labels look highly polished, human teams assume the underlying data is correct. This causes them to overlook deep logical errors, such as a model hallucinating a fact in a legal contract review.
- Hidden annotation drift. Over weeks of production, human reviewers gradually adapt to the style of the AI model. Rather than correcting the model according to the project guidelines, they begin to accept its mistakes as the new standard. This causes the entire dataset to drift away from the original goal.
The Necessity of Human Oversight
This is why Annotation adjudication remains essential even in highly automated labeling environments. These risks demonstrate why automated systems can never completely replace human judgment. Deep human-in-the-loop quality control is essential for maintaining high dataset integrity.
Machine models excel at recognizing common, repetitive patterns across large datasets. However, they lack the nuanced understanding required to handle confusing edge cases or complex structural changes.
When an auto-labeler encounters a data point that falls outside its training experience, its confidence scores drop. This creates a new type of conflict: a disagreement between machine prediction and human insight.
A structured human team must manage these points. Human reviewers act as the ultimate judge, verifying machine suggestions, correcting subtle biases, and making final decisions on complex data points.
This hybrid approach combines the speed of AI automation with the reliable judgment of human experts. This balance ensures your enterprise data remains clean, accurate, and ready for deployment.
Building Scalable Adjudication Workflows for Enterprise Datasets
Scaling up an annotation operation from 10,000 simple data points to 50 million complex items requires moving away from manual management. Enterprise data operations must run like highly efficient factories. They need structured systems that maintain high annotation consistency across large teams, diverse languages, and long project timelines.
Scalable Annotation adjudication frameworks help organizations maintain consistency across millions of labeled assets while minimizing operational overhead.
Key Pillars of Enterprise Scale
To scale up your data pipeline without sacrificing quality, you must build your operations on four essential pillars:
- Reviewer calibration. You must ensure that your reviewers share an identical understanding of the project guidelines. To achieve this, run weekly alignment tests. Give all your reviewers the exact same pre-verified data batch to score. Calculate their statistical agreement scores using Cohen’s Kappa or Fleiss’ Kappa metrics. If a reviewer’s score strays from the team average, temporarily remove them from the production line for targeted retraining.
- Escalation structures. Avoid routing all data issues to a single help desk. Build a multi-tier support architecture instead. A tiered structure keeps your most expensive experts focused on the hardest problems, while the lower tiers handle the daily volume.
- Onboarding systems. When expanding your team to handle larger workloads, your onboarding process must be highly rigorous. New annotators should work inside a simulated sandbox environment before touching live customer data. The system should automatically compare their work against a pre-verified gold standard. Only grant access to the live production pipeline once a worker hits a 95% accuracy score over three consecutive test batches.
- Edge-case documentation. Keep a central, live encyclopedia for all your edge cases. When your workflows resolve a complex conflict, log the example in a shared digital document. Include clear visual examples showing the correct and incorrect ways to label the asset. This document serves as a single source of truth that reviewers can check before escalating an issue.
The Measurable Returns of Scale
Investing in robust, scalable QA systems yields immediate financial and operational benefits for enterprise AI companies:
- Reduced annotation inconsistency. Alignment rules keep your global teams unified, preventing data quality drops across different countries.
- Minimized rework. Catching labeling errors early prevents you from having to scrap and re-label entire data batches later.
- Lower retraining costs. Training a model on clean, consistent data means you spend less money on compute power trying to fix errors caused by bad labels.
- Eliminated delivery delays. Automated routing paths that are easy to see keep your data pipelines flowing smoothly so your projects ship on schedule.
Common Adjudication Mistakes That Damage AI Models

Building an enterprise data pipeline without strict quality control in data annotation introduces severe operational liabilities. If an operations team uses sloppy arbitration processes or makes poor choices during the resolution phase, those programmatic errors pass directly into the training partition. These structural failures corrupt downstream performance and degrade the reliability of deployed systems.
Critical Operational Errors in Review Management
Data operations managers frequently succumb to several common mistakes during the review and resolution phase:
- Escalating too many low-risk disagreements. When pipelines lack strict confidence thresholds, teams route minor, insignificant data disputes directly to senior engineering staff. This poor prioritization overwhelms expensive internal resources with basic tasks, leaving them with zero bandwidth to analyze high-risk edge cases.
- Inconsistent reviewer decisions. Without continuous alignment checks, different QA leads resolve identical data conflicts in opposite ways. This contradictory feedback introduces conflicting patterns directly into the training sets and confuses the primary labeling workforce.
- Weak calibration processes. Many companies onboard external vendors and assume their delivery metrics will stay accurate indefinitely. Without ongoing weekly checks, a team’s precision naturally drops over time, allowing thousands of bad labels to slip through unnoticed.
- Unresolved ontology conflicts. When data guidelines contain structural contradictions, annotators will constantly flag those items for review. If management simply resolves those individual tickets one by one without updating the master schema, the root confusion remains, causing workers to repeat the same mistakes.
- Poor edge-case governance. When a rare, complex data scenario occurs, teams often rush to make a quick choice just to clear the active queue. If they fail to document that decision in a central guide, other teams will label the same scenario differently later, destroying the dataset’s internal logic.
The Impact on Model Performance
When corrupted data passes through a weak review system, it degrades the performance of your deployed machine learning models in production:
- Model hallucinations. In generative AI and large language models, contradictory training data can confuse the system’s ability to predict tokens accurately. This confusion causes the model to generate false facts, invent citations, or enter infinite text loops.
- Inconsistent predictions. If computer vision training images contain messy bounding boxes, the model will struggle in real-world scenarios. It might correctly identify a vehicle in bright daylight but fail to see the exact same vehicle under streetlights due to poor edge alignment in the training set.
- Deployment reliability issues. If an AI model cannot deliver steady, predictable results, it becomes a liability. Enterprise clients will refuse to deploy or license a system that acts erratically during silent testing phases.
- Loss of enterprise trust. The financial and reputational damage of a failed AI deployment can be massive. If an automated customer service bot provides incorrect or toxic advice due to poor training data, it can damage customer relationships and lead to serious regulatory penalties.
Reliable Data Services Delivered By Experts
We help you scale faster by doing the data work right - the first time

The Accumulation of Hidden Business Costs
The financial impact of sloppy data management extends far beyond bad model performance. It triggers an expensive cycle of extra expenses that drains corporate budgets:
- Delayed releases. Fixing data errors late in the development cycle pushes back product launch dates by weeks or months, giving agile competitors a chance to capture market share.
- Dataset rebuilding. When a dataset is found to be systematically flawed, teams must take the entire repository offline, clean the schemas, and re-label thousands of assets from scratch.
- QA overhead. Operating without automated filters forces companies to hire extra layers of manual reviewers, skyrocketing the total cost per labeled asset.
- Retraining cycles. Running intensive training jobs on massive GPU clusters costs tens of thousands of dollars per run. Forcing multiple retraining runs because of poor annotation error reduction metrics burns through venture capital and department budgets.
Tinkogroup’s Approach to Annotation Adjudication and QA
Tinkogroup builds scalable human-in-the-loop systems and annotation adjudication workflows that eliminate dataset delays and poor quality control for US and European AI companies.
Optimized Production Pipeline
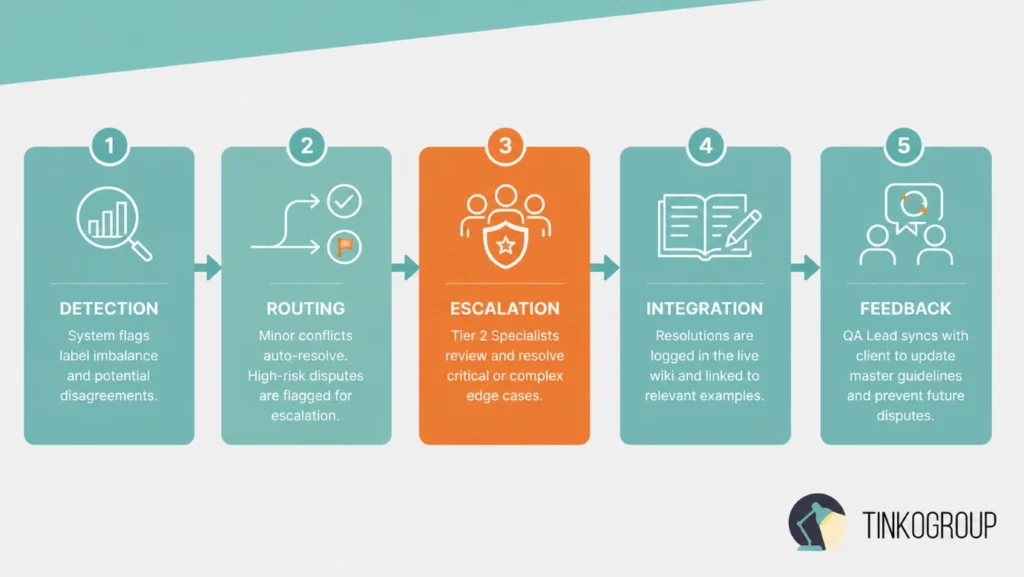
Tinkogroup handles data conflicts through an automated, risk-based medical text processing pipeline:
- Detection. The system monitors all actions and scores label imbalances.
- Routing. Minor conflicts auto-resolve; high-risk disputes are flagged.
- Escalation. Vetted Tier 2 specialists resolve critical edge cases manually.
- Integration. Resolutions are logged in a live wiki to update workers.
- Feedback. The QA Lead syncs with the client to update master guidelines.
Core Operational Strengths
The platform delivers reliable data annotation QA using five structural pillars:
- Dedicated teams. Long-term, specialized annotators instead of casual gig workers.
- HITL oversight. Blending automated tools with skilled human judgment.
- Continuous calibration. Weekly alignment checks tracking metrics like Fleiss’ Kappa.
- Enterprise scale. Workflows built to process millions of items without friction.
- Western compliance. Strict adherence to US and European data safety laws.
Conclusion
Building dependable, high-performing AI applications requires a strong focus on data quality. Enterprise teams cannot achieve excellent model performance by treating data collection as a casual afterthought. High-quality datasets require a structured approach to AI dataset validation, which means deploying intelligent systems that balance worker consistency, scalable review workflows, and fast delivery turnarounds.
Effective annotation adjudication is no longer optional for enterprise AI teams. It is a fundamental requirement for maintaining data quality, reducing rework, and accelerating model deployment.
Relying on weak review setups or simplistic majority voting leads to severe operational friction. It causes developer burnout, expensive model retraining cycles, and missed product launch dates. In today’s competitive AI market, these delays can seriously harm a business.
Optimize Your Data Operations
Do not let bad data workflows slow down your development team. Partner with an experienced team that understands how to manage complex data at scale.
Partner with Tinkogroup to eliminate QA bottlenecks, optimize your adjudication escalation workflows, and deliver the clean, consistent datasets your enterprise AI models require. Explore more capabilities at Tinkogroup’s data processing services.
What is annotation adjudication, and why is it important for AI training data?
Annotation adjudication is the process of resolving disagreements between annotators or reviewers when labeling data. It plays a critical role in maintaining dataset consistency, especially in complex AI projects involving natural language processing, computer vision, or content moderation. Without a structured adjudication process, conflicting labels can enter training datasets, reducing model accuracy and increasing the risk of unreliable predictions.
How can companies reduce annotation disagreements without slowing down production?
The most effective approach is not eliminating disagreements entirely but managing them efficiently. Organizations can reduce operational friction by using clear labeling guidelines, holding regular reviewer calibration sessions, keeping a centralized edge-case knowledge base, and applying risk-based escalation workflows. These practices help resolve high-impact conflicts quickly while avoiding unnecessary QA bottlenecks.
Can AI fully automate the annotation adjudication process?
No. While AI can assist by detecting inconsistencies, flagging high-risk disagreements, and prioritizing reviews, final adjudication decisions often require human judgment. Automated systems cannot fully capture complex edge cases, contextual interpretation, domain expertise, and evolving business requirements. The most reliable approach combines AI-driven efficiency with experienced human reviewers in a scalable human-in-the-loop workflow.


